Databricks vs Snowflake: Complete Architecture Mapping for Enterprise AI and Big Data
This guide maps core data, big data, and AI/ML concepts between Databricks and Snowflake, with examples, diagrams, and a framework for choosing or combining the two.
Join the DZone community and get the full member experience.
Join For FreeAs data ecosystems continue to evolve in the multi-cloud environment, organizations are increasingly blending platforms to optimize for specific workloads. A common pain point I've experienced is when architecting enterprise data solutions: terminology can often be a barrier. How do core concepts in Databricks translate to Snowflake? It's not just about semantics; rather, it's about building resilient and governed architectures across platforms without reinventing the wheel.
In this article, I'll go beyond surface-level comparisons, exploring design patterns and illustrating flows and structures. Whether you're a data architect migrating workloads or a leader fostering cross-team collaboration, this mapping puts the emphasis on governance, domain-driven design, and data products, rather than vendor lock-in. Think of it as a blueprint for hybrid operations that supports multi-platform models.
Why does this matter? With AI-driven analytics demanding seamless integration across lakes and warehouses, a shared vocabulary enables:
- Unified language for architects, engineers, and stakeholders.
- Hybrid flexibility in multi-cloud setups, reducing silos.
- Consistent governance practices, such as RBAC and lineage tracking.
Here is a core mapping table based on recent evolutions of the platforms. This builds on standard alignments but includes recent updates such as Snowflake's improved Iceberg support, Databricks' Lakebase for OLTP workloads, and improvements in AI integrations like the inclusion of Mosaic AI agents at Databricks and Cortex ML functions in Snowflake.
| Databricks Concept | Snowflake Equivalent | Key Notes on Translation |
|---|---|---|
| Job Cluster | Ephemeral Virtual Warehouse | On-demand compute for batch jobs; scales elastically, but Snowflake auto-suspends idle resources more aggressively. |
| Shared/All-Purpose Cluster | Shared Multi-Cluster Warehouse | Elastic for interactive/BI; Databricks allows multi-language (Python/SQL), Snowflake optimizes for SQL concurrency. |
| Delta Lake | Snowflake Tables or Iceberg Tables on External Volumes | ACID storage layer; Snowflake's micro-partitions mimic Delta's optimization, with Iceberg for open interoperability. |
| Auto Loader | External Stage + Snowpipe / Snowpipe Streaming | Automated ingestion; Databricks handles schema inference natively, Snowflake excels in low-latency streaming. |
| Delta Live Tables (DLT) | Dynamic Tables (incremental pipeline framework) | Streamlined pipelines; both support declarative ETL with monitoring. |
| Workflows / Jobs | Tasks + Stored Procedures (or external tools like Airflow) | Orchestration; Databricks integrates notebooks seamlessly, Snowflake favors SQL-centric scheduling. |
| Unity Catalog | RBAC + Object Tags / Policies | Metadata governance; Unity's federation spans external sources, akin to Snowflake's Horizon Catalog. |
| Secret Scopes | Storage Integrations (IAM-based) | Secure credential management; both tie into cloud IAM for least-privilege access. |
| Apache Spark (Big Data Processing) | Snowflake Query Engine / Unstructured Data Support | Distributed compute; Spark for custom Big Data ETL/ML, Snowflake for SQL-optimized scans on massive structured/unstructured data. |
| Structured Streaming (Big Data) | Snowpipe Streaming / Kafka Connectors | Real-time pipelines; Databricks handles stateful ops natively, Snowflake integrates via connectors for high-throughput ingestion. |
| Mosaic AI / MLflow (AI/ML) | Cortex AI / Snowpark ML | End-to-end ML; Databricks for agentic AI and governance, Snowflake for serverless inference, and Python ML in SQL. |
| Model Registry (AI) | Snowflake Model Registry | Versioning models; Unity Catalog governs deployments, Snowflake ties into Cortex for easy serving. |
| Vector Search (AI) | Cortex Search Services | Embeddings retrieval; Databricks optimizes for lakehouse vectors, Snowflake for hybrid search in warehouses. |
The above table isn't exhaustive; platforms are constantly changing: Databricks has added warehouse-like querying via Photon, while Snowflake has embraced open formats such as Parquet and Iceberg in support of lakehouse-style flexibility. Now let's break it down, with examples and diagrams.
