Graph-Based Recommendation System With Milvus
In this article, we discuss how to build a graph-based recommendation system by using PinSage (a GCN algorithm), DGL package, MovieLens datasets, and Milvus.
Join the DZone community and get the full member experience.
Join For FreeBackground
A recommendation system (RS) can identify user preferences based on their historical data and suggest products or items to them accordingly. Companies will enjoy considerable economic benefits from a well-designed recommendation system.
There are three elements in a complete set of recommendation systems: user model, object model, and the core element—recommendation algorithm. Currently, established algorithms include collaborative filtering, implicit semantic modeling, graph-based modeling, combined recommendation, and more. In this article, we will provide some brief instructions on how to use Milvus to build a graph-based recommendation system.
Key Techniques
Graph Convolutional Neural (GCN) Networks
PinSage
Users tag contents to their interest (pins) and related categories (boards) on Pinterest’s website, accumulating 2 billion pins, 1 billion boards, and 18 billion edges (an edge is created only when the pin falls into a specific board). The following illustration is a pins-boards bipartite graph.
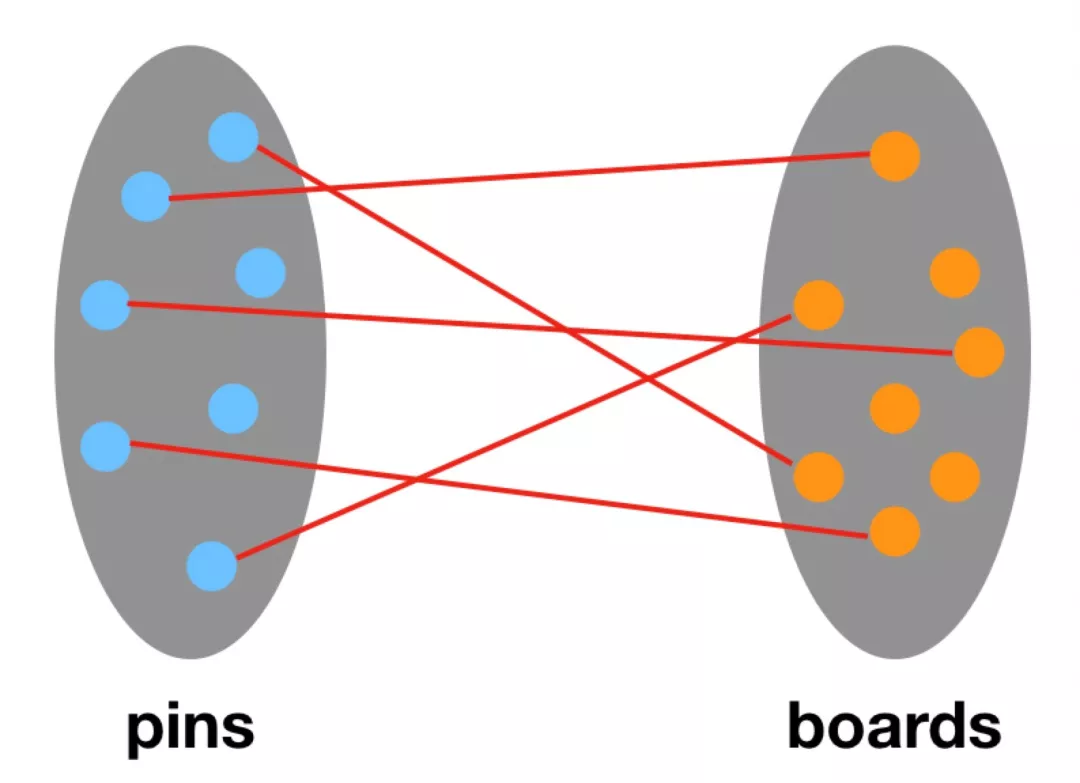
PinSage uses pins-boards bipartite graph to generate high-quality embeddings from pins for recommendations tasks such as pins recommendation. It has three key innovations:
- Dynamic convolutions: Unlike the traditional GCN algorithms, which perform convolutions on the feature matrices and the full graph, PinSage samples the neighborhood of the nodes, and performs more efficient local convolutions through dynamic construction of the computational graph.
