Bridge the Gap of Zip Operation
In this article, this author takes a look at the alternatives the zip operation that Java does not provide, and argues against StackOverflow's top pick.
Join the DZone community and get the full member experience.
Join For FreeDespite Java not providing a zip operation, you don't need either 30 additional lines to implement it, nor a third party library. Simply compose a zipline through the existing Stream API.
Abstract
Java, from its 8th version onward, provides an easy way to query sequences of elements through its Stream Interface, which provides several operations out of the box. This set of operations is quite versatile but, as can be expected, it does not cover all the operations a programmer may require. One such operation is zip, as we can observe in one of the most visited posts about Java Streams in Stackoverfow: Zipping streams using JDK8 with lambda (java.util.stream.Streams.zip). Even 7 years later, we are now on Java 14 release and there is no zip operation for Streams yet.
Nevertheless, from all workarounds provided to the absence of zip, all of them incur at least in one of the following drawbacks:
1. Verbosity;
2. Non-fluent;
3. Underperforming;
4. Dependency of a third-party library.
In fact, the most voted answer based on Java’s Stream extensibility, not only incurs in 35 lines of code to implement an auxiliary zip() method (1. Verbosity), but it also breaks the fluent chaining of a stream pipeline (2. Non-fluent) and moreover, it is still far from being the most performant alternative (3. Underperforming).
Here we analyze other alternative approaches to the Java’s Stream extensibility (section 2.1), namely the use of a third-party library to suppress the absence of zip (such as Guava or Protonpack in section 2.2) or to entirely replace Stream by another type of Sequence (such as jOOλ, Jayield, StreamEx and Vavr in section 2.3). And, we also include in our comparison a fourth alternative denoted as zipline (in section 2.4) that combines a map() operation with the use of an auxiliary iterator to achieve the desired zip processing.
Next, we will give further details about all these solutions and a performance analysis built with JMH support to benchmark the queries every() and find() (mentioned in the Stackoverflow question) that traverse two sequences through a zip() operation provided by each alternative. Pursuing unbiased results we have also developed another benchmark, which tests more complex queries with a realistic data source (namely the Last.fm Web API).
No solution is best in all possible scenarios, so we have summarized in this article the behavior of each approach for each of the four mentioned drawbacks. Put it simply, from our results, we can observe that the most voted answer on Stackoverflow gathers less advantages than any other alternative and there are other viable choices better suited to the constraints ruling each development environment.
1. Introduction
Zip, also known as Convolution, is a function that maps a Tuple of sequences into a sequence of tuples. As an exercise, let's imagine that zip is supported by Stream and that we have one stream with song names and another with the same song's artist's names, we could use zip to pair them up like so:
Stream<String> songs = Stream.of("505", "Amsterdam", "Mural");
Stream<String> artists = Stream.of("Arctic Monkeys", "Nothing But Thieves", "Lupe Fiasco");
songs.zip(artists, (song, artist) -> String.format("%s by %s", song, artist))
.forEach(song -> System.out.println(song));
Our console output would be:
xxxxxxxxxx
505 by Arctic Monkeys
Amsterdam by Nothing But Thieves
Mural by Lupe Fiasco
Zip is one of the operations that isn't supported out of the box by Java, but that doesn't mean we cannot implement it ourselves. Java also provides a way for us to introduce new custom operations in a stream pipeline through the implementation of a stream source.
In this article, we're going to present some alternatives on how to implement the zip operation in Java. We are going to compare their features, measuring them against the four overheads listed above, as well as compatibility with Java's Stream. After that, we'll benchmark different queries using the different alternatives proposed and see how they fare against each other.
2. Java Zip Alternatives
There are multiple ways to set up a zip operation in Java, namely:
- Java's Stream extensibility
- Interleave a third-party utility such as
Streams(Guava) orStreamUtils(Protonpack) - Replace Stream by other kind of Sequence such as
Seq(jOOλ),Query(Jayield),StreamEx(StreamEx), orStream(Vavr) - Combine existing Java Stream operations -- zipline
2.1 Java's Stream Extensibility
In order to program and use custom Stream operations, Java provides the StreamSupport class, which provides methods to create streams out of a Spliterator. So, with the zip operation in mind, we implemented the solution proposed by siki over at stackoverflow.
Simply put, this solution obtains the iterators from the stream sources and combine their items into a new Iterator that is further converted to a Spliterator and then into a new Stream, as denoted in the following sketch:

Thus the Iterator resulting from the combination of elements and other is according to the following listing:
xxxxxxxxxx
Iterator<T> zippedIterator = new Iterator<T>() {
public boolean hasNext() {
return elements.hasNext() && other.hasNext();
}
public T next() {
return zipper.apply(elements.next(), other.next());
}
};
From this zippedIterator, siki's proposal obtains the final Stream from the following composition:
xxxxxxxxxx
StreamSupport.stream(Spliterators.spliterator(zippedIterator, ...)...)
Going back to the song's example, here's how we would use our newly defined zip operation:
xxxxxxxxxx
zip(
getSongs(),
getArtists(),
(song, artist) -> String.format("%s by %s", song, artist)
).forEach(song -> System.out.println(song));
This is the approach that Java currently provides. It has the advantage of not requiring any further libraries, but on the other hand it is quite verbose as we can see by the definition of the zip method proposed by siki over at StackOverflow that incurs in almost 35 lines of code. Moreover, when we are using our new custom operation we lost the fluent pipeline that stream operations provide, nesting our streams inside the method instead. Although the resulting pipeline is formed by getSongs() + getArtists() --> zip ---> forEach, the method calls are written in different order where zip() call appears at the head.
2.2. Interleaving with Third Party Utility Classes
Rather than developing our own zip function, we may use a third party utility library, making use of their operations interleaved with the Stream's method calls. This approach is provided by Protonpack with the StreamUtils class and by Guava with the Streams. Regarding the example of using our newly zip operation of previous section, we may replace the call to our own implementation of zip with the use of Streams.zip(...) or StreamUtils.zip(...) depending on whether we are using Guava's or Protonpack's utility class. This approach is much less verbose as we do not have to define the zip operation ourselves, but we do have to add a new dependency to our project if we want to use it.
2.3 Replacing Stream by Other Sequences
A Stream has the same properties as any other Sequence's pipeline. This pattern has been described before by Martin Fowler in his well-known article from 2015, "Collection Pipeline." A Sequence's pipeline is composed of a source, zero or more intermediate operations, and a terminal operation. Sources can be anything that provides access to a sequence of elements, like arrays or generator functions. Intermediate operations transform sequences into other sequences, such as filtering elements (e.g. filter(Predicate<T>)), transforming elements through a mapping function (map(Function<T,R>)), truncating the number of accessible elements (e.g. limit(int)), or using one of many other stream producing operations. Terminal operations are also known as value or side-effect-producing operations that ask for elements to operate, consuming the sequence. These operations include aggregations such as reduce() or collect(), searching with operations like findFirst() or anyMatch(), and iteration with forEach().
With that said there are some alternatives to Java's Stream's implementation of a Sequence, such as StreamEx, Query by Jayield, Seq by jOOλ or Stream by Vavr. Now let's take a look at how our example from "Java's Stream extensibility", behaves using Seq by jOOλ:
xxxxxxxxxx
Seq<String> songs = Seq.of("505", "Amsterdam", "Mural");
Seq<String> artists = Seq.of("Arctic Monkeys", "Nothing But Thieves", "Lupe Fiasco");
songs
.zip(artists)
.map((tuple) -> String.format("%s by %s", tuple.v1, tuple.v2))
.forEach(song -> System.out.println(song));
Replacing Stream by a third party implementation results in a similar usage to that one presented in our example, regardless the change of the sequence type, such as Seq in the case of the jOOλ library. This approach is similar in many ways to the one presented in "2.2 Interleaving with third party utility classes", with the added benefit of keeping the fluent pipeline of operations. Here the methods calls such as zip(), map() and foreach() are chained through a sequence of method calls where each call acts on the result of the previous calls.
2.4 Combine existing Java Stream operations -- zipline
One approach that does not require the usage of third party utility libraries nor breaks the fluent pipeline of operations when it comes to zipping two Sequences, is simply the combination of the Stream operation map with an old fashioned iterator.
Considering that we want to merge two sequences: elements and other (instances of Stream), then we can achieve our goal (denoted as the resulting zipline) with the following combination of native Stream operations:
xxxxxxxxxx
var o = other.iterator(); var zipline = elements.map(e -> Pair(e, o.next())));
Regarding our use case of zipping artists with songs, then using the zipline approach we may achieve our goal in the following listing:
xxxxxxxxxx
Iterator<String> artists = getArtists().iterator();
getSongs()
.map(song -> String.format("%s by %s", song, artists.next()))
.forEach(song -> System.out.println(song));
Zipline shares the fluency advantage of using a third-party sequences alternative, but with the additional benefit of not requiring a further dependency. Moreover, zipline is concise and avoids all the verbosity of implementing a custom Spliterator.
3. Feature Comparison
In this section, we present a table that gives an overview of the different approaches regarding the drawbacks described at the beginning of this article as well as their compatibility with Java Stream's. Concerning the performance, we include four benchmark results that present the speedup relative to the performance observed with the Java's Stream extensibility (the accepted answer proposal of the original Stackoverflow question about zip).
These four results deal with foure different query pipelines, namely the every() and find() operations mentioned in the Stackoverflow question about zip, and also 2 more complex pipelines processing data from Last.fm Web API, one including a distinct() and other a filter() over a zip. For these two latter results we present the speedup in percentage.
We will explain these operations in more detail in section "4. Domain model and queries for Benchmarking". This table groups different approaches by the same color that is used in performance results charts of section "Performance Evaluation" and according to the 4 choices presented in Section 2 - Java Zip Alternatives.
| Verboseless | 3r Party Free | Fluent | Stream Compatible |
every | find | distinct | filter | |
| Stream ext. | x | ✔ | x | NA | ||||
| Guava | ✔ | x | x | x | -1.1 | 1.1 | -1% | 2% |
| Protonpack | ✔ | x | x | x | -1.1 | 1.0 | -3% | 2% |
| StreamEx | ✔ | x | ✔ | ✔ | 1.0 | 1.0 | -11% | -6% |
| Jayield | ✔ | x | ✔ | toStream() | 3.4 | 2.9 | 11% | 37% |
| jOOλ | ✔ | x | ✔ | ✔ * | -1.3 | -1.2 | -23% | -16% |
| Vavr | ✔ | x | ✔ | toJavaStream() | -6.9 | -5.0 | -31% | -53% |
| Zipline | ✔ | ✔ | ✔ | NA | 1.5 | 1.1 | 8% | 3% |
(* Although Seq being compatible with Stream it does not support parallel processing.)
Comparing the approaches, we can see that the only one incurring in Verbosity is that one provided by the "2.1 Java's Stream extensibility", whereas all other approaches are Verboseless. Yet, all those alternatives depend of a Third Party library, with the exception of the Zipline idiom that is built over the existing Java Stream API.
On the other hand, replacing the Stream type by other Sequence implementation or even using the Zipline idiom we can maintain fluent pipelines.
The most performant approaches are Query by Jayield and Zipline as we'll confirm further ahead in our performance benchmark results. Although jOOλ and StreamEx present worse performance than competition they provide a full set of query operations and they are fully compatible with the Java Stream type. Finally, although Vavr is the most popular among these Github repositories it hasn't any advantage over the alternatives for the analyzed features and benchmarks.
4. Domain Model and Queries for Benchmarking
To test how each of these approaches would perform we decided to devise a couple of queries and benchmark them.
4.1 every and find
With the thought of the original Stackoverflow question in mind. We decided to benchmark these two operations as well, seeing as they are the focus of the question made by artella.