Compute Models: Scaling Workloads Efficiently
Compute is the heartbeat of any data platform, and the translation between Databricks' clusters and Snowflake's warehouses is straightforward but nuanced. Databricks clusters are Spark-based, offering granular control for diverse workloads (e.g., ML training with GPUs), while Snowflake's warehouses are SQL-optimized with automatic scaling for concurrency.
Example scenario: Imagine processing a 10TB dataset for fraud detection.
In Databricks, you'd spin up a Job Cluster for batch ETL in Python/Spark, autoscaling from 4 to 16 nodes based on load.
In Snowflake, an Ephemeral Virtual Warehouse handles the same via SQL queries, auto-suspending after 60 seconds of idle time to cut costs.
Here's a diagram comparing the compute attachment to storage. Box shapes for compute nodes and ellipses for storage, arrows indicating data flow. Databricks and Snowflake are distinguished by separate labeled clusters with different borders.
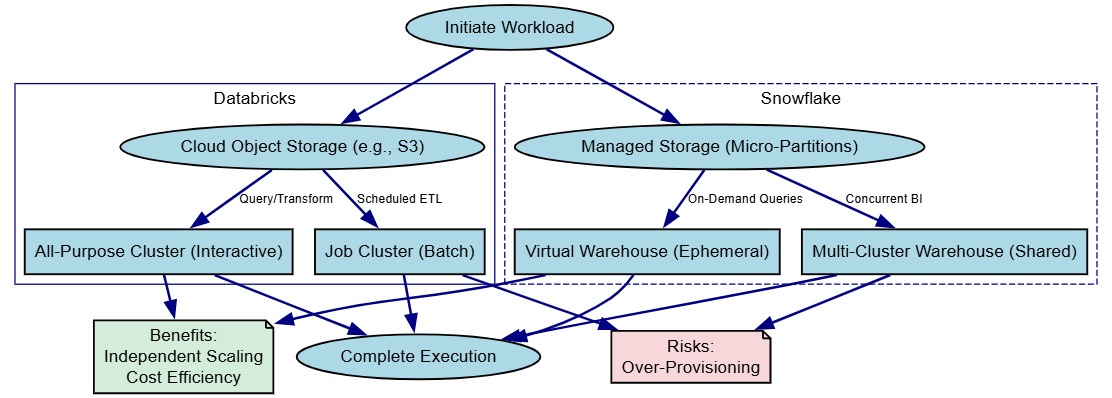
This diagram highlights the decoupling: arrows show independent scaling, a core pattern for cost efficiency in hybrid setups.
Storage and Table Management: From Lakes to Warehouses
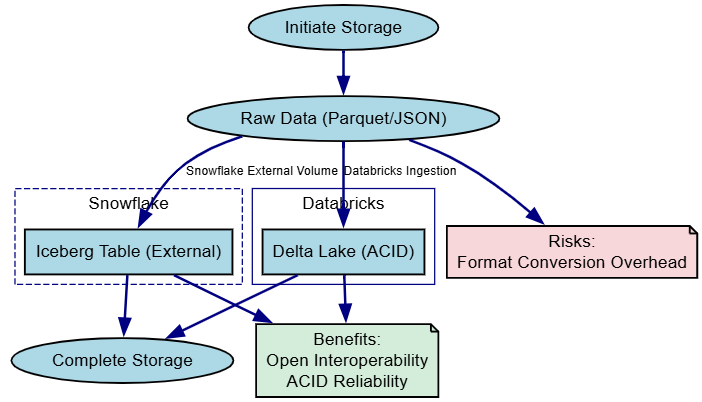
Delta Lake in Databricks brings reliability to data lakes with ACID transactions, time travel, and schema evolution, while Snowflake's tables, which use micro-partitions for pruning and compression, or Iceberg for external open storage.
Example scenario: Building a customer 360 view. In Databricks, create a Delta Table with:
CREATE TABLE customer_360 USING DELTA AS SELECT * FROM raw_data;
-- Time travel example
SELECT * FROM customer_360 VERSION AS OF 5;In Snowflake, use dynamic tables for incremental updates:
CREATE DYNAMIC TABLE customer_360 TARGET_LAG = '1 hour' AS SELECT * FROM raw_stream;
-- Query with cloning for zero-copy
CREATE TABLE snapshot CLONE customer_360;Both enable governance via catalogs: Unity Catalog tags sensitive columns, mirroring Snowflake's Object Tags for PII policies.
