Big Data Ingestion: Flume, Kafka, and NiFi
Flume, Kafka, and NiFi offer great performance, can be scaled horizontally, and have a plug-in architecture where functionality can be extended through custom components.
Join the DZone community and get the full member experience.
Join For FreeWhen building big data pipelines, we need to think on how to ingest the volume, variety, and velocity of data showing up at the gates of what would typically be a Hadoop ecosystem. Preliminary considerations such as scalability, reliability, adaptability, cost in terms of development time, etc. will all come into play when deciding on which tools to adopt to meet our requirements. In this article, we’ll focus briefly on three Apache ingestion tools: Flume, Kafka, and NiFi. All three products offer great performance, can be scaled horizontally, and provide a plug-in architecture where functionality can be extended through custom components.
Apache Flume
A Flume deployment consists of one or more agents configured with a topology. The Flume Agent is a JVM process that hosts the basic building blocks of a Flume topology, which are the source, the channel, and the sink. Flume clients send events to the source, which places those events in batches into a temporary buffer called channel, and from there the data flows to a sink connecting to data’s final destination. A sink can also be a follow-on source of data for other Flume agents. Agents can be chained and have each multiple sources, channels, and sinks.
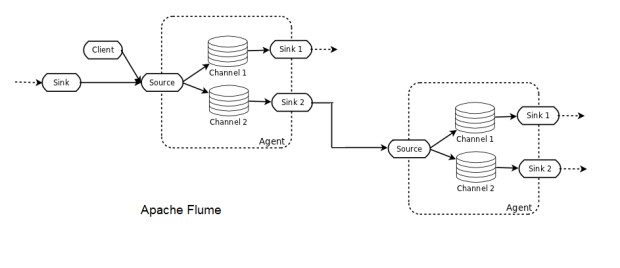 Flume is a distributed system that can be used to collect, aggregate, and transfer streaming events into Hadoop. It comes with many built-in sources, channels, and sinks, for example, Kafka Channel and Avro sink. Flume is configuration-based and has interceptors to perform simple transformations on in-flight data.
Flume is a distributed system that can be used to collect, aggregate, and transfer streaming events into Hadoop. It comes with many built-in sources, channels, and sinks, for example, Kafka Channel and Avro sink. Flume is configuration-based and has interceptors to perform simple transformations on in-flight data.
It is easy to lose data using Flume if you’re not careful. For instance, choosing the memory channel for high throughput has the downside that data will be lost when the agent node goes down. A file channel will provide durability at the price of increased latency. Even then, since data is not replicated to other nodes, the file channel is only as reliable as the underlying disks. Flume does offer scalability through multi-hop/fan-in fan-out flows. For high availability (HA), agents can be scaled horizontally.
Apache Kafka
Kafka is a distributed, high-throughput message bus that decouples data producers from consumers. Messages are organized into topics, topics are split into partitions, and partitions are replicated across the nodes — called brokers — in the cluster. Compared to Flume, Kafka offers better scalability and message durability. Kafka now comes in two flavors: the “classic” producer/consumer model, and the new Kafka-Connect, which provides configurable connectors (sources/sinks) to external data stores.
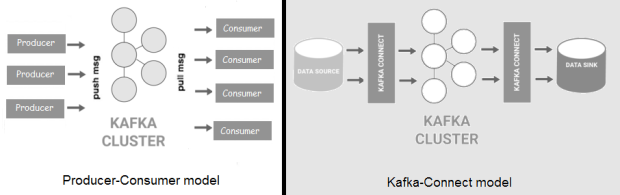
Kafka can be used for event processing and integration between components of large software systems. Data spikes and back-pressure (fast producer, slow consumer) are handled out-of-the-box. In addition, Kafka ships with Kafka Streams, which can be used for simple stream processing without the need for a separate cluster as for Apache Spark or Apache Flink.
Because messages are persisted on disk as well as replicated within the cluster, data loss scenarios are less common than with Flume. That said, custom coding is often required for producers/sources and consumers/sinks, either using Kafka clients or through the Connect API. As with Flume, there are limitations in message size. Finally, in order to be able to communicate, both Kafka producers and consumers have to agree on protocol, format, and schema, which can be problematic in some cases.
Apache NiFi
Unlike Flume and Kafka, NiFi. can handle messages with arbitrary sizes. Behind a drag-and-drop Web-based UI, NiFi runs in a cluster and provides real-time control that makes it easy to manage the movement of data between any source and any destination. It supports disparate and distributed sources of differing formats, schema, protocols, speeds, and sizes.
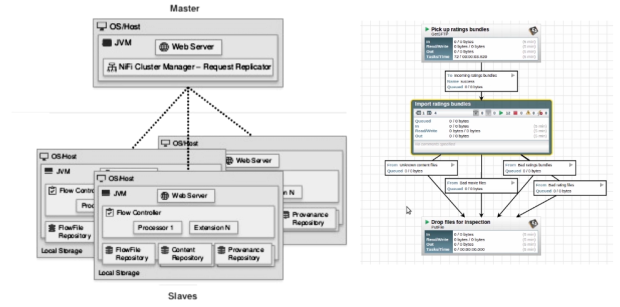
NiFi can be used in mission-critical data flows with rigorous security & compliance requirements, where we can visualize the entire process and make changes immediately, in real-time. At the time of this writing, it has close to 200 out-of-the-box processors (including Flume and Kafka processors) that can be dragged & dropped, configured and put to work right away. Some of NiFi’s key features are prioritized queuing, data traceability and back-pressure threshold configuration per connection.
Although it is used to create fault-tolerant production pipelines, NiFi does not yet replicate data like Kafka. If a node goes down, the flow can be directed to another node, but data queued for the failed node will have to wait until the node comes back up. NiFi is not a full-fledged ETL tool, nor ideal for complex computations and event processing (CEP). For that, it should instead connect to a streaming framework like Apache Flink, Spark Streaming or Storm.
Combinations
There isn’t a one-and-only tool that can do everything equally well and address all of your requirements. Combining tools that do different things in better ways allows for a buildup in functionality and increased flexibility in handling a larger set of scenarios. Depending on your needs, both NiFi and Flume can act as Kafka producers and/or consumers.
The Flume-Kafka integration is popular enough, it’s got its own name: Flafka (I’m not making this up). Flafka includes a Kafka source, Kafka channel, and Kafka sink. Combining Flume and Kafka allows Kafka to avoid custom coding and take advantage of Flume’s battle-tested sources and sinks, while Flume events passing through the Kafka channel are stored and replicated across Kafka brokers for resiliency.
Combining tools may appear wasteful, as it seems to introduce some overlap in functionality. For example, both NiFi and Kafka provide brokers to connect producers and consumers. However, they do so differently: in NiFi, the bulk of the data flow logic lays not inside the producer/consumer, but lives in the broker, allowing for centralized control. NiFi was built to do one important thing well: data flow management. With both tools combined, NiFi can take advantage of Kafka’s reliable stream data storage, while taking care of the dataflow challenges that Kafka was not designed to solve.
Conclusion
Summarizing:
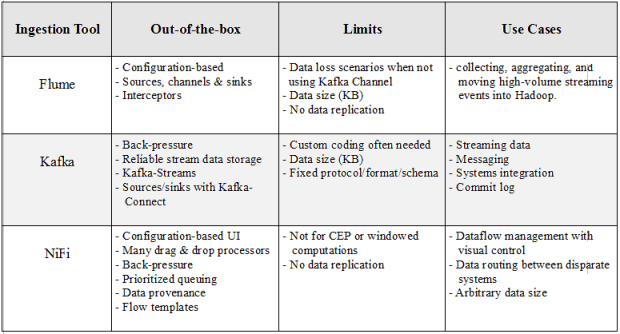
There is so much more to talk about, but that would be the subject of a book rather than an article. Also, as the tools mentioned here are rapidly evolving, this brief analysis, as all others regarding emerging technologies, is bound to become outdated sooner or later.
Published at DZone with permission of Tony Siciliani. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments