Bucket4j + Infinispan: A Deep Dive Into Implementation
This deep dive explores integrating Bucket4j with Embedded Infinispan to implement a distributed rate limiter with logic execution directly on the data-owning node.
Join the DZone community and get the full member experience.
Join For FreeIn distributed systems, the biggest challenge for rate limiting is state. How do you ensure that two parallel requests hitting different cluster nodes don't "double-spend" the same token?
In this article, we dive into the implementation details of the integration between the Bucket4j rate-limiting framework and Embedded Infinispan (not HotRod). This setup creates a data grid across different pods of a single application, allowing for seamless, distributed token management.
To keep this guide focused and readable, I have omitted some of the more granular implementation details.
Main Actors
The Embedded Infinispan Layer: Functional Map API
Infinispan is a high-performance key-value store designed for low latency. For Bucket4j, the most critical feature is the Functional Map API.
@Experimental
interface ReadWriteMap<K, V> extends FunctionalMap<K, V> {
...
}Unlike a standard cache.put(), the Functional Map allows us to execute a lambda (an Entry Processor) directly on the node that owns the data with a CAS guarantee. This approach offers three major advantages via ReadWriteMap.eval(key, entryProcessor):
- Atomicity: Locks are acquired before the lambda executes.
- Data locality: The function travels to the data, minimizing network traffic.
- Non-blocking: It returns a
CompletableFuture, fitting perfectly into modern asynchronous architectures.
The detailed jump into the implementation of Infinispan cache I think is very verbose and we can skip them for clarity of the flow.
The Bucket4j Layer: Abstraction and Proxies
Bucket
A Bucket is a stateful object that maintains a current balance of tokens and a set of rules (bandwidths) for how those tokens are consumed and refilled over time. It uses a Builder pattern to configure not just the bucket’s behavior, but also its execution model (how and where the logic is processed, we look at that later more precisely). It has a sibling, AsyncBucketProxy, which provides methods returning CompletableFuture objects. For the remainder of this article, when I refer to a 'bucket,' I am specifically referring to the AsyncBucketProxy.
For simplicity, we could pretend that it has the next method.
public interface AsyncBucketProxy {
CompletableFuture<Boolean> tryConsume(long numTokens);
}Of course, you could use the abstract implementation and initialize the object directly through a constructor. However, you have a better option — use the built-in builders, and your flow would look like this
Bucket.builder()
.addLimit(limit -> limit.capacity(50).refillGreedy(10, Duration.ofSeconds(1)))
.build();
// or
BucketConfiguration configuration = BucketConfiguration.builder()
.addLimit(limit -> limit.capacity(50).refillGreedy(10, Duration.ofSeconds(1)))
.build();
proxyManager
.builder()
.build("SYSTEM", () -> CompletableFuture.completedFuture(configuration));Pretty neat, right? While Bucket.builder() is responsible for building local buckets, the ProxyManager handles distributed buckets, and that is where things get interesting.
Proxy Manager
The ProxyManager interface (and its base implementation AbstractProxyManager) is the backbone of Bucket4j's distributed logic. It unifies the flow of building bucket behavior and delegates the execution to the specific implementations. To make this, Bucket4j internally uses Remote command and Request interfaces.
public interface RemoteCommand<T> {
CommandResult<T> execute(MutableBucketEntry mutableEntry, long currentTimeNanos);
}public class Request<T> implements ComparableByContent<Request<T>> {
//...... omit for clarity
private final RemoteCommand<T> command;
public Request(RemoteCommand<T> command,
//...... omit for clarity) {
this.command = command;
}
//...... omit for clarity
} With a "Remote command" interface, we could wrap and execute any operation on data on the remote server. But we don't have an actor that executes this command: CommandExecutor (AsyncCommandExecutor for AsyncBucket).
AbstractProxyManager creates this object inside and enriches the bucket with the implementation. Look at the example below.
@Override
public AsyncBucketProxy build(K key, Supplier<CompletableFuture<BucketConfiguration>> configurationSupplier) {
if (configurationSupplier == null) {
throw BucketExceptions.nullConfigurationSupplier();
}
AsyncCommandExecutor commandExecutor = new AsyncCommandExecutor() {
@Override
public <T> CompletableFuture<CommandResult<T>> executeAsync(RemoteCommand<T> command) {
ExpirationAfterWriteStrategy expirationStrategy = clientSideConfig.getExpirationAfterWriteStrategy().orElse(null);
Request<T> request = new Request<>(command, getBackwardCompatibilityVersion(), getClientSideTime(), expirationStrategy);
// Pay attention!
Supplier<CompletableFuture<CommandResult<T>>> futureSupplier = () -> AbstractProxyManager.this.executeAsync(key, request);
return clientSideConfig.getExecutionStrategy().executeAsync(futureSupplier);
}
};
commandExecutor = asyncRequestOptimizer.apply(commandExecutor);
return new DefaultAsyncBucketProxy(commandExecutor, recoveryStrategy, configurationSupplier, implicitConfigurationReplacement, listener);
}executeAsync to the ProxyManager, Bucket4j separates the rate-limiting logic from the underlying storage technology. This is why the same library can support Redis, Postgres, or Infinispan just by switching the manager.
With this knowledge, we could jump into the InfinispanProxyManager to look at the details.
Infinispan Proxy Manager
The first thing to note in the documentation is that Bucket4j requires specific serialization for Infinispan. This is crucial because Infinispan operates on byte streams. (below, part of documentation).
import io.github.bucket4j.grid.infinispan.serialization.Bucket4jProtobufContextInitializer;
import org.infinispan.configuration.global.GlobalConfigurationBuilder;
...
GlobalConfigurationBuilder builder = new GlobalConfigurationBuilder();
builder.serialization().addContextInitializer(new Bucket4jProtobufContextInitializer());However, our focus should be on the implementation of execution. Let's have a look at this.
@Override
public <T> CompletableFuture<CommandResult<T>> executeAsync(K key, Request<T> request) {
try {
InfinispanProcessor<K, T> entryProcessor = new InfinispanProcessor<>(request);
CompletableFuture<byte[]> resultFuture = readWriteMap.eval(key, entryProcessor);
return resultFuture.thenApply(resultBytes -> deserializeResult(resultBytes, request.getBackwardCompatibilityVersion()));
} catch (Throwable t) {
CompletableFuture<CommandResult<T>> fail = new CompletableFuture<>();
fail.completeExceptionally(t);
return fail;
}
}
@Override
public <T> CommandResult<T> execute(K key, Request<T> request) {
// sync copy of executeAsync
}And here we see a special InfinispanProcessor<K, T>. What secrets could we find inside?
import io.github.bucket4j.distributed.remote.AbstractBinaryTransaction;
import io.github.bucket4j.distributed.remote.RemoteBucketState;
import io.github.bucket4j.distributed.remote.Request;
import io.github.bucket4j.distributed.serialization.InternalSerializationHelper;
import io.github.bucket4j.util.ComparableByContent;
import org.infinispan.functional.EntryView;
import org.infinispan.functional.MetaParam;
import org.infinispan.util.function.SerializableFunction;
public class InfinispanProcessor<K, R> implements
SerializableFunction<EntryView.ReadWriteEntryView<K, byte[]>, byte[]>,
ComparableByContent<InfinispanProcessor> {
public InfinispanProcessor(Request<R> request) {
this.requestBytes = InternalSerializationHelper.serializeRequest(request);
}
//... omitted for clarity
public byte[] apply(EntryView.ReadWriteEntryView<K, byte[]> entry) {
if (requestBytes.length == 0) {
// it is the marker to remove bucket state
if (entry.find().isPresent()) {
entry.remove();
return new byte[0];
}
}
return new AbstractBinaryTransaction(requestBytes) {
// ... omitted for clarity
@Override
protected void setRawState(byte[] newStateBytes, RemoteBucketState newState) {
ExpirationAfterWriteStrategy expirationStrategy = getExpirationStrategy();
long ttlMillis = expirationStrategy == null ? -1 : expirationStrategy.calculateTimeToLiveMillis(newState, getCurrentTimeNanos());
if (ttlMillis > 0) {
entry.set(newStateBytes, new MetaParam.MetaLifespan(ttlMillis));
} else {
entry.set(newStateBytes);
}
}
}.execute();
}
}And here is the trick to integrate Infinispan and Bucket4j: SerializableFunction<EntryView.ReadWriteEntryView<K, byte[]>, byte[]>. This is a special interface that allows the system to ship a function to a different node to execute arbitrary code. Infinispan accepts this serializable function and executes it on the remote node where the data actually resides.