Here's a layered diagram for storage flow:
Ingestion Pipelines: Auto Loader vs. Snowpipe
Ingestion is where real-time meets batch. Databricks' Auto Loader detects new files and infers schemas automatically, while Snowflake's Snowpipe triggers loads from stages, with streaming for low-latency.
Example scenario: Streaming IoT data from S3. Databricks code:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("IoTStream").getOrCreate()
df = spark.readStream.format("cloudFiles") \
.option("cloudFiles.format", "json") \
.load("s3://iot-bucket/")
df.writeStream.format("delta").start("delta/iot_table")Snowflake equivalent:
CREATE STAGE iot_stage URL='s3://iot-bucket/';
CREATE PIPE iot_pipe AUTO_INGEST=TRUE AS COPY INTO iot_table FROM @iot_stage;
-- Streaming variant
CREATE STREAM iot_stream ON TABLE raw_iot;Here's a layered diagram for the ingestion process:
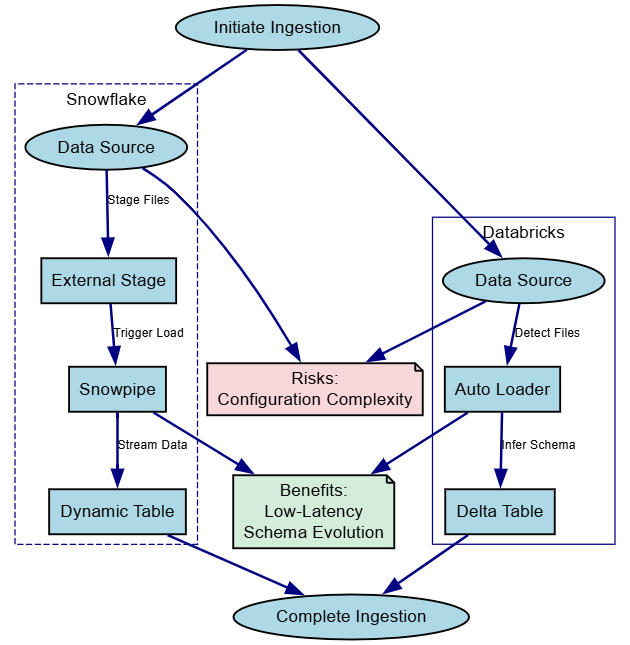
This clustered view emphasizes parallel patterns, ideal for domain-owned pipelines.
Big Data Processing: Handling Massive Scale
Databricks leverages Apache Spark for custom Big Data transformations, ideal for ETL on unstructured sources. Snowflake's engine shines in querying vast structured datasets without ETL overhead.
Example scenario: Joining 100TB datasets.
Databricks Spark (we can also use SQLs for the below after creating tables):
df1 = spark.read.parquet("s3://dataset1/")
df2 = spark.read.parquet("s3://dataset2/")
joined = df1.join(df2, "id").cache()Snowflake:
SELECT * FROM dataset1 JOIN dataset2 USING (id);Here's a diagram for the processing graph:
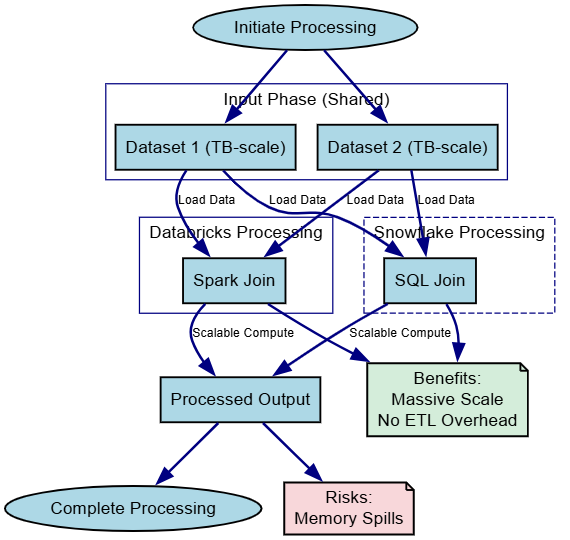
This shared pattern scales big data across both.
