Big Data Processing in Spark
Join the DZone community and get the full member experience.
Join For FreeIn the traditional 3-tier architecture, data processing is performed by the application server where the data itself is stored in the database server. Application server and database server are typically two different machine. Therefore, the processing cycle proceeds as follows
- Application server send a query to the database server to retrieve the necessary data
- Application server perform processing on the received data
- Application server will save the changed data to the database server
In the traditional data processing paradigm, we move data to the code.
It can be depicted as follows ...

Then big data phenomenon arrives. Because the data volume is huge, it cannot be hold by a single database server. Big data is typically partitioned and stored across many physical DB server machines. On the other hand, application servers need to be added to increase the processing power of big data.
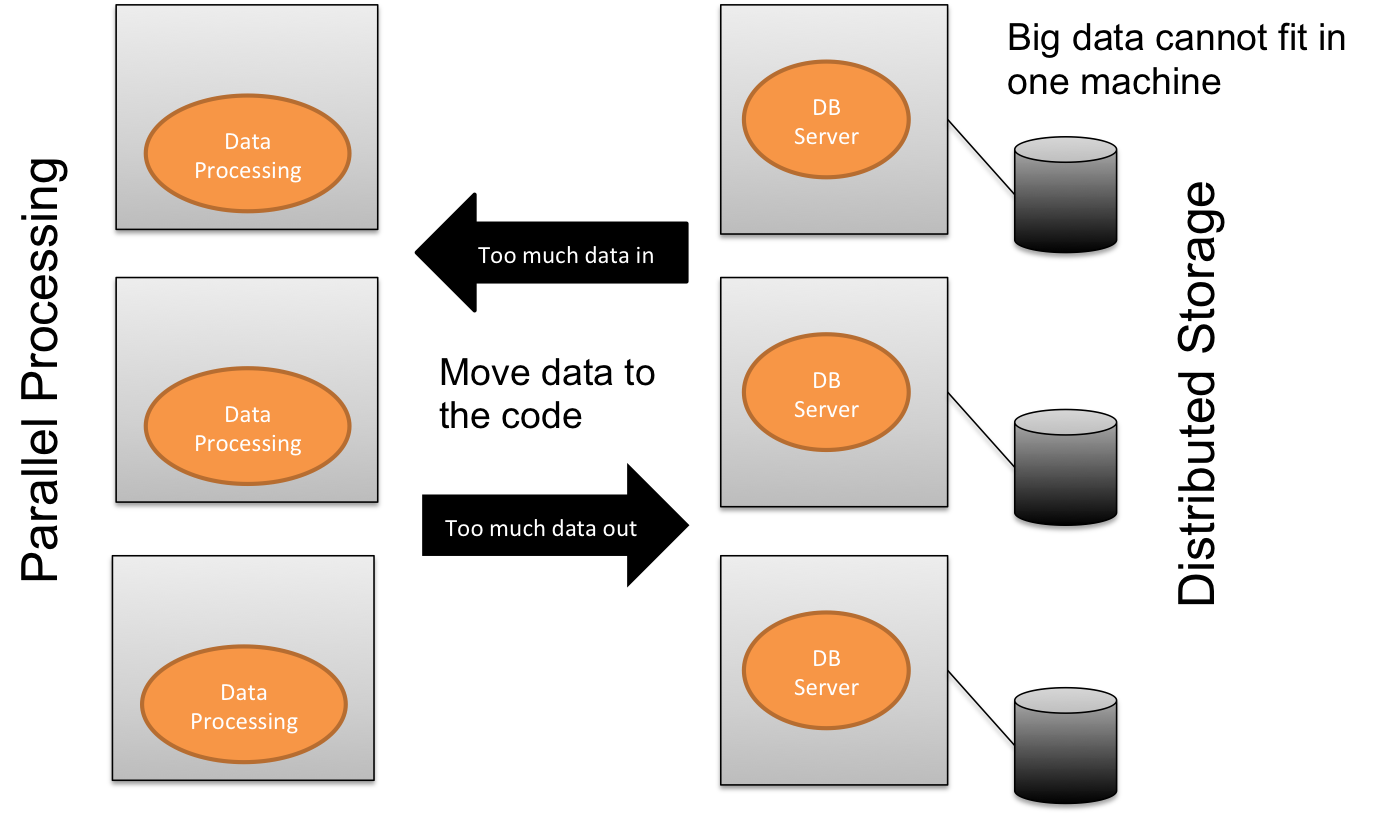
However, as we increase the number of App servers and DB servers for storing and processing the big data, more data need to be transfer back and forth across the network during the processing cycle, up to a point where the network becomes a major bottleneck.
Moving Code to Data
To overcome the network bottleneck, we need a new computing paradigm. Instead of moving data to the code, we move the code to the data and perform the processing at where the data is stored.

