Boost of Parallelism Using Producer/Consumer Pattern
Here are some of the effects of and use cases which would be fit for using the Producer/Consumer pattern.
Join the DZone community and get the full member experience.
Join For FreeIn general, there are two ways to achieve parallelism in your application. As always, both solutions have pros and cons and their core use cases are absolutely different. However, you can always use shared memory and access it from different threads (and bend the main purpose of one of the solutions), but if there is a possibility to hide the complexity in some library, why not exploit it?
Producer/Consumer Pattern

There are, of course, a lot of meaningful use cases where the Producer/Consumer pattern fits perfectly. However, in general, we want to internally separate two parts of one application into independent pieces to get some desired behavior of our app.
The Main Reasons to Follow the Producer/Consumer Pattern
- We want to prepare our monolithic application logically for separating into two parts with, for example, RabbitMQ in the middle.
- There is an intention to process a task asynchronously and not block the Producer and return a result immediately (for example, if the REST API doesn't process the task, but just enqueues it and immediately returns a status code 200).
- We ran into scalability problems and we would like to scale only one part of our application (the Consumer) while the Producer stays the same
- We would like to protect some very contented resource and access it only from one thread (logging to a file) and not from multiple producer's threads which could be blocked on the contented resource (inefficient usage of threads, context switches)
- We want to increase the throughput of our app, which means we can accept and cache a lot of tasks/ HTTP connections internally in the app at the same time and let them process later (latency can suffer, but we don't risk that, perhaps, the HTTP connection timeout will occur until one of our threads is ready to accept a new connection)
Decisions You Have to Make Before You Go to Production
Is My Application a Proper Fit for the Producer/Consumer Pattern?
We need to have a clear separation between both parts of our application to ensure that a final implementation won't be over-engineered (in general, that means that there is no connection back from Consumer to Producer, no return value).
How Many Producers and Consumers You Need to Stay Efficient?
In a contention between multiple producers or consumers (when they enqueue/dequeue tasks), very often a single consumer solution is much more efficient than a solution with multiple consumers (follow the terms SPSC/MPSC/SPMC/MSMC).
Bounded or Unbounded?
It's known that the Producer/Consumer pattern tends to work for either an empty queue or a full queue, which means we have to decide in advance what kind of queue we want to use. This is probably the most difficult question because even if we don't care about microseconds in our app, we can very easily either create a bottleneck, kill our application because of lack of memory, or completely throw away incoming tasks.
Unbounded: This queue can grow "infinitely" (Integer.MAX_VALUE) and is mostly implemented using a LinkedList. If we pick up this queue we say that:
- We don't want to limit the number of tasks in our queue which means we don't know the difference between the situations when our application is in a normal state and in some kind of peak.
- We always want to keep the same separation between Part 1 and Part 2 (and threads which handle the first or second part) of our application and don't want to care about any other solution to mitigate the peak with a lot of incoming tasks at the same time (will be explained later in a section dedicated to bounded queues)
- We know that there is a risk we can run into a problem with memory. It does not matter what the size of the objects/tasks stored and waiting in our queue is because we know that there is a chance that our queue is constantly growing over days/weeks and someday we will see
OutOfMemoryExceptionand our application will be killed even with all our enqueued tasks. - Unfortunately, there is no efficient way to monitor the size of queues in JDK.
- One very good signal is a constantly growing latency in the processing of our tasks because the task needs to wait longer and longer to be picked up.
- We are aware that we just want to survive short-running peaks without blocking producers or throwing away incoming tasks and that we have some time after the peak to recover and process remaining tasks.
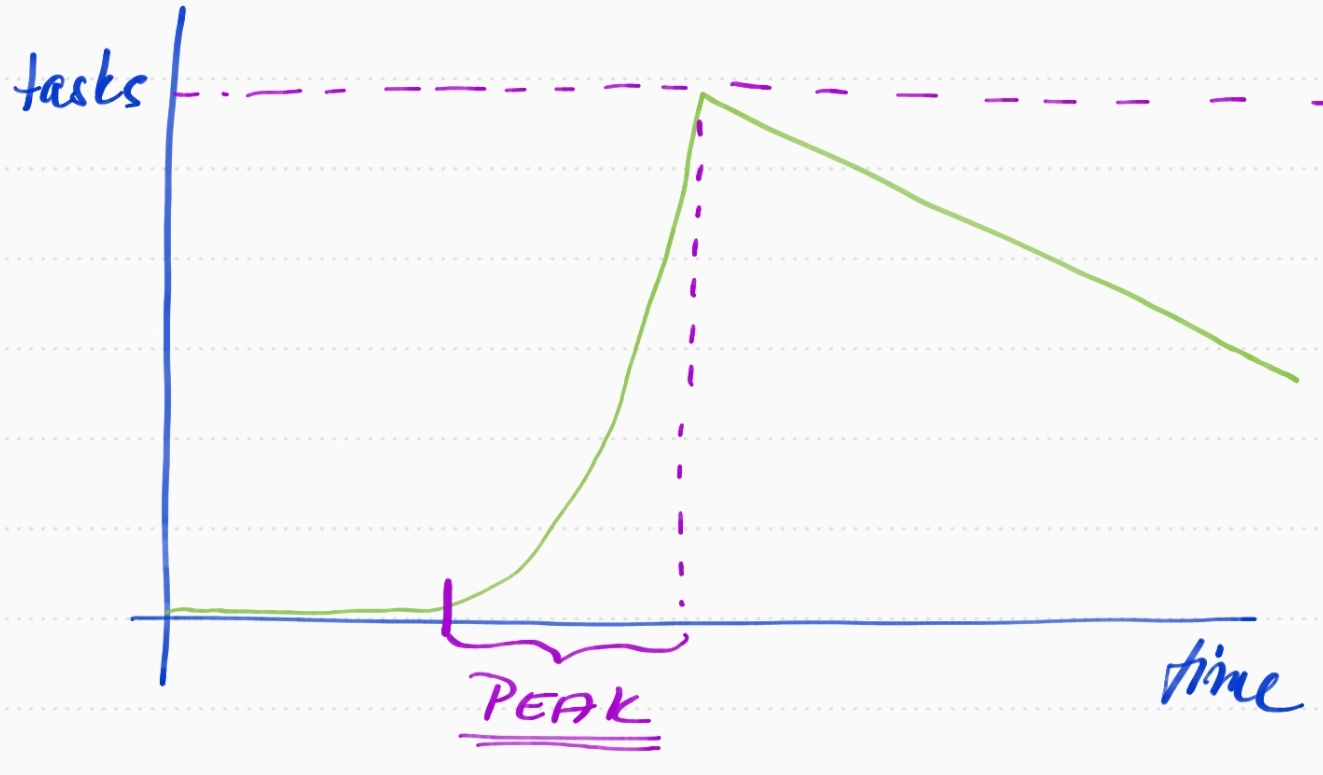
- We are able to scale the number of consumers effectively/dynamically or we don't mind that the latency of processing tasks is going to be higher for a while.
- We NEVER want to throw away or reject the task for a price of memory uncertainties
Bounded: A bounded queue is most likely implemented using an array and limits the number of tasks waiting in the queue at every single moment.
- We don't have to worry about memory exhaustion but we need to see if our maximum number of tasks in a queue is absolutely safe especially in a case of running with limited resources, in a docker container.
- We need to choose an implementation of
RejectedExecutionHandler, which is an interface specifying what to do when the queue reached the max limit tasks in a queue. - It's useful if our workload is much more fluent and predictable than an unbounded queue, because we don't have to cover any significant peaks. Or if we run into the situation when a max limit is reached, then
RejectionExecutionHandlercomes into play.
What if Our Bounded Queue Exceeds the Maximum Limit of Tasks?
If we choose to go for a bounded queue because of a predictable workload and because we want to be sure that our application won't be exhausted by short-term peaks, then we need to specify what to do if we exhaust the buffer for our tasks.
In a nutshell, it means that we need to choose any of the RejectedExecutionHandlerwhich specifies the strategy to apply for every task which does not fit into a queue. Unfortunately, every implementation can violate one of the architectural reasons why we went for the Producer/Consumer pattern.