Every is an operation that, based on a user-defined predicate, tests if all the elements of a sequence match between corresponding positions. So for instance, if we have:
xxxxxxxxxx
Stream seq1 = Stream.of("505", "Amsterdam", "Mural");
Stream seq2 = Stream.of("505", "Amsterdam", "Mural");
Stream seq3 = Stream.of("Mural", "Amsterdam", "505");
BiPredicate pred = (s1, s2) -> s1.equals(s2);
Then:
xxxxxxxxxx
every(seq1, seq2, pred); // returns true
every(seq1, seq3, pred); // returns false
For every to return true, every element of each sequence must match in the same index. The every feature can be achieved through a pipeline of zip-allMatch operations, such as:
xxxxxxxxxx
seq1.zip(seq2, pred::test).allMatch(Boolean.TRUE::equals);
The find between two sequences is an operation that, based on a user defined predicate, finds two elements that match, returning one of them in the process. So if we have:
xxxxxxxxxx
Stream seq1 = Stream.of("505", "Amsterdam", "Mural");
Stream seq2 = Stream.of("400", "Amsterdam", "Stricken");
Stream seq3 = Stream.of("Amsterdam", "505", "Stricken");
BiPredicate pred = (s1, s2) -> s1.equals(s2);
Then:
xxxxxxxxxx
find(seq1, seq2, pred); // returns "Amsterdam"
find(seq1, seq3, pred); // returns null
find(seq2, seq3, pred); // returns "Stricken"
For find to return an element, two elements of each sequence must match in the same index. Here's what an implementation of find would look like with the support of a zip:
xxxxxxxxxx
zip(seq1, seq2, (t1, t2) -> predicate.test(t1, t2) ? t1 : null)
.filter(Objects::nonNull)
.findFirst()
.orElse(null);
As we can see, find is similar to every in the sense that both zip sequences using a predicate, and if we have a match on the last element of a sequence it runs through the entire sequence as every would. With this in mind, we decided that benchmarking find with sequences with many elements and matching it only in the last element would not add much value to this analysis. So we devised a benchmark in which the match index would vary from the first index up until the last and analysed sequences with 1000 elements only. On the other hand, we have benchmarked the every with sequences of 100 thousand elements.
4.2. Artists and Tracks
Looking for more complex pipelines with realistic data, we resort to publicly available Web APIs, namely REST Countries and Last.fm. We retrieved from the REST Countries a list of 250 countries which we then used to query the Last.fm API in order to retrieve both the top Artists as well as the top Tracks by country, leaving us with a total of 7500 entries for each.
Our domain model can be summarized into the following definition of these classes: Country, Language, Artist, and Track.

Both our queries come from the same basis. We first query all the countries, filter those that don't speak English and from there we retrieve two Sequences: one with the pairing of the Country and it's top Tracks other with the Country and it's top Artists.
xxxxxxxxxx
Sequence<Pair<Country, Sequence<Track>>> getTracks() {
return getCountries()
.filter(this::isNonEnglishSpeaking)
.map(country -> Pair.with(country, getTracksForCountry(country)));
}
Sequence<Pair<Country, Sequence<Artist>>> getArtists() {
return getCountries()
.filter(this::isNonEnglishSpeaking)
.map(country -> Pair.with(country, getArtistsForCountry(country)));
}
From here on out our queries diverge so we'll explain separately.
Distinct Top Artist and Top Track by Country
This query consists of zipping both Sequences described above into a Trio with the Country, it's top Artist and it's Top Track, then selecting the distinct entries by Artist.
xxxxxxxxxx
Sequence<Trio<Country,Artist,Track>> zipTopArtistAndTrackByCountry() {
return getArtists()
.zip(getTracks())
.map(pair -> Trio.with(
pair.first().country,
pair.first().artists.first(),
pair.second().tracks.first()
))
.distinctByKey(Trio::getArtist);
}
Artists Who Are in A Country's Top Ten Who Also Have Tracks in The Same Country's Top Ten.
As the previous query, this one starts by zipping both sequences, but this time, for each Country, we take the top ten Artists and top ten Track artist's names and zip them into a Trio. After, the top ten artists are filtered by their presence in the top ten Track artist's name, returning a Pair with the Country and the resulting Sequence.
xxxxxxxxxx
Sequence<Pair<Country,Sequence<Artist>>> artistsInTopTenWithTopTenTracksByCountry() {
return getArtists()
.zip(getTracks())
.map(pair -> Trio.with(
pair.first().country,
pair.first().artists.limit(10),
pair.second().tracks.limit(10)
.map(Track::getArtist)
.map(Artist::getName)
)).map(trio -> Pair.with(
trio.country,
trio.artists.filter(artist -> trio.tracksArtists.contains(artist.name))
));
}
Source Code
For the actual implementations of these queries you can always check our Github repository. You'll find that some of these methods and properties don't exist (first(), second(), country, etc...), but to make the concept clearer and easier to understand we used these properties in this article.
5. Performance Evaluation
To avoid IO operations during benchmark execution we have previously collected all data into resource files and we load all that data into in-memory data structures on benchmark bootstrap. Thus the streams sources are performed from memory and avoid any IO.
To compare the performance of the multiple approaches described above we benchmarked the two queries explained above with jmh. We ran these benchmarks both in a local machine as well as in GitHub, with GitHub actions, which presented consistent behavior and results with the performance tests collected locally.
Our local machine presents the following specs:
xxxxxxxxxx
Microsoft Windows 10 Home
10.0.18363 N/A Build 18363
Intel(R) Core(TM) i7-7700HQ CPU 2.80GHz, 2801 Mhz, 4 Core(s), 8 Logical Processor(s)
JDK 11.0.6, Java HotSpot(TM) 64-Bit Server VM, 11.0.6+8-LTS
The benchmarks were run both on our local machine and on github, with the following options passed to jmh:
-i 10 -wi 10 -f 3 -r 15 -w 20 --jvmArgs "-Xms2G -Xmx2G"
These options correspond to the following configuration:
-i 10- run 10 measurement iterations.-wi 10- run 10 warmup iterations.-f 3- fork each benchmark for 3 times.-r 15- spend at least 15 seconds ate each measurement iteration.-w 20- spend at least 20 seconds ate each warmup iteration.--jvmArgs "-Xms2G -Xmx2G"- set the initial and the maximum Java heap size to 2 Gb.
Local Machine results
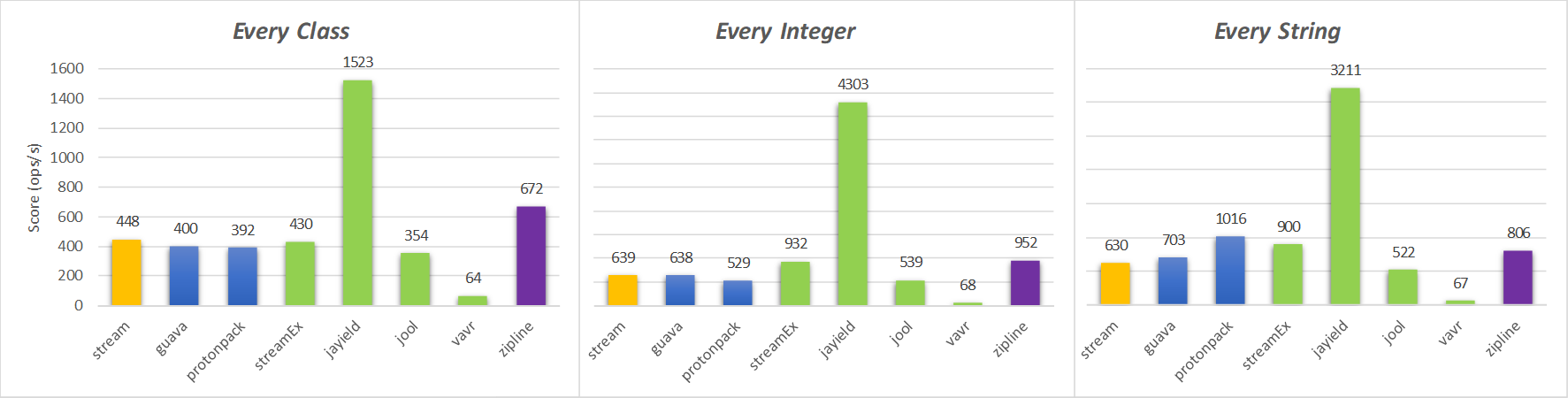

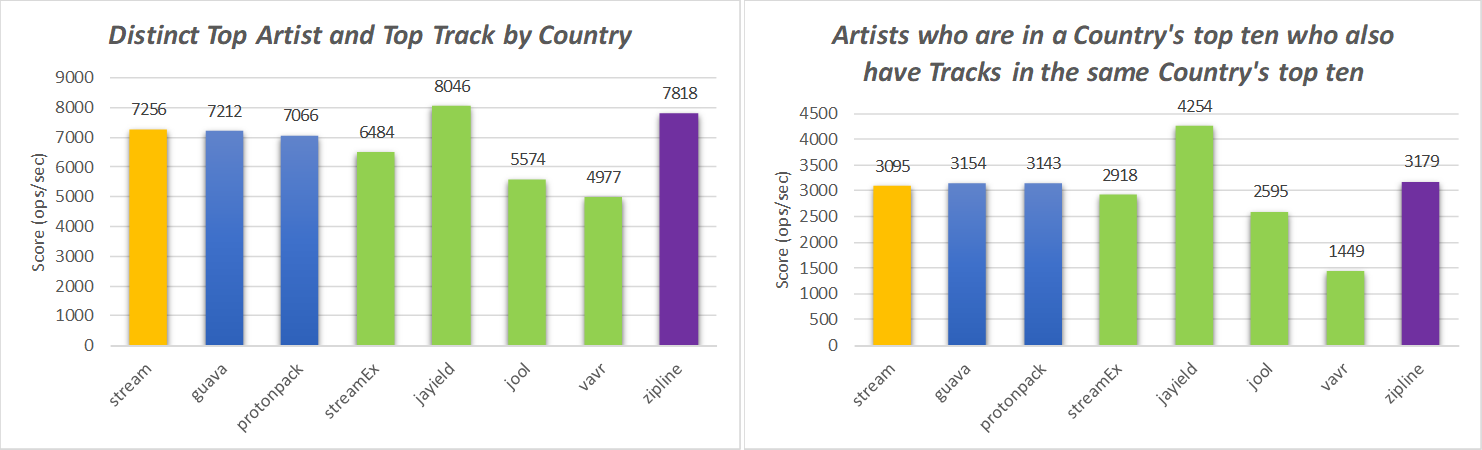
As we can observe from the results presented in these charts, the solution based on the accepted answer of Stackoverflow (labeled as "stream") is not the most performant option. Moreover, it has other drawbacks beyond performance already mentioned in previous sections.
The use of the third-party library Jayield outperforms all the other choices for both operations every() and find() mentioned by the original poster in StackOverflow's question about zipping Java streams. Although Jayield is also the most performant in Artists and Tracks benchmark, it presents a more subtle speedup over the competition.
Yet, if adding a dependency to an auxiliary library such as Jayield is not an option, then zipline will be the best alternative. It is simpler and more effective to chain a map() combined with the use of an auxiliary iterator, as denoted by zipline idiom, than implementing a Spliterator based zip, which incurs in a lot of verbosity. Furthermore, that zip() cannot be chained fluently in a stream pipeline, whereas the zipline keeps the fluent nature of the query pipeline. Finally, zipline is is the second most performant solution in most part of the analysed benchmarks.
StreamEx is also a good option that provides a full set of operations out of the box to build a wide variety of query pipelines. It has the big advantage of being fully compatible with Java stream classes. Yet, it presents a worse performance in comparison with Jayield.
jOOλ and Vavr are other options with the same goals of StreamEx but that are not able to compete in performance with other alternatives in the zip benchmarks.
Finally, the Guava and Protonpack options present similar performance to the Spliterator based zip. This is expected because these solutions are also based in the implementation of the Spliterator interface and thus they incur in the same overheads. So, the only advantage of these libraries is avoiding the verbosity of implementing the zip() from the scratch. Yet, both share the same drawbacks regarding the loss of the pipeline fluency and performance.
6. Conclusions
Java Streams are a masterpiece of software engineering, allowing querying and traversal of sequences, sequentially or in parallel. Nevertheless, it does not contain, nor could it, every single operation that will be needed for every use case. That is the case of the zip() operation.
In this article, we highlight other concerns regarding the choice of a workaround to suppress the absence of the zip() operation in Java streams. We argue that the most voted and accepted answer on StackOverflow is not the best choice and incurs in 3 drawbacks: verbosity, loss of pipeline fluency and underperformance.
We also proved that the 2nd an 3rd most voted answers of Stackoverflow, based on the use of third-party libraries, such as Guava and Protonpack also incur in similar overheads and are not the best choices.
We brought to our analysis other options, namely zipline idiom and Jayield library and we also have built a zip benchmark based on a realistic data source to fairly compare all alternatives. This benchmark is available on Github and the results are publicly visible in Github Actions.
We hope that all these results and evaluated characteristics can serve as a basis to help developers make their choice to suppress the absence of the zip operation.
References
Opinions expressed by DZone contributors are their own.
Comments