- Constructing convolutions with random walk modeling: Performing convolutions on the entire neighborhood of the node will result in a massive computational graph. To reduce the computation required, traditional GCN algorithms examine k-hop neighbors; PinSage simulates a random walk to set the highly-visited contents as the key neighborhood and constructs a convolution based on it.
- Efficient MapReduce inference: Performing local convolution on nodes takes with it the problem of repeated computation. This is because the k-hop neighborhood overlaps. In each aggregate step, PinSage maps all nodes without repeated calculation, links them to the corresponding upper-level nodes, and then retrieves the embeddings of the upper-level nodes.
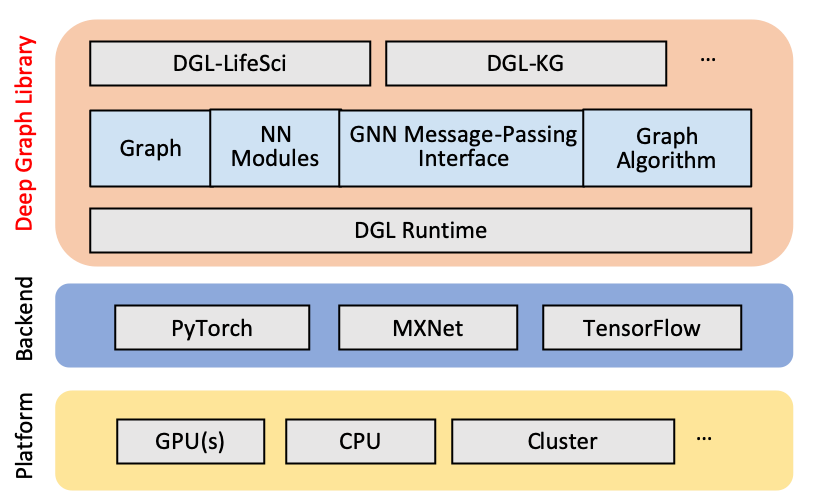
DGL
Deep Graph Library is a Python package designed for building graph-based neural network models on top of existing deep learning frameworks, such as PyTorch, MXNet, Gluon, and more. With its easy-to-use backend interfaces, DGL can be readily implanted into frameworks that are based on tensor and supporting auto-generation. The PinSage algorithm that this article is dealing with is optimized based on DGL and PyTorch.
Milvus
The next thing to obtaining embeddings is to conduct a similarity search in these embeddings to find items that might be of interest.
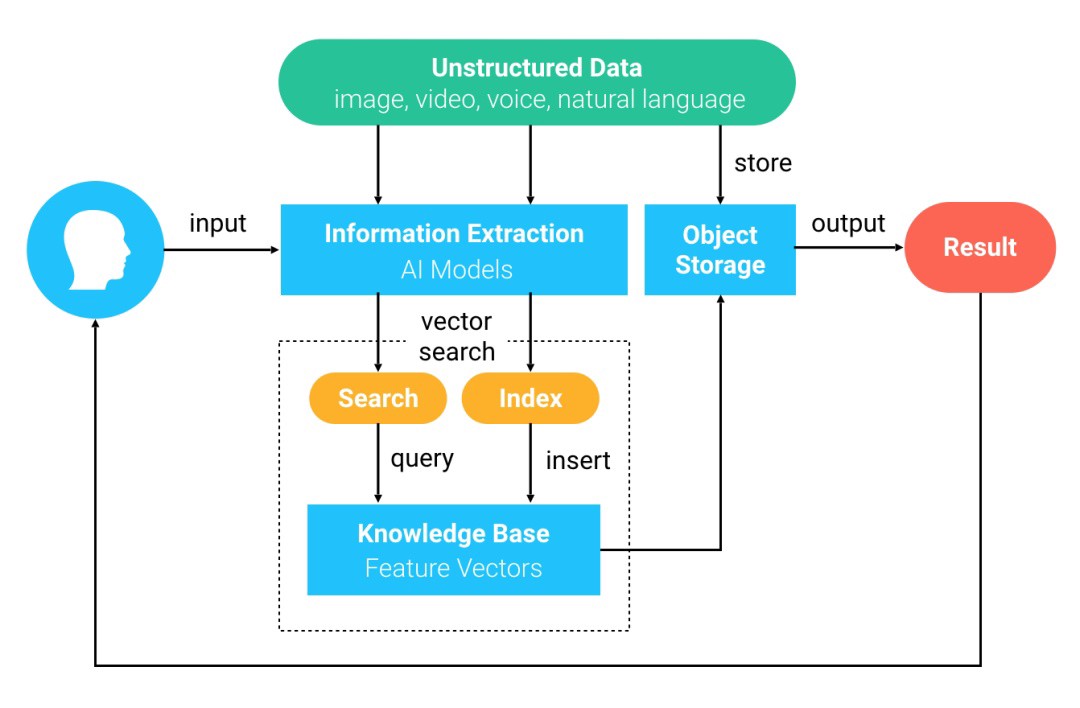
Milvus is an open-source AI-powered similarity search engine supporting a wide variety of unstructured data-converted vectors. It has been adopted by 400+ enterprise users and has applications spanning image processing, computer vision, natural language processing (NLP), speech recognition, recommendation engines, search engines, new drug development, gene analysis, and more. The following shows a general similarity search process using Milvus:
- The user uses deep learning models to convert unstructured data to feature vectors and import them to Milvus.