Notice the change of the program structure
- The program execution starts at a driver, which orchestrate the execution happening remotely across many worker servers within a cluster.
- Data is no longer transferred to the driver program, the driver program holds a data reference in its variable rather than the data itself. The data reference is basically an id to locate the corresponding data residing in the database server
- Code is shipped from the program to the database server, where the execution is happening, and data is modified at the database server without leaving the server machine.
- Finally the program request a save of the modified data. Since the modified data resides in the database server, no data transfer happens over the network.
By moving the code to the data, the volume of data transfer over network is significantly reduced. This is an important paradigm shift for big data processing.
In the following session, I will use Apache Spark to illustrate how this big data processing paradigm is implemented.
RDD
Resilient Distributed Dataset (RDD) is how Spark implements the data reference concept. RDD is a logical reference of a dataset which is partitioned across many server machines in the cluster.

To make a clear distinction between data reference and data itself, a Spark program is organized as a sequence of execution steps, which can either be a "transformation" or an "action".
Programming Model
A typical program is organized as follows
- From an environment variable "context", create some initial data reference RDD objects
- Transform initial RDD objects to create more RDD objects. Transformation is expressed in terms of functional programming where a code block is shipped from the driver program to multiple remote worker server, which hold a partition of the RDD. Variable appears inside the code block can either be an item of the RDD or a local variable inside the driver program which get serialized over to the worker machine. After the code (and the copy of the serialized variables) is received by the remote worker server, it will be executed there by feeding the items of RDD residing in that partition. Notice that the result of a transformation is a brand new RDD (the original RDD is not mutated)
- Finally, the RDD object (the data reference) will need to be materialized. This is achieved through an "action", which will dump the RDD into a storage, or return its value data to the driver program.
Here is a word count example
# Get initial RDD from the context
file = spark.textFile("hdfs://...")
# Three consecutive transformation of the RDD
counts = file.flatMap(lambda line: line.split(" "))
.map(lambda word: (word, 1))
.reduceByKey(lambda a, b: a + b)
# Materialize the RDD using an action
counts.saveAsTextFile("hdfs://...")
When the driver program starts its execution, it builds up a graph where nodes are RDD and edges are transformation steps. However, no execution is happening at the cluster until an action is encountered. At that point, the driver program will ship the execution graph as well as the code block to the cluster, where every worker server will get a copy.
The execution graph is a DAG.
- Each DAG is a atomic unit of execution.
- Each source node (no incoming edge) is an external data source or driver memory
- Each intermediate node is a RDD
- Each sink node (no outgoing edge) is an external data source or driver memory
- Green edge connecting to RDD represents a transformation. Red edge connecting to a sink node represents an action

Data Shuffling
Although we ship the code to worker server where the data processing happens, data movement cannot be completely eliminated. For example, if the processing requires data residing in different partitions to be grouped first, then we need to shuffle data among worker server.
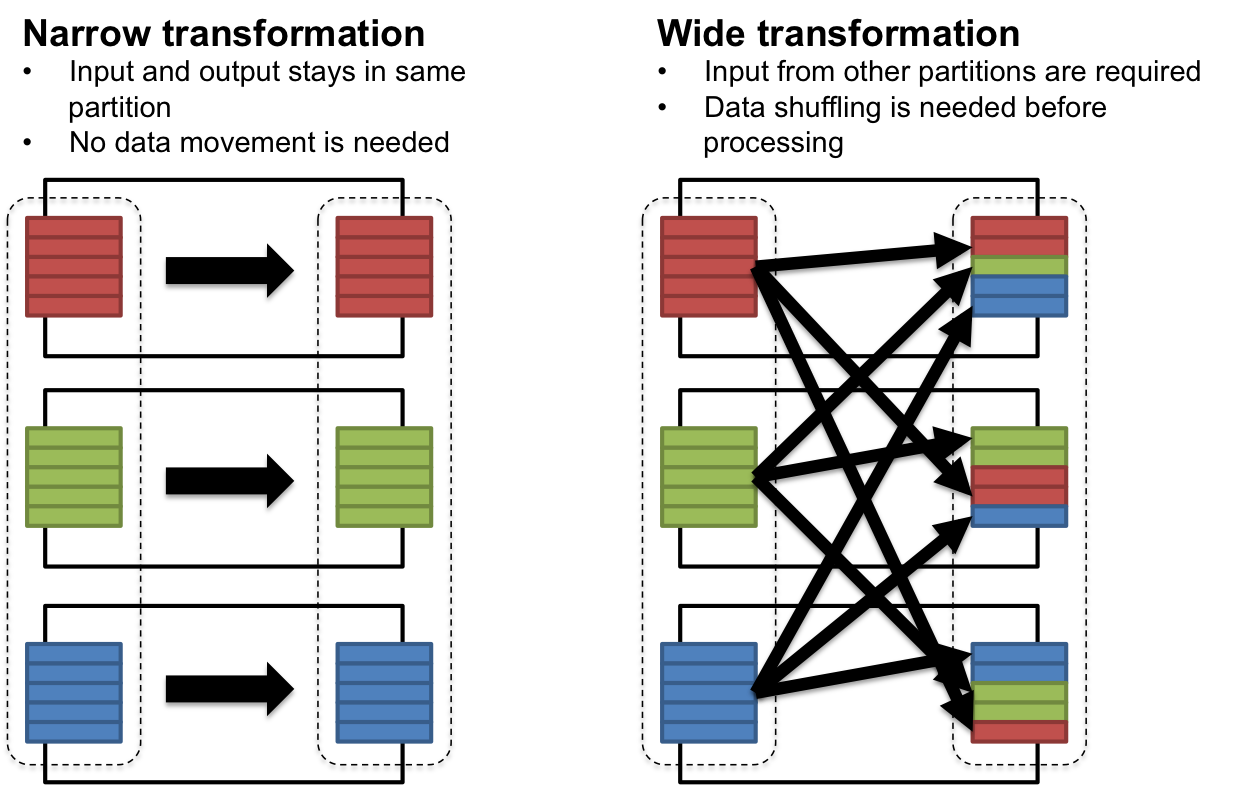
Spark carefully distinguish "transformation" operation in two types.
- "Narrow transformation" refers to the processing where the processing logic depends only on data that is already residing in the partition and data shuffling is unnecessary. Examples of narrow transformation includes filter(), sample(), map(), flatMap() .... etc.
- "Wide transformation" refers to the processing where the processing logic depends on data residing in multiple partitions and therefore data shuffling is needed to bring them together in one place. Example of wide transformation includes groupByKey(), reduceByKey() ... etc.
Joining two RDD can also affect the amount of data being shuffled. Spark provides two ways to join data. In a shuffle join implementation, data of two RDD with the same key will be redistributed to the same partition. In other words, each of the items in each RDD will be shuffled across worker servers.
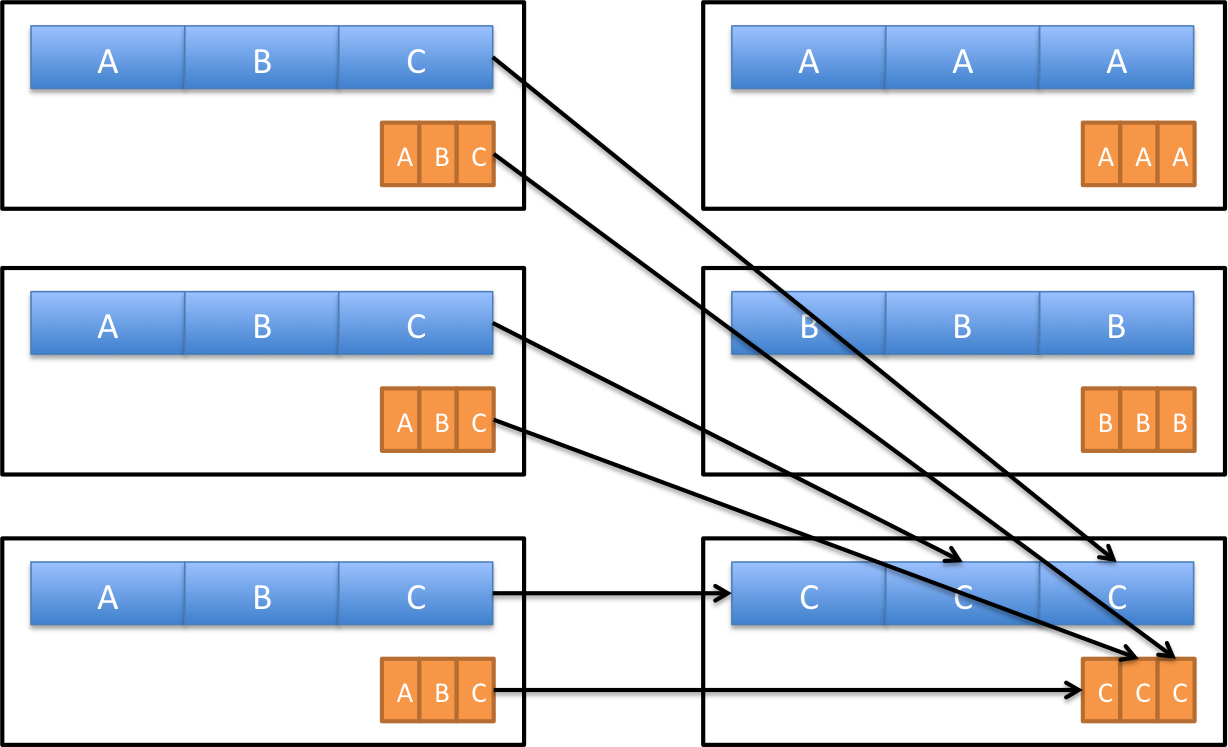
Beside shuffle join, Spark provides another alternative call broadcast join. In this case, one of the RDD will be broadcasted and copied over to every partition. Imagine the situation when one of the RDD is significantly smaller relative to the other, then broadcast join will reduce the network traffic because only the small RDD need to be copied to all worker servers while the large RDD doesn't need to be shuffled at all.