AI and ML Workloads: Enabling Intelligent Insights
Databricks' Mosaic AI builds agentic systems with MLflow for tracking, while Snowflake's Cortex offers serverless AI functions and Snowpark for Python ML.
Example scenario: Training a sentiment model. Databricks MLflow:
import mlflow
with mlflow.start_run():
model = train_model(data)
mlflow.log_model(model, "sentiment")Snowflake Snowpark:
from snowflake.ml.modeling import LinearRegression
session = Session.builder.configs(conn).create()
df = session.table("reviews")
model = LinearRegression().fit(df)
session.write_pandas(model.predict(new_data), "predictions")Here's a diagram for the AI workflow:
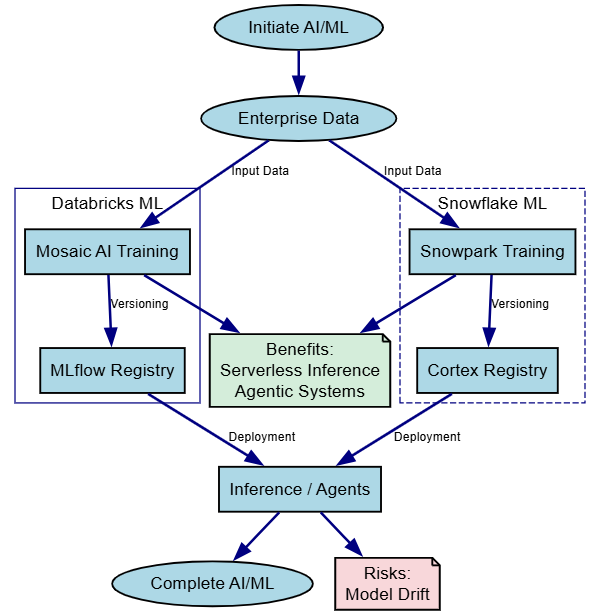
Arrows show governed AI pipelines, with Databricks emphasizing agents and Snowflake quick inference.
Orchestration and Governance: Tying Big Data and AI
Workflows orchestrate Big Data jobs into AI pipelines, with Unity Catalog governing models like Snowflake's RBAC for Cortex.
Example scenario: AI pipeline orchestration. Databricks Workflow with ML:
tasks:
- task_key: IngestBigData
job_cluster_key: big_cluster
- task_key: TrainAI
depends_on: [IngestBigData]
notebook_task: {path: "/ml_train"}Snowflake tasks with Snowpark:
CREATE TASK ingest_task SCHEDULE = '5 MINUTE' AS CALL ingest_proc();
CREATE TASK train_task PREDECESSOR = ingest_task AS CALL train_model();Here's a diagram for orchestrated dependencies:
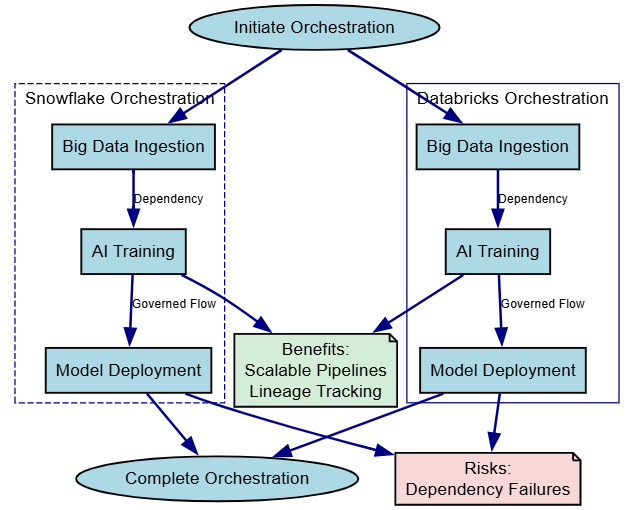
This ensures scalable, governed big data-to-AI flows.
That is a great request. When rewriting technical comparisons for a publication like DZone, the goal is often to use clearer, more engaging language that speaks directly to the reader's challenges while maintaining technical accuracy.