AbortPolicy: This implementation just throws an exception for every unfit task, which means the task is thrown away and won't be ever processed by our consumers. This can be useful if we don't want to worry about overloading of our memory in our application and we can sacrifice not-so-important tasks in a peak.
It's really not a good fit for financial operations when we over-allocate the number of consumers the lose any of the tasks. On the other hand, in a situation, when our producer does two things and we can implement the storing into the database as a synchronous call (we need to be sure that it's processed correctly) and don't want to sacrifice time for logging into a contended resource which could dramatically decrease latency/throughput of producer (e.g. HTTP threads handling incoming requests), especially in a peaks when a lot of threads want to write something.
This implementation is also the default for JDK.
CallerRunsPolicy: This says that we don't want to abort any task. We would rather sacrifice throughput/latency to finish an execution and process everything correctly. It can also cripple an "application design" a bit if we count on that consumer's code is executed only on consumer's threads, now we are about to run consumer's code on producer's threads.
DiscardOldestPolicy: The oldest tasks sitting in the queue are discarded in favor of new incoming tasks. It works perfectly if our application logic cares only about the most recent tasks and can sacrifice older values. We can reason about this implementation as a sliding window upon the incoming values.
[1, 3, 4, ,1 , 2, 4, 2, 3, 3, 1]
[________<--------------->]
Let's say we have four options and are receiving a current value for every option which means we don't want to process older values, as it's pointless because the new ones are already in a queue. We just need to ensure that the queue size is big enough to be sure that we keep at least one value from every option and don't discard the latest one.
DiscardPolicy: It simply ignores the incoming task (even without any log message or an exception). It's useful for testing purposes or when we are really sure that those tasks stored in our queue are really expendable.
Can I Customize My Consumer Threads?
Yes, and it's encourage. If you take your application seriously, you definitely want to connect it to some profiler to see what actually your threads are doing. There are two interesting options to set up.
Prefix - A custom name with a counter, it's a great approach to distinguish consumer's threads from the others in profilers or thread dumps.
UncaughtExceptionHandler - If your thread throws an exception, we need to have a way to catch and process the exception. A default implementation just writes a stack trace into STDERR and kills the thread (which can be automatically created again if we use service-executors with a constant number of worker threads). However, we can implement some custom behavior.
An instance of CustomThreadFactory can be passed via a factory method in a utility class Executors (see below).
How Can I Implement the Producer/Consumer Pattern in Java?
There is a lot of examples which describe an implementation of the Producer/Consumer pattern. The majority of them can be very useful in case of interview questions but, please, never use it in production. A standard library in Java contains a great implementation called ServiceExecutor . There is also a great set of utility methods in a class Executors .
ExecutorService fixedExecutor = Executors.newFixedThreadPool(3,
new CustomThreadFactory("custom", new AlertExceptionHandler()));ExecutorService singleExecutor = Executors.newSingleThreadExecutor();
ThreadPoolExecutor customThreadPool = new ThreadPoolExecutor(0, 3,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<>(),
new CustomThreadFactory("custom", new AlertExceptionHandler()));
The snippet above shows several options on how to create a queue with a worker thread pool. You might be asking, "Where is the producer part of our application?" Producers are threads putting tasks into the executor-service, and they might be threads belonging RabbitMQ Client, HTTP Server, etc.
Always be aware of the queue you about to use inside the executor-service, as it influences your application's behavior the way we discussed above in "Bounded or Unbounded?" section.
Do I Need to Solve Any Problems with The Visibility of My Shared Objects in A Queue?
You are about to access an object living in shared memory by multiple threads: producer's thread creates the object and a consumer wants to access its fields. This is a typical example of a problem with visibility. If this situation wouldn't be handled you could see an object with partially initiated properties, null reference of the object itself, incomplete collections, etc. in consumer code.
However, it's not this case because we are using internally a queue from the package java.util.concurrent. All data structures from this package ensure that the values passing through are fully visible to threads consuming from them.
Thank you for reading my article and please let some comments below. If you like being notified about new posts then start following me on Twitter: @p_bouda.
Opinions expressed by DZone contributors are their own.
Comments