In some cases, transformation can be re-ordered to reduce the amount of data shuffling. Below is an example of a JOIN between two huge RDDs followed by a filtering.

Plan1 is a naive implementation which follows the given order. It first join the two huge RDD and then apply the filter on the join result. This ends up causing a big data shuffling because the two RDD is huge, even though the result after filtering is small.
Plan2 offers a smarter way by using the "push-down-predicate" technique where we first apply the filtering in both RDDs before joining them. Since the filtering will reduce the number of items of each RDD significantly, the join processing will be much cheaper.
Execution Planning
As explain above, data shuffling incur the most significant cost in the overall data processing flow. Spark provides a mechanism that generate an execute plan from the DAG that minimize the amount of data shuffling.
- Analyze the DAG to determine the order of transformation. Notice that we starts from the action (terminal node) and trace back to all dependent RDDs.
- To minimize data shuffling, we group the narrow transformation together in a "stage" where all transformation tasks can be performed within the partition and no data shuffling is needed. The transformations becomes tasks that are chained together within a stage
- Wide transformation sits at the boundary of two stages, which requires data to be shuffled to a different worker server. When a stage finishes its execution, it persist the data into different files (one per partition) of the local disks. Worker nodes of the subsequent stage will come to pickup these files and this is where data shuffling happens
Below is an example how the execution planning turns the DAG into an execution plan involving stages and tasks.

Reliability and Fault Resiliency
Since the DAG defines a deterministic transformation steps between different partitions of data within each RDD RDD, fault recovery is very straightforward. Whenever a worker server crashes during the execution of a stage, another worker server can simply re-execute the stage from the beginning by pulling the input data from its parent stage that has the output data stored in local files. In case the result of the parent stage is not accessible (e.g. the worker server lost the file), the parent stage need to be re-executed as well. Imagine this is a lineage of transformation steps, and any failure of a step will trigger a restart of execution from its last step.
Since the DAG itself is an atomic unit of execution, all the RDD values will be forgotten after the DAG finishes its execution. Therefore, after the driver program finishes an action (which execute a DAG to its completion), all the RDD value will be forgotten and if the program access the RDD again in subsequent statement, the RDD needs to be recomputed again from its dependents. To reduce this repetitive processing, Spark provide a caching mechanism to remember RDDs in worker server memory (or local disk). Once the execution planner finds the RDD is already cache in memory, it will use the RDD right away without tracing back to its parent RDDs. This way, we prune the DAG once we reach an RDD that is in the cache.
Overall speaking, Apache Spark provides a powerful framework for big data processing. By the caching mechanism that holds previous computation result in memory, Spark out-performs Hadoop significantly because it doesn't need to persist all the data into disk for each round of parallel processing. Although it is still very new, I think Spark will take off as the main stream approach to process big data.
Published at DZone with permission of Ricky Ho. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments