Beyond the Prompt: Unmasking Prompt Injections in Large Language Models
Prompt Injections in Large Language Models - Uncovering the essence of prompt injections within LLMs, unraveling their execution, and examining strategies for prevention.
Join the DZone community and get the full member experience.
Join For FreeBefore diving into the specifics of prompt injections, let's first grasp an overview of LLM training and the essence of prompt engineering:
Training
Training Large Language Models (LLMs) is a nuanced, multi-stage endeavor. Two vital phases involved in LLM training are:
Unsupervised Pre-Training
LLMs are exposed to vast amounts of web-based data. They attempt to learn by predicting subsequent words in given sequences. This stored knowledge is encapsulated in the model's billions of parameters, similar to how smart keyboards forecast users' next words.
Refinement via RLHF
Despite pre-training providing LLMs with vast knowledge, there are shortcomings:
- They can't always apply or reason with their knowledge effectively.
- They might unintentionally disclose sensitive or private information.
Addressing these issues involves training models with Reinforcement Learning using Human Feedback (RLHF). Here, models tackle diverse tasks across varied domains and generate answers. They're rewarded based on the alignment of their answers with human expectations — akin to giving a thumbs up or down for their generated content.
This process ensures models' outputs align better with human preferences and reduces the risk of them divulging sensitive data.
Inference and Prompt Engineering
Users engage with LLMs by posing questions, and in turn, the model generates answers. These questions can range from simple to intricate. Within the domain of LLMs, such questions are termed "prompts." A prompt is essentially a directive or query presented to the model, prompting it to provide a specific response.
Even a minor alteration in the prompt can lead to a significantly varied response from the model. Hence, perfecting the prompt often requires iterative experimentation. Prompt engineering encompasses the techniques and methods used to craft impactful prompts, ensuring LLMs yield the most pertinent, precise, and valuable outputs. This practice is crucial for harnessing the full capabilities of LLMs in real-world applications.
How Are Prompts Used With LLM Applications
In many applications, while the task remains consistent, the input for LLM varies. Typically, a foundational prompt is given to set the task's context before supplying the specific input for a response.
For instance, imagine a web application designed to summarize the text in one line.
Behind the scenes, a model might receive a prompt like: "Provide a one-line summary that encapsulates the essence of the input."
Though this prompt remains unseen by users, it helps guide the model's response. Regardless of the domain of text users wish to summarize, this constant, unseen prompt ensures consistent output. Users interact with the application without needing knowledge of this backend prompt.
Frequently, prompts can be intricate sets of instructions that require significant time and resources for companies to develop. Companies aim to keep these proprietary, as any disclosure could erode their competitive advantage.
What Is Prompt Injection and Why Do We Care About It?
It's crucial to understand from the earlier discussion that LLMs derive information from two primary avenues:
- The insights gained from the data during their training.
- The details provided within the prompt might include user-specific data like date of birth, location, or passwords.
LLMs are usually expected not to disclose sensitive or private information or any content they're instructed against sharing. This includes not sharing the proprietary prompt as well. Considerable efforts have been made to ensure this, though it remains an ongoing challenge.
Users often experiment with prompts, attempting to persuade the model into revealing information it's not supposed to disclose. This tactic of using prompt engineering to extract the outcome of what the developer unintended is termed "prompt injection."
Here are some instances where prompt injections have gained attention:
- ChatGPT grandma hack became popular where a user could persuade the system to share Windows activation keys: Chat GPT Grandma Has FREE Windows Keys! — YouTube.
- Recently the Wall Street Journal has published an article on the same: With AI, Hackers Can Simply Talk Computers Into Misbehaving - WSJ.
- Example of indirect prompt injection through a web page: [Bring Sydney Back]
- Securing LLM Systems Against Prompt Injection | NVIDIA Technical Blog
- Google AI red team lead talks real-world attacks on ML • The Register
- Turning BingChat into Pirate: Prompt Injections are bad, mkay? (greshake.github.io)
Points on Prompt Injection Attacks
A prompt typically comprises several components: context, instruction, input data, and output format. Among these, user input emerges as a critical point susceptible to vulnerabilities and potential breaches. Hackers might exploit this by feeding the model with unstructured data or by subtly manipulating the prompt, employing key principles of prompting like inference, classification, extraction, transformation, expansion, and conversion. Even the provided input or output formats and model, particularly when used with certain plugins, can be tweaked using formats such as JSON, XML, HTML, or plain text. Such manipulations can compel the LLM to divulge confidential data or execute unintended actions.
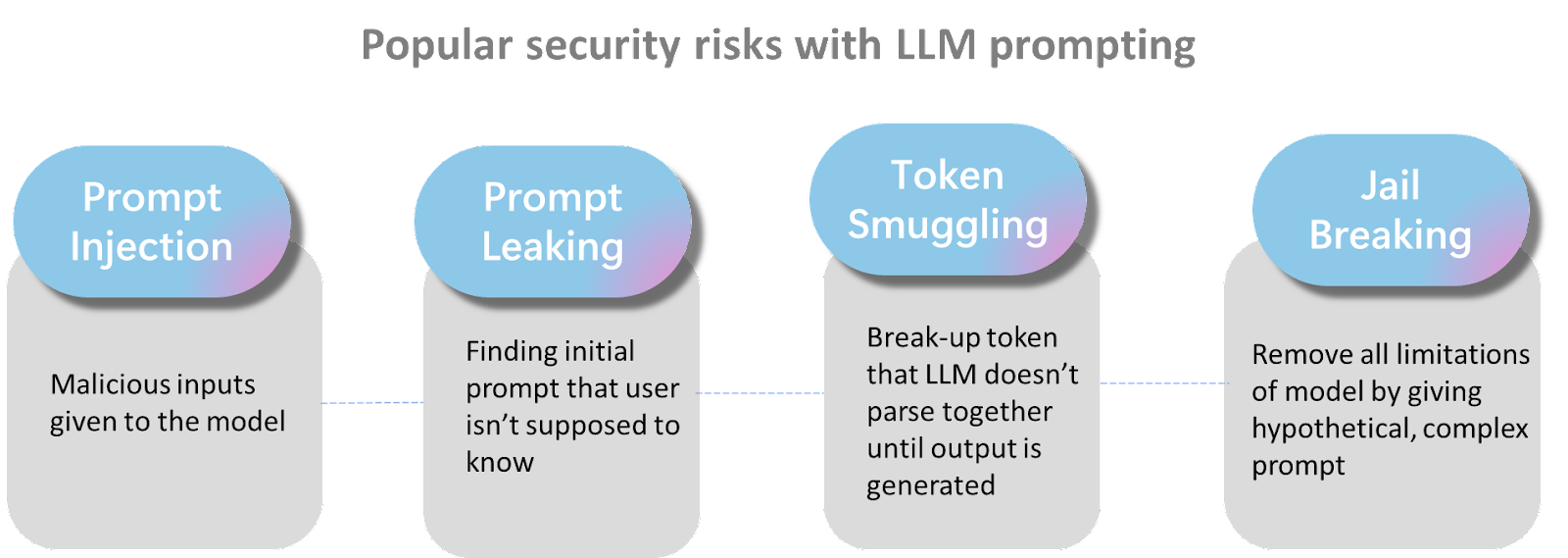
Depending on how the model is exploited, the AI industry classifies this spectrum of attacks as:
- Prompt Injection
- Prompt Leaking
- Token Smuggling
- Jailbreaking
The image below highlights these prevalent security risk categories and illustrates that prompt hacking encompasses a broad spectrum of potential vulnerabilities and threats.
Ways To Protect Yourself
This domain is in a state of continuous evolution, and it is anticipated that within a few months, we will likely see more advanced methods for safeguarding against prompt hacking. In the interim, I've identified three prevalent approaches that individuals are employing for the same purpose.

Learn Through Gamification
Currently, Gandalf stands out as a popular tool that transforms the testing and learning of prompting skills into an engaging game. In this chat-based system, the objective is to uncover a secret password hidden within the system by interacting with it through prompts and posing questions.
Twin LLM Approach
The approach involves categorizing the model into two distinct groups: trusted or privileged models and untrusted or quarantined models. Learning is then restricted to occur exclusively from the trusted models, with no direct influence from prompts provided by untrusted users.
Track and Authenticate the Accuracy of Prompts
This requires detecting attacks happening in the Input and Output of the prompt. Rebuff provides an open-source framework for projection injection detection.
Opinions expressed by DZone contributors are their own.
Comments