Is the Data Warehouse Dead? 3 Patterns From Enterprise Architecture That Answer This Question
No, but its role has fundamentally changed. Here is what I have seen work, after building data platforms at enterprise scale across multiple industries.
Join the DZone community and get the full member experience.
Join For FreeArchitectural Debate
There is a classic debate that data architects often have among themselves: how to fit a traditional data warehouse on a data lake or enterprise data platform. This article walks through the architecture evolution and describes three architecture patterns that I have implemented across enterprises to help you decide where a data warehouse fits in a modern data platform.
The data warehouse acted as a single source of truth that finance, retail, and operations teams could trust for day-to-day reporting. Appliance warehouses like Teradata, Netezza, and SybaseIQ dominated enterprise data for decades, and SQL was the universal language that held it all together.
Then two things happened simultaneously. Data volumes outgrew what any single warehouse could handle, and cloud storage made storing everything cheaper. This created a genuine architectural dilemma that most organizations have not resolved cleanly (yet).
The most common mistake I have seen is the “one size fits all” approach, where workloads are mixed together without considering the purpose or usage, based on people and “rigid” processes. This creates a cost overhead over time and significantly limits the ability to get real value from the data.
After implementing data platforms at companies, including a large US beverage manufacturer, a global media company, and as part of the AWS data architecture practices, I have seen three distinct patterns emerge. Each has a legitimate use case. Each has a failure mode that is entirely predictable, and yet organizations keep hitting it.
Context: What the Warehouse Was Actually Good At
Before evaluating patterns, it helps to be precise about what warehouses solved:
- Transformations. CDC from transactional sources, slowly changing dimensions(SCD), and fact aggregation. These are the use cases that SQL warehouses solved reliably, either with SQL and/or by ETL tooling.
- Reporting. Pre-computed, governed, low-latency access for drill-down/roll-up, and summarization.
Data lakes historically struggled with both. ACID compliance was unreliable, and complex transformations required significant engineering. Open table formats like Apache Iceberg, Apache Hudi, and Delta Lake changed this equation by bringing warehouse comparable reliability to object storage. That shift is what makes the three patterns below possible.
Pattern 1: Data Warehouse as the Enterprise Data Platform
Best for: BI-heavy organizations, mature SQL teams
Data flow:
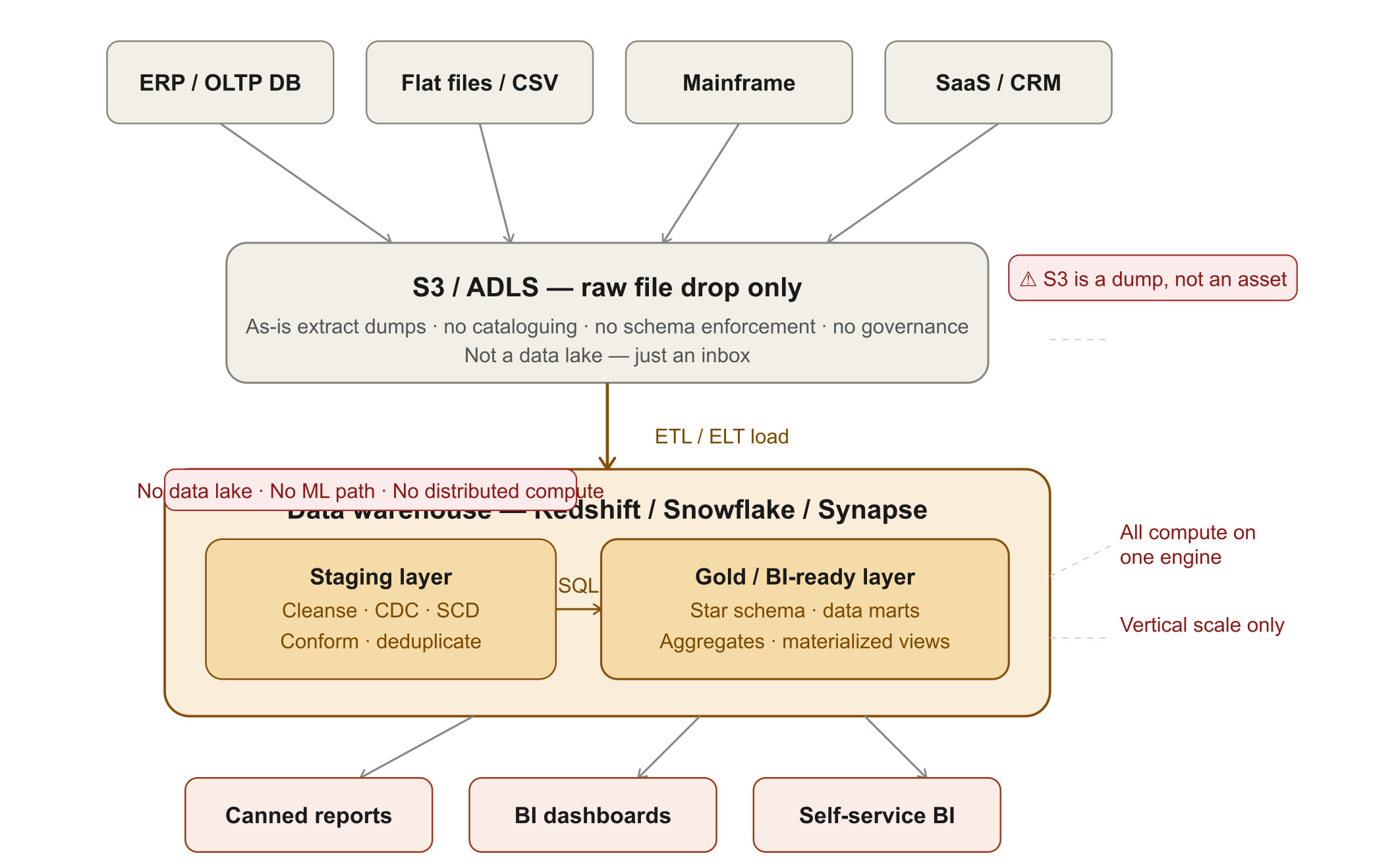
I have observed this pattern repeatedly in organizations that have a bigger BI reporting base, where canned reports, dashboards, and self-service BI dominate business requirements even today.
When an engineer should choose this: Your organization has a purely BI-driven workload today, your team is SQL-native, and ML, streaming, or unstructured data requirements do not exist currently.
Where it breaks:
The core problem is not what this pattern does; it is what it cannot do when analytical needs evolve. And in my experience, they always do. Specific failure modes engineers hit at scale:
- Transformation pressure on one engine. Ingestion, transformation, and consumption all compete for warehouse compute. At high data volumes, this creates a workload management overhead or requires additional cost to separate out readers and writers.
- Vertical scaling becomes the only option. When the warehouse chokes under volume, the operations team scales up the cluster or splits reader/writer nodes by business unit. Both options add cost without adding architectural flexibility.
- Object Storage is a dump, not an asset. Raw files land in object storage but are never cataloged, versioned, or governed. Schema evolution and data lineage take significant engineering effort.
- No distributed compute path. ML model training, log analytics, clickstream analysis, and unstructured data have no home in this architecture.
- Re-architecture is expensive when needs change. Moving from this requires rearchitecting, often ending in the purchase of a costly SQL-driven SaaS solution because it was not built correctly.
Summary: Pattern 1 works cleanly for what it is designed for. The problem is that the design is not futuristic and significantly limits the value that data can generate.
Pattern 2: No Warehouse Scenario
Best for: Engineering-led teams, ad hoc analytics, big data exploration
Data flow:
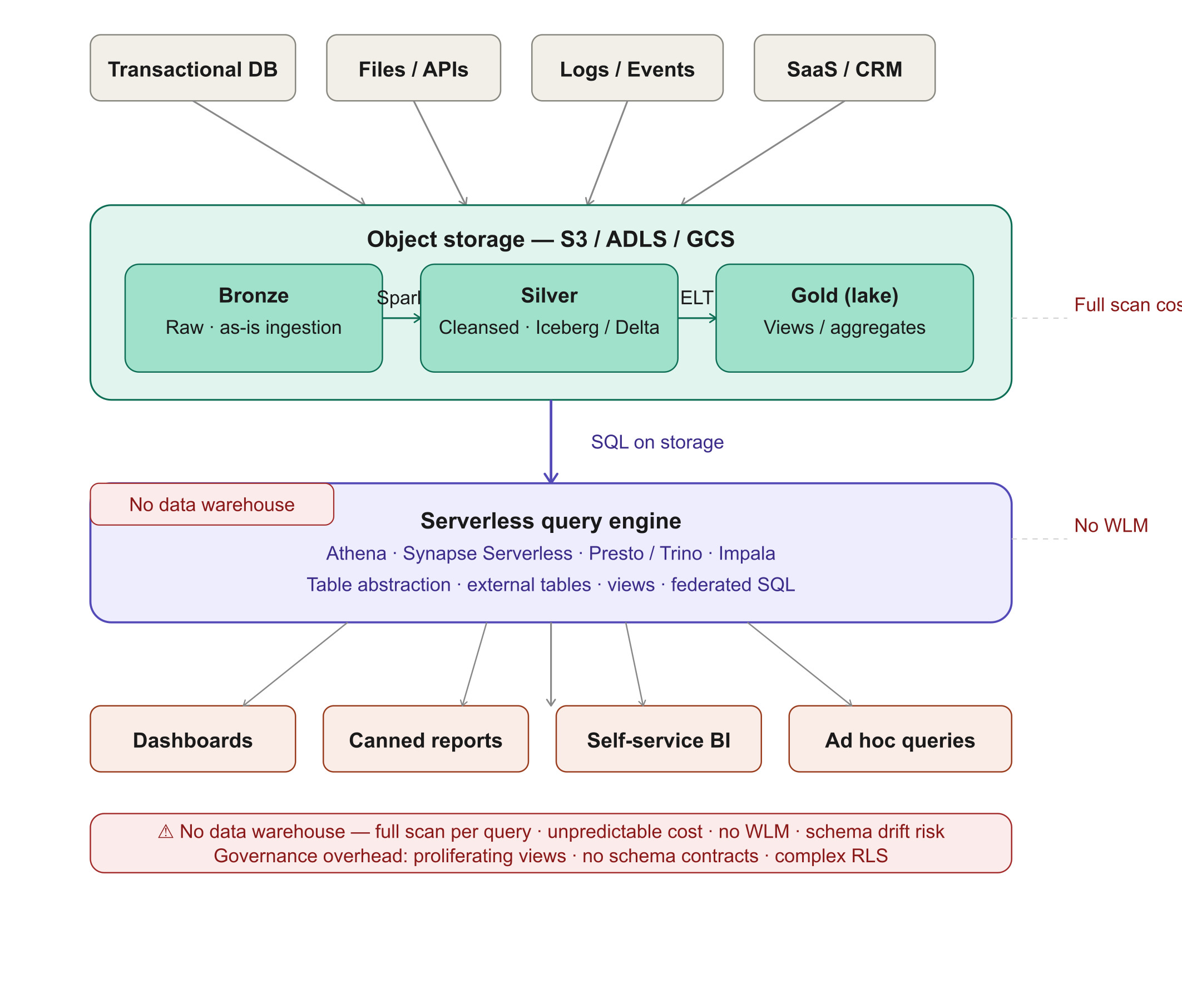
No data warehouse in the stack, instead a serverless query engine provides SQL abstraction directly over object storage. This pattern originated with Presto and Impala for big data analytics and worked well in that context.
When an engineer should choose this: Your workload is dominated by ad hoc analytical queries, ML feature exploration, or log analytics.
Where it breaks:
This pattern struggles when it gets applied to BI workloads. The specific challenges engineers hit:
- Query performance is tricky. Without careful partitioning and file size optimization on the data, a dashboard refresh at 9am (cold start) may trigger a full scan of terabytes of data, causing unpredictable BI performance.
- Cost is unpredictable. These engines charge per TB scanned, not per result row. Forgetting a date filter on a large table scan can cost thousands of dollars in bills. Warehouse compute costs are predictable; object-storage query costs are not.
- Concurrency challenges. Warehouses have mature workload management techniques that can do queuing, prioritization, and resource allocation. Serverless engines yet to reach that maturity. So concurrent dashboard users face timeouts and failures, not graceful queuing.
- Result-set caching helps for identical repeated queries, but any variation in filter parameters triggers a full storage scan. Dynamic dashboard filters with user-specific slicers make this caching largely ineffective for BI use cases.
- Data lake schemas evolve frequently. Cloud catalogs like Glue or Unity Catalog track changes, but downstream BI dashboards break silently when columns shift. A warehouse enforces the contract that protects reports.
Summary: Pattern 2 works perfectly for the scenarios that require distributed processing at scale. The problem is that the design is not built for low-latency use cases.
Pattern 3: Purposeful Hybrid
Best for: Mixed workloads, enterprise scale, cost-conscious organizations with a variety of workloads, adaptable, futuristic needs
Data flow:
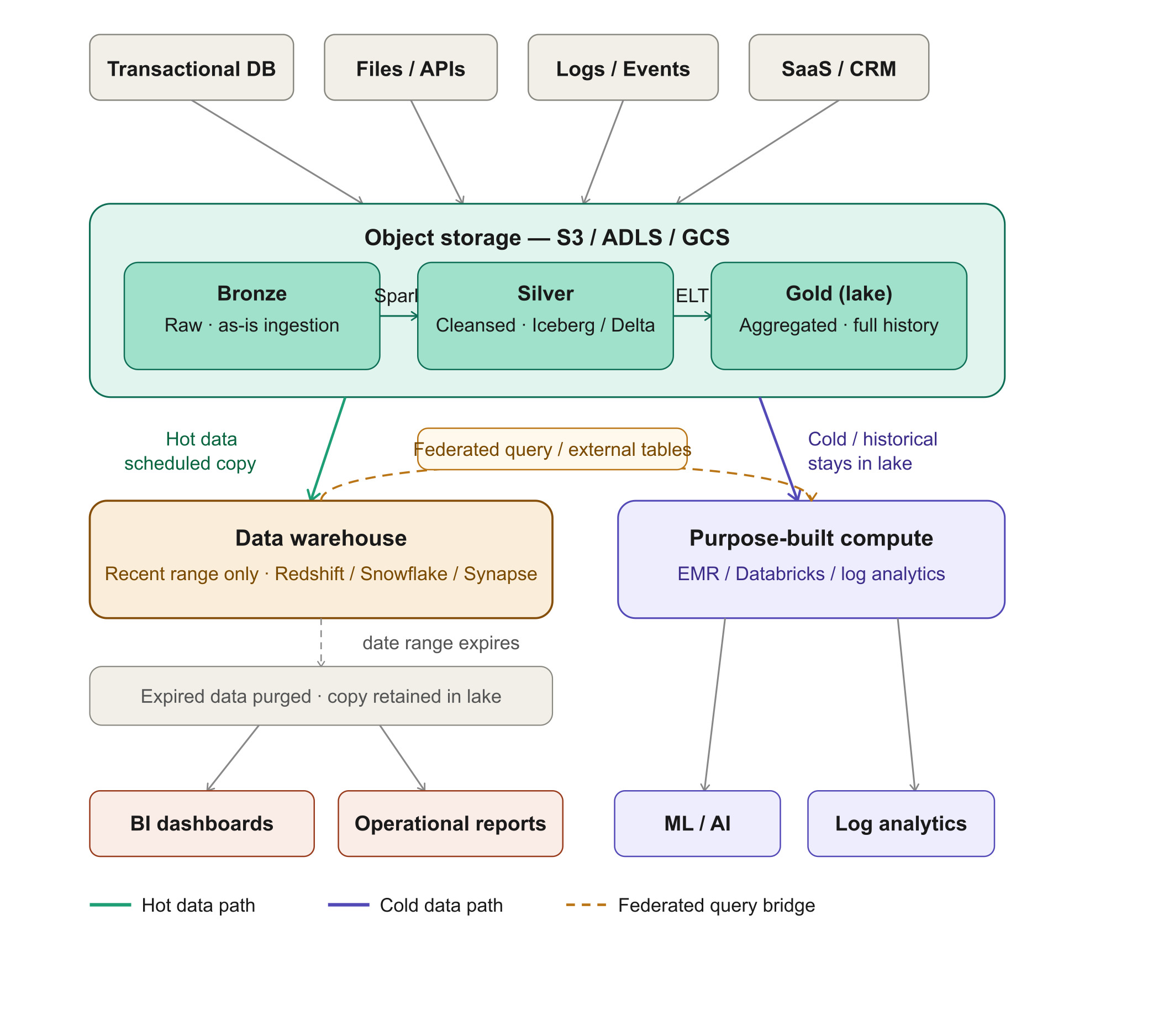
This is the pattern in my experience that acts as a best of both worlds scenario, because it requires deliberate data segmentation rather than a rigid architectural decision.
This has the ability to route each workload to the compute/storage that is purpose-built for it. ML models consuming ten years of data should not compete with operational dashboards needing sub-second response on last quarter's inventory. Object storage is cheap and scalable horizontally for everything, whereas a warehouse holds only what requires low-latency relational access.
Implementation on the warehouse side:
Instead of loading the full silver and gold layers into the warehouse, load only the date range business users need for low-latency reporting. In retail, inventory movement rarely needs more than a rolling year in the warehouse. In travel and hospitality, promotional rate performance reports typically span a few months. A schedule query copies the relevant date-partitioned data from the data lake into the warehouse, and purges expired ranges from the warehouse once they age out. The source data remains in object storage permanently.
This single mechanism drastically reduces warehouse compute and storage costs while keeping BI response times fast.
Handling historical range queries:
The common objection is: what about reports that need five years of history? The right engineering question is not "how do we make that fast?" — it is "does that query need millisecond latency?" A five-year inventory trend analysis requested once a quarter may not need a millisecond response time.
This is the exact use case for federated queries. Redshift Spectrum, Athena, and Synapse Serverless allow external tables to be defined over S3/ADLS data, queryable alongside physical warehouse tables with standard SQL joins. A retail analyst querying this week's inventory from Redshift joined against three years of history in S3 without moving a single byte
-- Example: federated query joining warehouse (hot) + lake (cold)
SELECT w.sku, w.inventory_count, h.avg_inventory_12m
FROM warehouse.inventory_current w
JOIN external_schema.inventory_history h -- data lives in S3
ON w.sku = h.sku
WHERE w.report_date = CURRENT_DATE
Decision Framework
The following table helps to decide which pattern is most suitable for their need
| Pattern 1 | Pattern 2 | Pattern 3 | |
|---|---|---|---|
|
BI performance |
High |
Unpredictable |
High |
|
ML / unstructured |
None |
Native |
Native |
|
Cost at scale |
Expensive |
Unpredictable |
Optimized |
|
Governance |
Low |
Strong |
Strong |
|
Scalability |
Vertical |
Horizontal |
Horizontal |
|
Implementation complexity |
Low |
Medium |
High |
|
Future-readiness |
Low |
Medium |
High |
|
Team skill required |
SQL |
Spark/Distributed computing |
Both |
The mistake is not choosing the wrong pattern; it is applying one pattern to all workloads. Every large enterprise I have worked with has a mix of workload types that no single architecture serves equally well.
| situation | recommended pattern |
|---|---|
|
>70% BI and reporting workload |
Pattern 1 or 3 |
|
Heavy ML, log, or unstructured data |
Pattern 2 or 3 |
|
Petabyte scale with cost pressure |
Pattern 3 |
|
Small to mid-size, SQL-native team |
Pattern 1 |
|
Ad hoc analytics dominant |
Pattern 2 |
Opinions expressed by DZone contributors are their own.
Comments