Choosing Your Data Platform: AI Engine vs. Analytic Powerhouse
When looking at the modern data landscape, organizations often find themselves weighing up two giants: Databricks and Snowflake. While both platforms perform exceptionally well in hybrid environments, the final choice truly hinges on where your team’s workload priorities lie.
The Databricks Difference
If your team is fundamentally engineering-heavy and your operations demand an AI-first approach, Databricks is generally the better fit.
Databricks excels in scenarios requiring deep integration between big data processing and complex artificial intelligence/machine learning (AI/ML) workflows. This is because it is built on Apache Spark and includes powerful Mosaic AI tools. This combination makes it ideal for handling complex, data-intensive, polyglot environments, where teams need to continuously iterate on models at scale.
Custom Workloads
Databricks shines in tasks like custom ETL (Extract, Transform, Load), advanced analytics, and powering sophisticated agentic AI systems.
Real-World Application
In financial services, banks rely on Databricks to process petabytes of transaction data, using embedded AI for crucial tasks like fraud detection within live trading dashboard pipelines. It also powers credit risk assessment. Furthermore, retailers use Databricks to drastically reduce inventory costs by running predictive analytics on vast unstructured datasets, optimizing their supply chains through real-time ML models for demand forecasting.
For sectors like tech and healthcare, especially those dealing with complex tasks such as genomic AI, Databricks is the clear choice.
The Snowflake Sweet Spot: BI and Compliant Reporting
Conversely, Snowflake is the preferred platform when your primary focus is on SQL-centric business intelligence (BI) and standard analytics workloads. If your operations are primarily BI-focused and SQL-driven, Snowflake provides unmatched advantages.
Snowflake’s strength lies in its architecture, which features a fundamental separation of storage and compute. This design enables highly cost-effective scaling to support many concurrent users without demanding heavy engineering overhead.
Operational Focus
It is known as a go-to platform for industries focused on reporting and visualization, excelling at data consolidation from diverse source systems and offering robust serverless operations.
Real-World Application
Consider the manufacturing sector, where firms integrate sensor data from production lines directly with ERP systems. They use this consolidated view for predictive maintenance, preventing equipment failures and minimizing costly downtime. Snowflake’s "micro-partitioning" feature is particularly adept here, ensuring lightning-fast queries when dealing with structured data. In retail, businesses leverage Snowflake to unify e-commerce, in-store transactions, and loyalty program data, driving personalized marketing campaigns without complex custom ETL setups.
Snowflake is typically the platform of choice for departments like finance and government that require efficient, compliant reporting.
The Deciding Factor
Ultimately, the decision rests on the core mission of your team: Databricks is geared toward teams building sophisticated, engineering-heavy, AI models, while Snowflake is optimized for SQL-driven data operations, reporting, and mass concurrency. Often, the optimal outcome involves adopting hybrid approaches, which allow organizations to leverage the specific strengths of each platform across different workloads.
Wrapping Up: Architecting for Big Data and AI
Databricks: The AI Engineering Engine
Choose Databricks if your team is AI-first and engineering-heavy. Built on Apache Spark and featuring Mosaic AI tools, it's optimized for deep AI/ML integration in data-intensive, polygot environments.
- Best for: Complex tasks like custom ETL, advanced analytics, and sophisticated agentic AI systems.
- Proof: Banks use it to process petabytes of transaction data for fraud detection. Retailers leverage real-time ML models to reduce inventory costs. It's essential for sectors like tech and healthcare to tackle genomic AI.
Snowflake: The Scalable BI Powerhouse
Go with Snowflake when your core need is SQL-centric BI and analytics and compliant reporting. Its unique separation of storage and compute allows for cost-effective scaling to handle many concurrent users without heavy engineering overhead.
- Best for: Data consolidation, serverless operations, and fast queries on structured data.
- Proof: Manufacturers use it for predictive maintenance via integrated sensor data. It consolidates e-commerce and loyalty data for unified customer insights.
It's the platform of choice for BI-focused, SQL-driven operations in finance and government.
The bottom line: Don't pick a winner; pick the right tool for the job. Hybrid approaches often yield the best results, matching Databricks' engineering power to AI tasks and Snowflake's efficiency to reporting needs.
Opinions expressed by DZone contributors are their own.
Comments