Why Embedding Pipelines Break at Scale and How Lakehouse Architecture Fixes Them
Use Apache Iceberg to store embeddings as versioned datasets and treat the vector database as a derived retrieval index.
Join the DZone community and get the full member experience.
Join For FreeEmbedding pipelines often look deceptively simple.
Documents are chunked, embeddings are generated, vectors are stored in a vector database, and a retriever fetches relevant chunks for the LLM.
In prototypes, the system works beautifully.
Until production scale arrives.
A team deploys an internal knowledge assistant over 50,000 documents. The prototype performs well. Retrieval quality is strong and the architecture feels manageable.
Six months later the corpus grows to eight million documents. The embedding model provider releases a new version. A re-embedding pipeline is triggered. The job runs for hours and fails midway. Retrieval quality begins to drift, but no one can tell whether the cause is stale embeddings, inconsistent chunking, or a mismatch between source documents and stored vectors.
Compliance asks a simple question:
“Which document version was used to generate the embeddings behind this answer?”
The team cannot answer.
At that moment, the problem is no longer the LLM. It is the architecture around the embeddings.
It is no longer even the vector database.
The problem is the architecture around the embedding.
Embedding pipelines often treat vectors as disposable artifacts rather than governed data assets. That approach works for prototypes but begins to break once the corpus grows, models evolve, and operational requirements increase.
This article explores why embedding pipelines fail at scale and proposes a practical solution: manage embeddings inside the lakehouse as versioned data assets while treating the vector database as a derived serving index rather than the system of record.
The Standard Embedding Pipeline
Most RAG implementations follow a familiar architecture.
The architecture used in many early deployments is illustrated in Figure 1.

Figure 1. Standard RAG architecture where documents are embedded and stored in a vector database for similarity search before retrieval by an LLM.
Documents are chunked and cleaned. Each chunk is converted into a vector representation using an embedding model such as OpenAI embeddings, Amazon Titan, or a SentenceTransformer model. The vectors are stored in a vector database that supports approximate nearest neighbor search. At query time, the retriever identifies the most relevant vectors and supplies the corresponding text chunks to the LLM.
For small corpora this architecture is elegant and effective.
The problems appear when the system grows.
Where Embedding Pipelines Break at Scale
Embedding infrastructure introduces challenges that are often invisible during early experimentation.
Full Re-Embedding Becomes Expensive
Embedding models change frequently. Providers release new versions, teams switch models for quality improvements, or chunking strategies evolve.
When that happens, many pipelines only know one approach:
Recompute everything.
For small datasets this is manageable. For millions of documents it becomes expensive and operationally disruptive.
Without version awareness and source tracking, teams often cannot identify which documents actually need to be re-embedded.
The result is unnecessary recomputation.
Embeddings Lack Lineage
Vector databases store vectors extremely efficiently, but they usually do not capture the full lifecycle context around each embedding.
Important questions become difficult to answer:
- Which model generated this embedding?
- Which document version produced it?
- What chunking strategy was used?
- When was the embedding created?
Without that information, debugging retrieval quality becomes guesswork.
Vector Indexes Become Operationally Fragile
Indexes require maintenance.
New documents arrive, embeddings change, and index settings evolve.
At scale, index rebuilds can take hours. Partial failures can leave the index inconsistent. Recovery often requires rebuilding the index or recomputing embeddings.
The underlying issue is architectural coupling: the serving layer is also acting as the storage layer.
No Rollback or Time Travel
Traditional data systems allow snapshot rollback and historical analysis.
Embedding pipelines frequently lack these capabilities.
If a bad embedding batch enters the system, reverting to yesterday’s state may require regenerating the entire corpus.
For production AI systems, that limitation becomes painful.
Embeddings Are Data Assets
Embedding pipelines behave much more like data pipelines than many teams realize.
They ingest source documents, transform them through preprocessing and chunking, generate derived outputs, store those outputs, and serve downstream consumers.
That workflow mirrors traditional ETL pipelines.
If embeddings behave like data, they should be managed like data.
They need versioning, lineage, rollback capability, schema evolution, and governance.
Modern lakehouse architectures already provide these capabilities.
Instead of building custom lifecycle logic around vector stores alone, we can reuse those mature patterns.
A Lakehouse Architecture for Embeddings
The key architectural change is simple.
Store embeddings in the lakehouse as the system of record.
Use the vector database only as a serving index.
A more robust architecture separates embedding storage from the serving index, as shown in Figure 2.
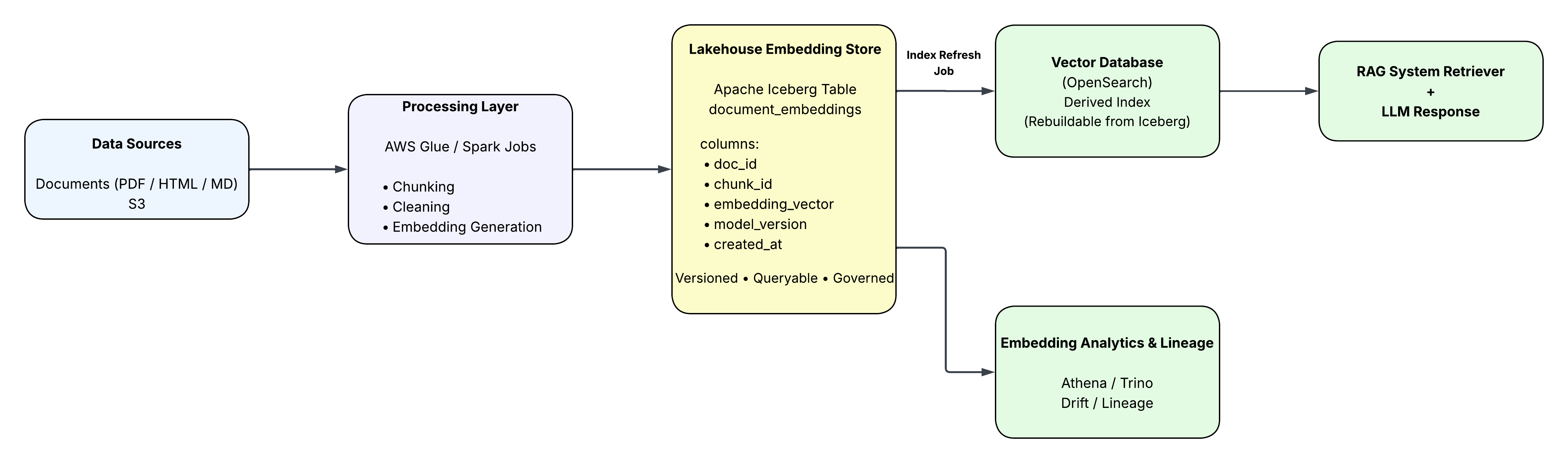
Figure 2. Lakehouse-based embedding architecture where embeddings are stored as governed data assets in Apache Iceberg. The vector database functions as a derived retrieval index, while SQL analytics tools such as Athena or Trino enable lineage tracking, monitoring, and drift analysis.
In this architecture:
- embeddings live in Apache Iceberg tables on S3
- metadata is stored alongside vectors
- vector indexes are built from the Iceberg dataset
- SQL analytics tools can analyze embedding metadata
This separation simplifies operations significantly.
Defining an Iceberg Table for Embeddings
Embeddings can be stored in a versioned Iceberg table with rich metadata.
CREATE TABLE glue_catalog.embeddings_db.document_embeddings (
doc_id STRING,
chunk_id STRING,
chunk_text STRING,
embedding ARRAY<FLOAT>,
embedding_dim INT,
model_name STRING,
model_version STRING,
chunking_strategy STRING,
source_snapshot STRING,
created_at TIMESTAMP,
batch_id STRING
)
USING iceberg
PARTITIONED BY (model_version, days(created_at));This schema captures the context that most pipelines lose.
Each embedding row now records the model version, the document snapshot that produced it, and the batch job responsible for generating it.
Embeddings become traceable assets rather than opaque vectors.
Incremental Embedding Generation with Spark
The next step is generating embeddings only for documents that actually changed.
Below is a simplified PySpark workflow.
from pyspark.sql.functions import col, explode, sha2, concat_ws
from pyspark.sql.types import ArrayType, StringType
from pyspark.sql.functions import udf
def chunk_text(text):
words = text.split()
chunk_size = 200
overlap = 40
step = chunk_size - overlap
chunks = []
for i in range(0, len(words), step):
chunk = " ".join(words[i:i + chunk_size])
if chunk:
chunks.append(chunk)
return chunks
chunk_udf = udf(chunk_text, ArrayType(StringType()))
source_df = spark.read.format("iceberg").load(
"glue_catalog.docs_db.source_documents"
)
existing_df = (
spark.read.format("iceberg")
.load("glue_catalog.embeddings_db.document_embeddings")
.filter(col("model_version") == "v2.1")
.select("doc_id")
.distinct()
)
new_docs = source_df.join(existing_df, "doc_id", "left_anti")
chunked_df = (
new_docs
.withColumn("chunk_array", chunk_udf(col("document_text")))
.withColumn("chunk_text", explode(col("chunk_array")))
.withColumn(
"chunk_id",
sha2(concat_ws("||", col("doc_id"), col("chunk_text")), 256)
)
)This workflow identifies only documents that have not yet been embedded for the current model version.
Instead of re-embedding the entire corpus, the pipeline processes only the incremental changes.
Writing Embeddings Back to Iceberg
After embeddings are generated, they are written back into the Iceberg table.
from pyspark.sql.functions import current_timestamp
embeddings_df = chunked_df.withColumn(
"embedding",
generate_embedding_vector(col("chunk_text"))
).withColumn(
"model_version", lit("v2.1")
).withColumn(
"created_at", current_timestamp()
)
(
embeddings_df.writeTo(
"glue_catalog.embeddings_db.document_embeddings"
)
.append()
)The table snapshot automatically records the batch commit.
This enables rollback and historical comparison later.
Vector Database as a Derived Index
Once embeddings are stored in Iceberg, the vector database becomes a serving layer rather than a storage system.
This relationship is illustrated conceptually in Figure 3.
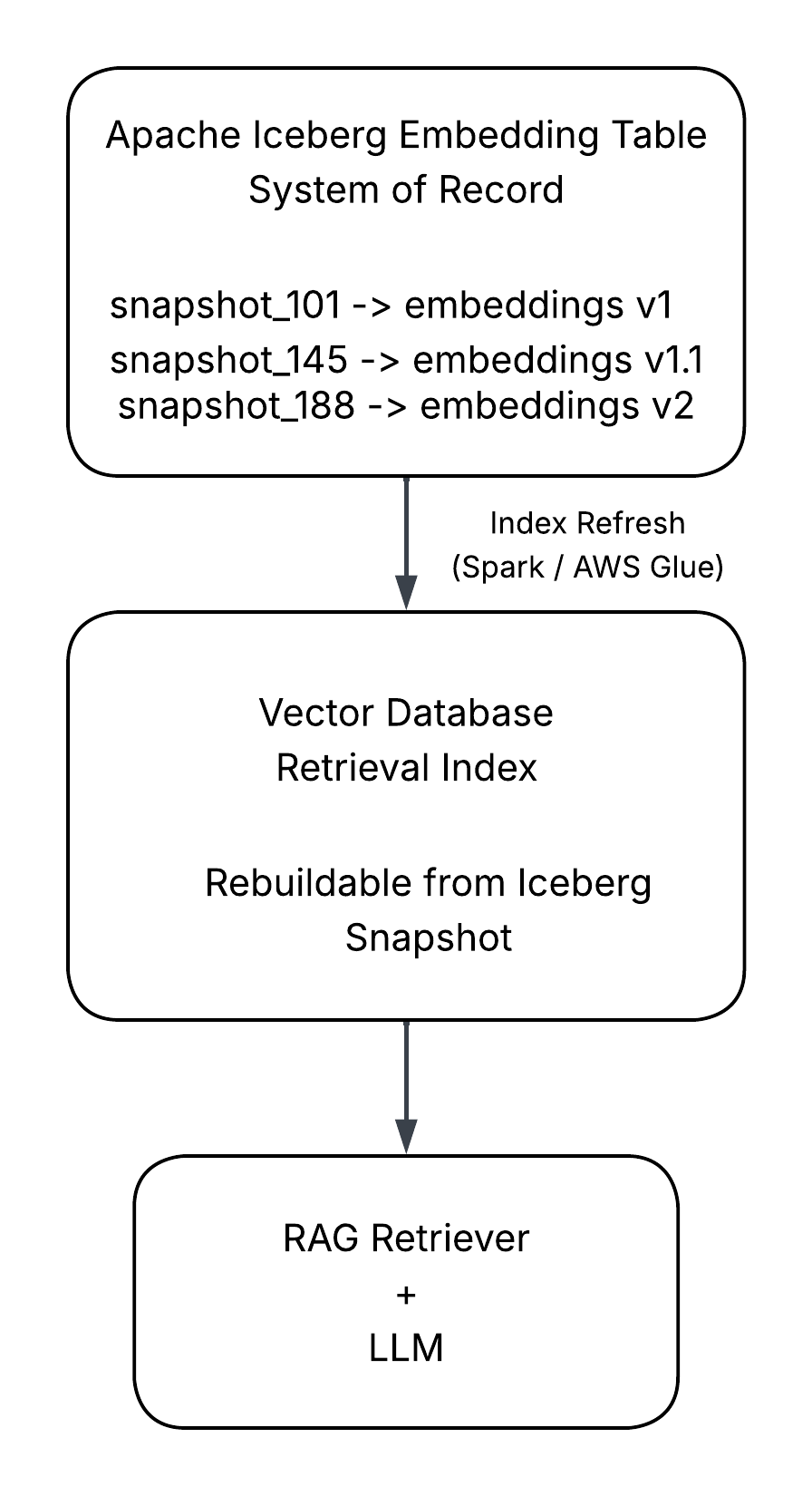
Figure 3. Embedding lifecycle with Apache Iceberg as the system of record. Embeddings are versioned through Iceberg snapshots, while the vector database operates as a rebuildable retrieval index populated through periodic index refresh jobs.
If the index becomes stale or corrupted, it can be rebuilt directly from the Iceberg dataset.
No re-embedding is required.
SQL Observability for Embedding Pipelines
