Can We Build Elite Search Agents Without Massive Industrial RL Pipelines?
OpenSeeker-v2 is intended to push the limits of search agents working with informative and also high-difficulty trajectories.
Join the DZone community and get the full member experience.
Join For FreeSearch agents have become essential infrastructure for frontier language models, yet their development remains locked behind corporate walls. These systems need to handle a fundamentally difficult problem: given access to tools and a knowledge base, explore systematically, make smart decisions about which paths to pursue, and know when to pivot strategies. Unlike a human researcher who can draw on intuition and common sense, an LLM agent works from what it's learned during training, which means it needs explicit instruction in how to search well.
The practical stakes are high. Search agents' power research tools, web-based reasoning systems, and complex information retrieval. But most breakthroughs happen inside companies with unlimited budgets. Academic researchers hit a wall: the techniques that work are proprietary, the datasets are private, and the computational resources required seem astronomical. This creates a frustrating bottleneck where innovation clusters around industrial research labs, leaving the broader research community unable to experiment, iterate, or contribute meaningfully to the field.
Why Industrial Pipelines Felt Inevitable
The prevailing wisdom emerged naturally from how major AI labs approached agent training. They borrowed techniques from large language model development: start with massive pre-training to build foundational knowledge, apply continuous pre-training to adapt that foundation to new domains, fine-tune on supervised examples to teach specific behaviors, then polish everything with reinforcement learning to optimize against reward signals. Each stage supposedly unlocks something the previous stage couldn't reach.
The logic seemed bulletproof. If you want frontier-level capabilities, you need frontier-level methods and resources. Pre-training builds knowledge. Continuous pre-training specializes it. Supervised fine-tuning teaches specific skills. Reinforcement learning optimizes for actual performance. Remove any link in this chain, and you'd expect degradation.
This assumption led to a clear conclusion: building state-of-the-art search agents required industrial-scale infrastructure. Tongyi DeepResearch, for example, achieved strong performance through exactly this pipeline, spending enormous computational resources across all four optimization stages. For any academic team or resource-constrained organization, this seemed like an insurmountable barrier.
The Dataset Design Revolution
Then came a simpler observation: what if the bottleneck wasn't the algorithm, but what data you fed it?
The researchers behind OpenSeeker-v2 noticed something crucial. Most work on agent training focused on optimization techniques, assuming the data was a fixed quantity. But what if the data itself could be fundamentally restructured? What if you could take the same training paradigm (simple supervised fine-tuning) and make it exponentially more powerful just by changing which trajectories you used as examples?
This insight reframes the entire problem. Instead of asking "how do we squeeze more signal out of expensive optimization," ask "what makes a trajectory worth learning from?" Some trajectories teach the agent to think strategically. Others are lucky guesses that teach nothing. Some expose the agent to decision points where multiple tools could apply. Others are straightforward execution of a predetermined path.
The team introduced three modifications to their data synthesis process, each targeting a specific dimension of training data quality.
Scaling the knowledge graph means agents encounter richer search spaces during training. Instead of a small, constrained domain, they face larger graphs with more branches and exploration options. This prevents agents from memorizing solutions and forces them to develop genuine decision-making principles. A larger knowledge graph means each training trajectory involves more meaningful choices.
Expanding the tool set requires agents to learn judgment. When an agent has only a few tools, it can succeed through trial and error on the same limited options. With a larger toolkit, the agent must actually reason about which tool fits which problem. This teaches generalization rather than reflexes. The agent learns principles of tool selection instead of pattern-matching to familiar scenarios.
Strict low-step filtering focuses on trajectories that require careful planning rather than lucky guesses. A trajectory solving a problem in two steps teaches little about strategic reasoning. A trajectory requiring eight thoughtful steps teaches the agent to think systematically. By filtering strictly for solutions requiring multiple steps, researchers ensured every example was a lesson in strategic thinking, not an accident.
The result was deceptively small: 10.6k training examples. This number matters precisely because it seems impossible. A pre-trained language model might use billions of tokens. Industrial fine-tuning typically involves hundreds of thousands of examples. Yet 10.6k examples, when carefully structured around these three principles, proved sufficient to outperform systems trained with vastly more data and computational resources.
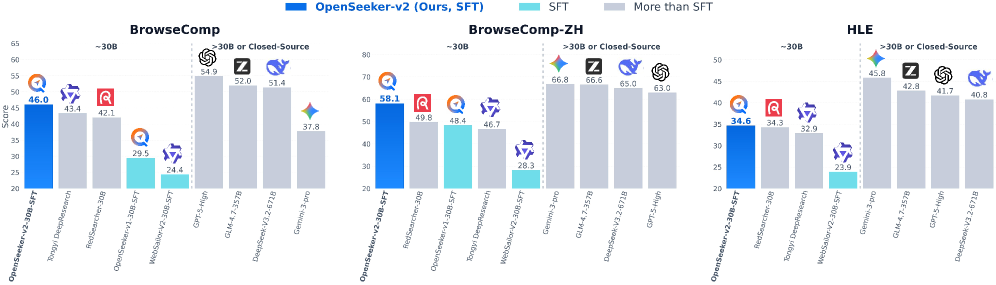
Testing Against the Real Competition
Theory means nothing without empirical validation. The team tested OpenSeeker-v2 against standardized benchmarks where it faced comparison with systems trained using industrial pipelines.
On BrowseComp, a benchmark testing web search and reasoning about real-time information, OpenSeeker-v2 achieved 46.0% accuracy compared to Tongyi DeepResearch's 43.4%. On BrowseComp-ZH, the same benchmark in Chinese, the gap widened to 58.1% versus 46.7%, demonstrating superior generalization across languages. On Humanity's Last Exam, a genuinely difficult benchmark requiring deep reasoning, OpenSeeker-v2 scored 34.6% to Tongyi's 32.9%. On xbench, a comprehensive benchmark of search capabilities, the difference was 78.0% versus 75.0%.
These aren't marginal victories achieved through luck or benchmark overfitting. They're consistent wins across diverse evaluation metrics, with particularly striking results on the multilingual benchmark. A 30B model trained only with supervised fine-tuning on 10.6k examples outperformed a system built with "heavy CPT+SFT+RL pipeline," to quote the paper's own comparison.
The significance of this finding inverts the conventional hierarchy. In AI development, more resources usually beat fewer resources. Better optimization techniques usually beat simpler ones. Yet here, a system constrained by deliberate dataset curation beat a system built with computational abundance. This suggests the constraint wasn't actually computational or algorithmic at all. It was conceptual, understanding what makes training data actually teach something valuable.
Why This Opens Doors for Everyone
The deeper implication extends beyond OpenSeeker-v2's specific numbers. The research demonstrates that a different path to frontier capabilities exists.
Industrial teams with unlimited budgets can always outspend competitors. But a discovery that "data curation beats computational resources" shifts the entire economic structure of AI development. If you're thoughtful about which 10,000 examples you use, you don't need billion-dollar infrastructure. You need domain expertise, careful thinking, and clear principles about dataset design. This is something accessible to academic teams, startups, and researchers in resource-constrained regions.
The work also sits in a broader context. Earlier approaches like OpenResearcher explored fully open pipelines for agent research, while Points Seeker examined multimodal search agents. OpenSeeker-v2's contribution is orthogonal: it shows that even within simpler architectures and paradigms, strategic dataset design enables frontier performance. This connects to broader observations about deep information seeking, suggesting that search capability improvements come from better data and clearer reasoning structures, not just more compute.
Accessibility matters here because it enables reproducibility. Unlike industrial systems trained with proprietary methods on private data, OpenSeeker-v2 is open-sourced with transparent methodology. The community can examine it, build on it, and improve the dataset design principles. This creates a feedback loop where the field collectively discovers what makes training data valuable.
The research also opens new questions. Can these curation principles apply to other domains beyond search agents? Does data quality multiply the efficiency of any LLM training task? Could other research groups develop improved versions of OpenSeeker-v2 by applying fresh insights about trajectory design? These questions now seem answerable rather than theoretical.
Most importantly, the work reshapes how the field thinks about scaling. Sometimes the bottleneck in AI development isn't algorithmic innovation or computational power. It's understanding what signal matters most. OpenSeeker-v2 teaches that lesson in a way the broader research community can actually apply, not as a one-off engineering achievement but as a principle about how to think about training data.
Published at DZone with permission of mike labs. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments