Operational Principles, Architecture, Benefits, and Limitations of Artificial Intelligence Large Language Models
Large Language Models (LLMs) are advanced AI systems that generate human-like text by learning from extensive datasets and employing deep learning neural networks.
Join the DZone community and get the full member experience.
Join For FreeAbstract
Understanding Large Language Models
LLM is an advanced AI system for understanding and generating human-like text based on the input it receives. They are trained on vast datasets comprising books, articles, websites, and other forms of written language, enabling them to perform a variety of tasks, including:
- Answering questions
- Writing essays or articles
- Assisting with programming
- Translating languages
- Engaging in conversations
These models leverage deep learning techniques, particularly neural networks, to process and understand nuanced language patterns.
Applications and Benefits of Large Language Models
- Creating coherent and contextually relevant text, which can be useful for content creation and storytelling.
- Providing informative answers to user inquiries by drawing on their knowledge base, making it useful for customer support and information retrieval.
- Evaluating texts to determine their emotional tone, which is valuable in marketing and social media analysis.
- Providing explanations, tutoring, and personalized learning experiences based on user input.
How Large Language Models Operate
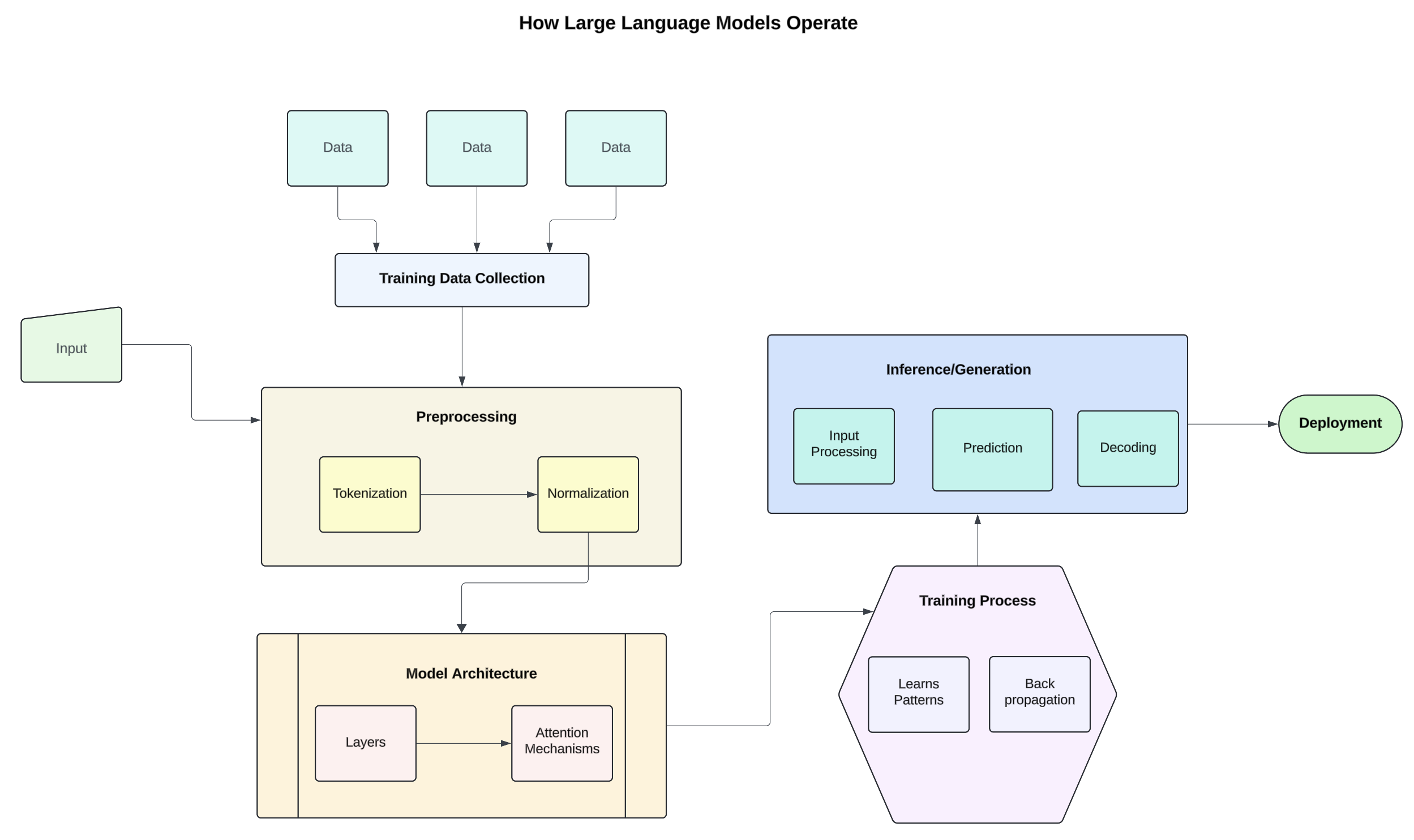
Figure 1: How Large Language Models Operate
- LLMs are trained on diverse datasets that include books, articles, websites, and other text sources. This extensive data helps the model learn varied language patterns, grammar, context, and knowledge about the world.