Because embeddings now live in the lakehouse, operational analysis becomes easier.
For example, teams can track embedding counts by model version.
SELECT
model_version,
COUNT(*) AS embedding_count
FROM glue_catalog.embeddings_db.document_embeddings
GROUP BY model_version;They can also inspect which document snapshots produced embeddings.
SELECT
source_snapshot,
COUNT(DISTINCT doc_id) AS documents_embedded
FROM glue_catalog.embeddings_db.document_embeddings
GROUP BY source_snapshot;Once embeddings are treated as queryable data assets, debugging and governance become far easier.
When Not to Use This Architecture
This approach is most useful when the embedding corpus is large and operational complexity matters.
For small prototypes or experiments with a few thousand documents, storing vectors directly in a vector database may be sufficient.
Similarly, if your application relies primarily on real-time query embeddings rather than large corpus embeddings, the lakehouse layer may provide limited value.
The lakehouse approach becomes most valuable once the corpus reaches millions of documents or when governance and lifecycle management become critical.
Conclusion
Embedding pipelines often fail for the same reason early data systems failed.
They were built for the happy path.
At prototype scale, storing vectors directly in a vector database works well. At production scale, the lack of versioning, lineage, and rollback begins to create operational friction.
The solution is not to abandon vector databases.
It is to place them in the correct architectural role.
Use the vector database for what it does best: low-latency retrieval.
Use the lakehouse for what it does best: storing, versioning, and governing important data assets.
When embeddings are managed inside the lakehouse as versioned datasets rather than disposable artifacts, AI pipelines become more reproducible, easier to debug, and far more scalable.
Key Takeaways
- Embedding pipelines behave like data pipelines and should be managed with the same discipline.
- Apache Iceberg enables versioned, lineage-aware embedding storage.
- Vector databases should be treated as derived serving indexes rather than systems of record.
- Incremental re-embedding significantly reduces operational cost.
- Lakehouse storage makes rollback, governance, and observability possible.
Opinions expressed by DZone contributors are their own.
Comments