How to Provide Rate-Limiting Via Bucket4j in Java
Every now and again, all of us face a problem with limiting our external API. The following article will serve as a tutorial to help solve this issue.
Join the DZone community and get the full member experience.
Join For FreeHello, everyone. Today, I want to show how you can provide rate-limiting into your project based on the Token Bucket algorithm via Bucket4j.
Every now and again, all of us face a problem with limiting our external API -- some functionality where we should limit calling to our API for many reasons.
Where Is It Needed?
- Fraud detection (Protection from Bots): For example, we have a forum and we want to prevent spam from customers when somebody is trying to send messages or publish posts beyond the limit. For our own safety, we must prevent this behavior.
- From the point of business logic, usually, it is used to realize the “API Business Model:" For example, we need to introduce tarification functionality for our external API, and we want to create a few tariffs such as START, STANDARD, BUSINESS. For each tariff, we set a call count limit per hour (but you can also rate-limit calls to once per minute, second, millisecond, or you can set per a few mins. Also, you can even set more than one limit restriction - this is called “Bandwidth management”).
- START - up to 100 calls per hour
- STANDARD - up to 10000 per hour
- BUSINESS - up to 100000 per hour
There are many other reasons to use rate-limiting for our project.
In order to realize rate-limiting, we can use many popular algorithms such as the below.
The most popular:
- Token bucket (link to wiki)
- Leaky bucket (link to wiki)
The least popular:
- Fixed window counter
- Sliding window log
- Sliding window counter
But, in this article, we will talk only about the “Token Bucket” algorithm.
An Explanation of the "Token Bucket" Algorithm
Let’s consider this algorithm in the next example.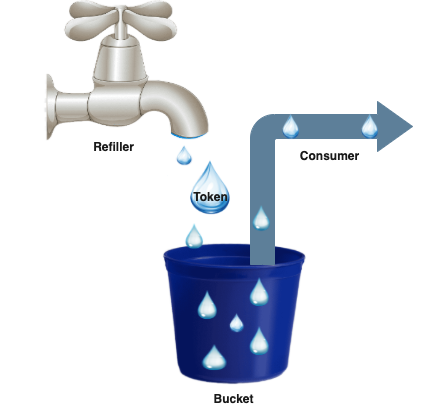
- Bucket: As you can see, he has a fixed volume of tokens (if you set 1000 tokens into our bucket, this is the maximum value of volume).
- Refiller: Regularly fills missing tokens based on bandwidth management to Bucket (calling every time before Consume).
- Consume: Takes away tokens from our Bucket (take away 1 token or many tokens -- usually it depends on the weight of calling consume method, it is a customizable and flexible variable, but in 99% of cases, we need to consume only one token).
Below, you can see an example of a refiller working with Bandwidth management to refresh tokens every minute:
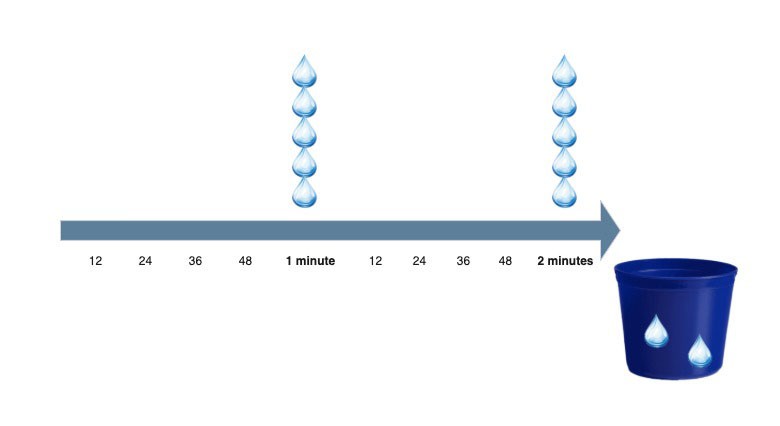 Consume (as action) takes away Tokens from Bucket.
Consume (as action) takes away Tokens from Bucket.
The bucket is needed for storing a current count of Tokens, maximum possible count of tokens, and refresh time to generate a new token.
The Token Bucket algorithm has fixed memory for storing Bucket, and it consists of the following variables:
- The volume of Bucket (maximum possible count of tokens) - 8 bytes
- The current count of tokens in a bucket - 8 bytes
- The count of nanoseconds for generating a new token - 8 bytes
- The header of the object: 16 bytes
In total: 40 bytes
For example, in one gigabyte, we can store 25 million buckets. It’s very important to know because, usually, we store information about our buckets in caches and consequently into RAM (Random Access Memory).
The Disadvantage of the Algorithm
Unfortunately, the algorithm is not perfect. The main problem of the Token Bucket algorithm is called “Burst."
I’ll show the problem with a perfect example to short explain the idea:
- At some moments, our bucket contains 100 tokens.
- At the same time, we consume 100 tokens.
- After one second, the refiller again fills 100 tokens.
- At the same time, we consume 100 tokens.
By ~1 second we consumed 200 tokens and accordingly, we exceeded the limit x2 times!
But, is it a problem? Nope! The problem is not the problem if we're gonna use Bucket for long-term distance.
If we use our Bucket for only one second, we are over-consuming tokens x2 times (200 tokens), but if we use our bucket for 60 seconds, consumption of the bucket is equal to about 6100 seconds because the Burst problem happened only once. The more you use the bucket, the better it is for its accuracy. It’s a very rare situation when accuracy is important in rate-limiting.
The most important is consuming memory because we have a problem related to “Burst." A bucket has a requirement about fixed memory size (in case of Token Bucket algorithm - 40 bytes), and we face a problem of “Burst” because to create Bucket we need 2 variables: count of nanoseconds to generate a new token (refill) and volume of a bucket (capacity) -- because of that, we can’t realize accuracy contract of Token Bucket.
Realizing Rate-Limiter Via Bucket4j
Let’s consider the Token Bucket algorithm implemented by the Bucket4j library.
Bucket4j is the most popular library in Java-World for realizing rate-limiting features. Every month, Bucket4j downloads up to 200,000 times from Maven Central and is contained in 3500 dependencies on GitHub.
Let’s consider a few simple examples (we’ll use Maven as a software project management and comprehension tool).
For the first one, we need to add a dependency to pom.xml:
<dependency>
<groupId>com.github.vladimir-bukhtoyarov</groupId>
<artifactId>bucket4j-core</artifactId>
<version>7.0.0</version>
</dependency>
Create Example.java:
import io.github.bucket4j.Bandwidth;
import io.github.bucket4j.Bucket;
import io.github.bucket4j.Bucket4j;
import io.github.bucket4j.ConsumptionProbe;
import java.time.Duration;
public class Example {
public static void main(String args[]) {
//Create the Bandwidth to set the rule - one token per minute
Bandwidth oneCosumePerMinuteLimit = Bandwidth.simple(1, Duration.ofMinutes(1));
//Create the Bucket and set the Bandwidth which we created above
Bucket bucket = Bucket.builder()
.addLimit(oneCosumePerMinuteLimit)
.build();
//Call method tryConsume to set count of Tokens to take from the Bucket,
//returns boolean, if true - consume successful and the Bucket had enough Tokens inside Bucket to execute method tryConsume
System.out.println(bucket.tryConsume(1)); //return true
//Call method tryConsumeAndReturnRemaining and set count of Tokens to take from the Bucket
//Returns ConsumptionProbe, which include much more information than tryConsume, such as the
//isConsumed - is method consume successful performed or not, if true - is successful
//getRemainingTokens - count of remaining Tokens
//getNanosToWaitForRefill - Time in nanoseconds to refill Tokens in our Bucket
ConsumptionProbe consumptionProbe = bucket.tryConsumeAndReturnRemaining(1);
System.out.println(consumptionProbe.isConsumed()); //return false since we have already called method tryConsume, but Bandwidth has a limit with rule - one token per one minute
System.out.println(consumptionProbe.getRemainingTokens()); //return 0, since we have already consumed all of the Tokens
System.out.println(consumptionProbe.getNanosToWaitForRefill()); //Return around 60000000000 nanoseconds
}
Ok, I think it looks easy and understandable!
Let's consider a more difficult example. Let’s imagine a situation where you need to consider a restriction by a count of requests to some RESTful API method (need to restrict by counts of request calls from some user for some controller, no more than X times per Y period). But, our system is distributed and we have many notes inside a cluster; we use Hazelcast (but it can be, any JSR107 cache, DynamoDB, Redis, or something else).
Let’s implement our example based on the Spring framework.
To start, we need to add a few dependencies into pom.xml:
<dependency>
<groupId>com.github.vladimir-bukhtoyarov</groupId>
<artifactId>bucket4j-hazelcast</artifactId>
<version>7.0.0</version>
</dependency>
<dependency>
<groupId>javax.cache</groupId>
<artifactId>cache-api</artifactId>
<version>1.0.0</version>
</dependency>
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast</artifactId>
<version>4.0.2</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.20</version>
<scope>provided</scope>
</dependency>
For the next step, we should consider an annotation to use on the level of a controller in the future:
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
@Documented
public @interface RateLimiter {
TimeUnit timeUnit() default TimeUnit.MINUTES;
long timeValue();
long restriction();
}
Also, the annotation will group RateLimiter annotations (if we need to use more than one Bandwidth per one controller).
import java.lang.annotation.*;
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
@Documented
public @interface RateLimiters {
RateLimiter[] value();
}
Also, need to add a new type of data:
public enum TimeUnit {
MINUTES, HOURS
}
And, now, we need to create a class, which will do annotation processing. Since an annotation will be set on the level of the controller, the class should extend from HandlerInterceptorAdapter:
public class RateLimiterAnnotationHandlerInterceptorAdapter extends HandlerInterceptorAdapter {
//You should have already realized class, which returns Authentication context to getting userId
private AuthenticationUtil authenticationUtil;
private final ProxyManager<RateLimiterKey> proxyManager;
@Autowired
public RateLimiterAnnotationHandlerInterceptorAdapter(AuthenticationUtil authenticationUtil, HazelcastInstance hazelcastInstance) {
this.authenticationUtil = authenticationUtil;
//To start work with Hazelcast, you also should create HazelcastInstance bean
IMap<RateLimiterKey, byte[]> bucketsMap = hazelcastInstance.getMap(HazelcastFrontConfiguration.RATE_LIMITER_BUCKET);
proxyManager = new HazelcastProxyManager<>(bucketsMap);
}
@Override
public boolean preHandle(HttpServletRequest request,
HttpServletResponse response,
Object handler) throws Exception {
if (handler instanceof HandlerMethod) {
HandlerMethod handlerMethod = (HandlerMethod) handler;
//if into handlerMethod is present RateLimiter or RateLimiters annotation, we get it, if not, we get empty Optional
Optional<List<RateLimiter>> rateLimiters = RateLimiterUtils.getRateLimiters(handlerMethod);
if (rateLimiters.isPresent()) {
//Get path from RequestMapping annotation(respectively we can get annotations such: GetMapping, PostMapping, PutMapping, DeleteMapping, because all of than annotations are extended from RequestMapping)
RequestMapping requestMapping = handlerMethod.getMethodAnnotation(RequestMapping.class);
//To get unique key we use bundle of 2-x values: path from RequestMapping and user id
RateLimiterKey key = new RateLimiterKey(authenticationUtil.getPersonId(), requestMapping.value());
//Further we set key in proxy to get Bucket from cache or create a new Bucket
Bucket bucket = proxyManager.builder().build(key, () -> RateLimiterUtils.rateLimiterAnnotationsToBucketConfiguration(rateLimiters.get()));
//Try to consume token, if we don’t do that, we return 429 HTTP code
if (!bucket.tryConsume(1)) {
response.setStatus(429);
return false;
}
}
}
return true;
}
To work with Hazelcast, we need to create a custom key that must be serializable:
@Data
@AllArgsConstructor
public class RateLimiterKey implements Serializable {
private String userId;
private String[] uri;
}
Also, don’t forget the special util named RateLimiterUtils class for working with RateLimiterAnnotationHandlerInterceptorAdapter (Spring name convention-style -- name your class or method as must as understandable, even if in your name of something consist of 10 words. It's my go-to style).
public final class RateLimiterUtils {
public static BucketConfiguration rateLimiterAnnotationsToBucketConfiguration(List<RateLimiter> rateLimiters) {
ConfigurationBuilder configBuilder = Bucket4j.configurationBuilder();
rateLimiters.stream().forEach(limiter -> configBuilder.addLimit(buildBandwidth(limiter)));
return configBuilder.build();
}
public static Optional<List<RateLimiter>> getRateLimiters(HandlerMethod handlerMethod) {
RateLimiters rateLimitersAnnotation = handlerMethod.getMethodAnnotation(RateLimiters.class);
if(rateLimitersAnnotation != null) {
return Optional.of(Arrays.asList(rateLimitersAnnotation.value()));
}
RateLimiter rateLimiterAnnotation = handlerMethod.getMethodAnnotation(RateLimiter.class);
if(rateLimiterAnnotation != null) {
return Optional.of(Arrays.asList(rateLimiterAnnotation));
}
return Optional.empty();
}
private static final Bandwidth buildBandwidth(RateLimiter rateLimiter) {
TimeUnit timeUnit = rateLimiter.timeUnit();
long timeValue = rateLimiter.timeValue();
long restriction = rateLimiter.restriction();
if (TimeUnit.MINUTES.equals(timeUnit)) {
return Bandwidth.simple(restriction, Duration.ofMinutes(timeValue));
} else if (TimeUnit.HOURS.equals(timeUnit)) {
return Bandwidth.simple(restriction, Duration.ofHours(timeValue));
} else {
return Bandwidth.simple(5000, Duration.ofHours(1));
}
}
}
One more thing; we need to register our custom interceptor in Context which extends from WebMvcConfigurerAdapter:
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.InterceptorRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurerAdapter;
@Configuration
public class ContextConfig extends WebMvcConfigurerAdapter {
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new RateLimiterAnnotationHandlerInterceptorAdapter());
}
}
Now, to test our mechanism, we are going to create ExampleController and set RateLimiter above method of the controller to check if it's working correctly:
import com.nibado.example.customargumentspring.component.RateLimiter;
import com.nibado.example.customargumentspring.component.RateLimiters;
import com.nibado.example.customargumentspring.component.TimeUnit;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class ExampleController {
@RateLimiters({@RateLimiter(timeUnit = TimeUnit.MINUTES, timeValue = 1, restriction = 2), @RateLimiter(timeUnit = TimeUnit.HOURS, timeValue = 1, restriction = 5)})
@GetMapping("/example/{id}")
public String example(@PathVariable("id") String id) {
return "ok";
}
}Into @RateLimiters we set two restrictions:
- @RateLimiter(timeUnit = TimeUnit.MINUTES, timeValue = 1, restriction = 2) — no more than 2 requests per minute.
- @RateLimiter(timeUnit = TimeUnit.HOURS, timeValue = 1, restriction = 5) — no more than 5 requests per hour.
This is only a small part of the Bucket4j library. You can learn about other features here.
Opinions expressed by DZone contributors are their own.
Comments