InfinispanProcessor will fail to deserialize on the owner node.
So, there is still uncertainty about what is inside AbstractBinaryTransaction.execute(). Let's dive into the code.
public byte[] execute() {
// ... logic to deserialize request ...
try {
RemoteBucketState currentState = null;
if (exists()) {
byte[] stateBytes = getRawState(); // get state on the node
currentState = deserializeState(stateBytes);
}
MutableBucketEntry entryWrapper = new MutableBucketEntry(currentState);
currentTimeNanos = request.getClientSideTime() != null ?
request.getClientSideTime(): System.currentTimeMillis() * 1_000_000;
RemoteCommand<?> command = request.getCommand();
CommandResult<?> result = command.execute(entryWrapper, currentTimeNanos);
if (entryWrapper.isStateModified()) {
RemoteBucketState newState = entryWrapper.get();
setRawState(serializeState(newState, backwardCompatibilityVersion), newState);
}
return serializeResult(result, request.getBackwardCompatibilityVersion());
}
// omit for clarity
}In this part of the code, we see execution logic that is involved on the remote server and compute - does the request have enough tokens to come further, or should it be repeated?
Execution Flow
Previously, the main parts of algorithms were introduced, and we are ready to combine them to get the final view of how we get the final answer to the question: could we consume tokens or not?
As discussed, a lot of magic hides in the building phase by wrapping CommandExecutor and Requests on the ProxyManager level, and let's unwrap this envelope and show what's happening in integration.
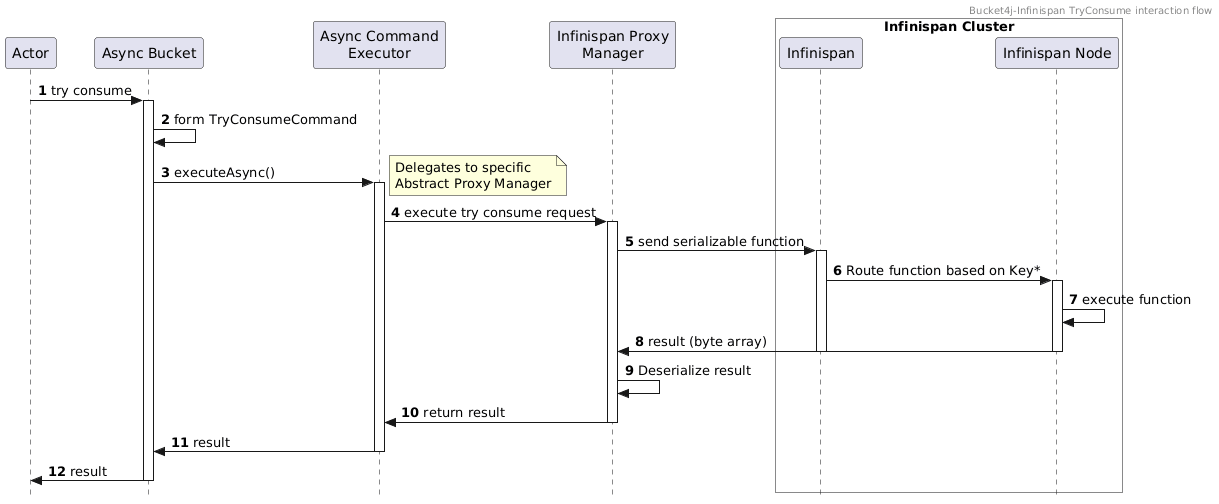
*Key - Infinispan uses the Consistent Hashing technique inside.
Summary
Integrating Bucket4j with Embedded Infinispan offers a sophisticated solution for distributed rate limiting by moving logic to the data.
- Data locality: By using
readWriteMap.eval(), the rate-limiting decision is executed directly on the node that owns the bucket's state, minimizing network hops. - Atomic consistency: Infinispan ensures that the
InfinispanProcessorruns with strict atomicity and CAS guarantees, solving the "double-spend" problem without heavy distributed locks. - Performance: Operating at the
byte[]level ensures that state transitions are extremely fast and the memory footprint remains small.
For production, ensure cluster homogeneity: Your Bucket4j versions and application bytecode must be identical across all pods to avoid serialization errors. This setup allows you to build a self-contained, high-performance rate-limiting grid that scales horizontally with your application.
Opinions expressed by DZone contributors are their own.
Comments