- Before training, the text data is preprocessed for suitability. This involves splitting text into smaller units (tokens), such as words or subwords, and lowercasing, removing special characters, etc., to standardize the text. LLMs are often based on architectures like the Transformer, which includes:
- Multiple layers of neurons designed to process sequential data. It helps the model focus on relevant parts of the input text, allowing it to weigh the importance of different words relative to one another.
- It learns to predict the next word in a sentence given the previous words, adjusting its internal parameters (weights) to minimize prediction errors.
- This is used to adjust weights based on the error of predictions, improving accuracy over time.
- Once trained, the model can generate text or respond to prompts. The input is tokenized and transformed into a numerical format that the model can understand. Next, the model processes the input through its layers, utilizing learned weights. Then, the model outputs probabilities for the next token, which can be converted back into text. Techniques like beam search or sampling can be used to generate coherent responses.
- The trained model is deployed in applications to provide capabilities like chatbots, content generation, or language translation.
Server-Side Implementation of Large Language Models
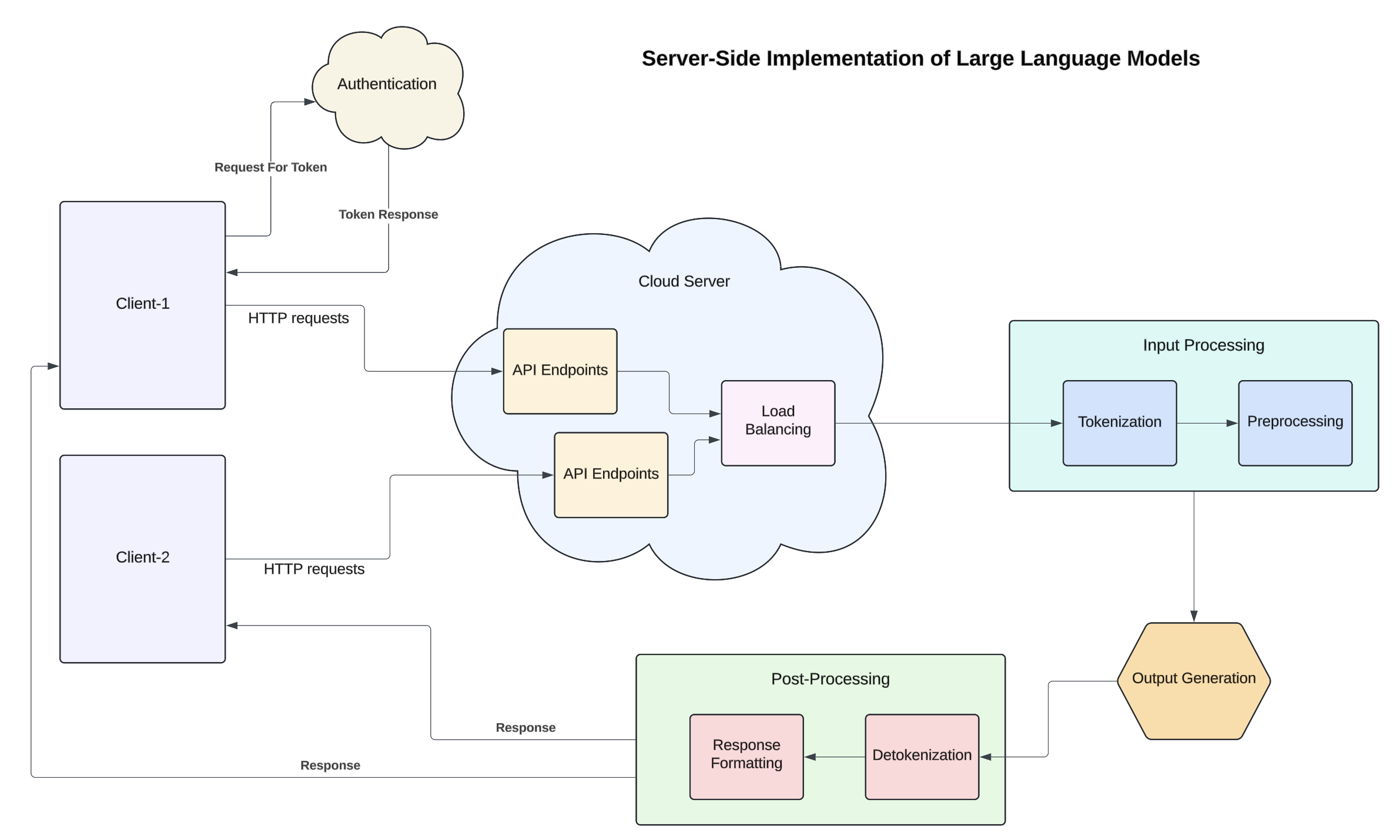
Figure 2: Server-Side Implementation of Large Language Models
Here's an explainer for Figure 2:
- Cloud infrastructure allows for scaling resources up or down based on demand, accommodating many users simultaneously.
- Users interact with the model via Application Programming Interfaces (APIs). Developers send HTTP requests to a specific endpoint provided by the service, encapsulating their input data (e.g., prompts, questions).
- Server-side architectures often include load balancing to distribute incoming requests across multiple servers, ensuring reliability and speed.
- Additional steps might include normalizing the input text (i.e., removing special characters) to make it suitable for model input.
- The tokenized input is fed into the LLM, where the data is processed through its neural network layers. Each layer applies transformations and attention mechanisms to extract contextual information.
- Most server-side LLM services require user authentication (e.g., API keys) to prevent misuse and ensure controlled access.
- Ongoing improvement involves retraining the model periodically with new data to enhance performance.
- Different versions of the model can coexist, allowing developers to choose which version to use based on their needs.
- LLMs are resource-intensive, requiring powerful GPUs or TPUs for processing. Running these models locally on consumer devices is often impractical due to their size and computational demands.
Advantages of Server-Side Large Language Models
- LLMs require significant computational resources (GPUs/TPUs) to perform efficiently. Server-side implementations provide access to this power without needing users to invest in expensive hardware.
- Cloud-based solutions can easily scale to accommodate varying levels of user demand. Providers can allocate more server resources as needed to ensure consistent performance.
- Updates, improvements, and bug fixes can be deployed centrally. Users automatically benefit from the latest enhancements without having to manage installations themselves.
- LLMs hosted on servers can be accessed via APIs, making it easier for developers to integrate advanced language processing capabilities into their applications without deep expertise in machine learning.
- Server-side implementations can be designed with robust security measures, ensuring data protection.
- Multiple users can access the model simultaneously without impacting performance. Server-side solutions are designed to handle many requests in parallel.
- User interactions can be logged and analyzed (with appropriate anonymization) to improve the model over time. This can lead to better future iterations based on real user data.
Challenges and Limitations of Server-Side Large Language Models
While server-side Large Language Models (LLMs) offer many advantages, they also have several limitations and challenges. Here are some of the key drawbacks.
- Server-side processing requires sending requests over the internet, which can introduce latency. Delays can be significant in applications requiring real-time responses.
- Users must send their data to external servers, raising concerns about data privacy and security. Sensitive information might be exposed or mishandled during transit or storage.
- Server-side solutions rely on the availability of the provider’s infrastructure. Outages or mainte- nance can lead to service interruptions affecting the user’s applications.
- Server-side LLMs require a constant connection to the cloud, limiting their usability in offline scenarios, such as remote locations or areas with unreliable internet.
On-Device Large Language Models

Figure 3: On-Device Implementation of Large Language Models
- On-device LLMs are often smaller and optimized versions of larger models. Techniques like model compression, quantization, and distillation reduce the model’s size while aiming to retain as much of its performance as possible.
- Users can download and install the model directly onto their devices.
- User input is processed directly on the device. This typically involves tokenization (converting input text into tokens) and any necessary preprocessing.
- The model performs inference locally, which means it generates predictions or outputs without needing to send data to a remote server. This is done through a forward pass in the neural network, where the model processes the input text internally to produce an output.
- The output tokens generated by the model are converted back into human-readable text. This is done entirely on the device, again eliminating the need for internet connectivity.
- Since data processing occurs locally, on-device LLMs generally provide better privacy. User data does not need to be transmitted to third-party servers, reducing the risk of data exposure or breaches.
- On-device inference often results in lower latency since there’s no need for network communication. This is particularly beneficial for applications requiring real-time responses, such as virtual assistants or interactive applications.
- One significant advantage is the ability to function offline. This allows users to engage with the model even in areas without internet connectivity.
Limitations of On-Device Large Language Models
-
On-device LLMs must operate within the processing power, memory, and storage limitations of the device, which can restrict the model’s size and complexity.
-
On-device LLMs may be unable to process long input sequences effectively, limiting their ability to handle more extensive and complex interactions.
-
Different devices have varying capabilities, leading to inconsistent performance across different hardware. A model may perform well on high-end devices but poorly on lower-end ones.
-
Unlike cloud-based solutions that can be updated centrally, on-device models typically require users to manually update the application or model. This can result in users running outdated versions.
-
Running intensive computations locally can consume significant battery power, especially in mobile devices, impacting the overall user experience.
-
On-device models generally don’t benefit from real-time data aggregation and feedback as server-side models might. This can limit their improvement and adaptation over time based on user interactions.
Conclusion
References
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., and Sutskever, I. (2019). Language models are unsupervised multitask learners. OpenAI Blog, 1(8), 9
Opinions expressed by DZone contributors are their own.
Comments