- Milvus stores and builds indexes for the feature vectors.
- After receiving a vector query from the user, Milvus outputs a result similar to the input vector. Upon request, Milvus searches and returns vectors most similar to the input vectors.
Implementation of Recommendation System
System Overview
Here we will use the following figure to illustrate the basic process of building a graph-based recommendation system with Milvus. The basic process includes data preprocessing, PinSage model training, data loading, searching, and recommending.

Data Preprocessing
The recommendation system we build in this article is based on the open data sets MovieLens (download the ZipFile here) (m1–1m), which contain 1,000,000 ratings of 4,000 movies by 6,000 users. Collected by GroupLens Research Labs, the data includes movie information, user characteristics, and ratings of movies. In this article, we will use users’ movie history to build a graph with classification characteristics, a users-movies bipartite graph g.
x
# Build graph
graph_builder = PandasGraphBuilder()
graph_builder.add_entities(users, 'user_id', 'user')
graph_builder.add_entities(movies_categorical, 'movie_id', 'movie')
graph_builder.add_binary_relations(ratings, 'user_id', 'movie_id', 'watched')
graph_builder.add_binary_relations(ratings, 'movie_id', 'user_id', 'watched-by')
g = graph_builder.build()
PinSage Model Training
The embedding vectors of pins generated by using the PinSage model are feature vectors of the acquired movie info. First, create a PinSage model according to the bipartite graph g and the customized movie feature vector dimensions (which is 256-dimension at default). Then, train the model with PyTorch to obtain the h_item embeddings of 4000 movies.
xxxxxxxxxx
# Define the model
model = PinSAGEModel(g, item_ntype, textset, args.hidden_dims, args.num_layers).to(device)
opt = torch.optim.Adam(model.parameters(), lr=args.lr)
# Get the item embeddings
for blocks in dataloader_test:
for i in range(len(blocks)):
blocks[i] = blocks[i].to(device)
h_item_batches.append(model.get_repr(blocks))
h_item = torch.cat(h_item_batches, 0)
Data Loading
Load the movie embeddings h_item generated by the PinSage model into Milvus, and Milvus will return the corresponding IDs. Import the IDs and the corresponding movie information into MySQL.
x
# Load data to Milvus and MySQL
status, ids = milvus.insert(milvus_table, h_item)
load_movies_to_mysql(milvus_table, ids_info)
Searching
Get the corresponding embeddings in Milvus based on the movie IDs and carry out a similarity search with these embeddings in Milvus. Then, find the corresponding movie information in a MySQL database accordingly.
xxxxxxxxxx
# Get embeddings that users like
_, user_like_vectors = milvus.get_entity_by_id(milvus_table, ids)
# Get the information with similar movies
_, ids = milvus.search(param = {milvus_table, user_like_vectors, top_k})
sql = "select * from " + movies_table + " where milvus_id=" + ids + ";"
results = cursor.execute(sql).fetchall()
Recommendation
Finally, the system will recommend movies most similar to the search queries to the users. Above is the main workflow of building a recommendation system. For more details, see Milvus-Bootcamp.
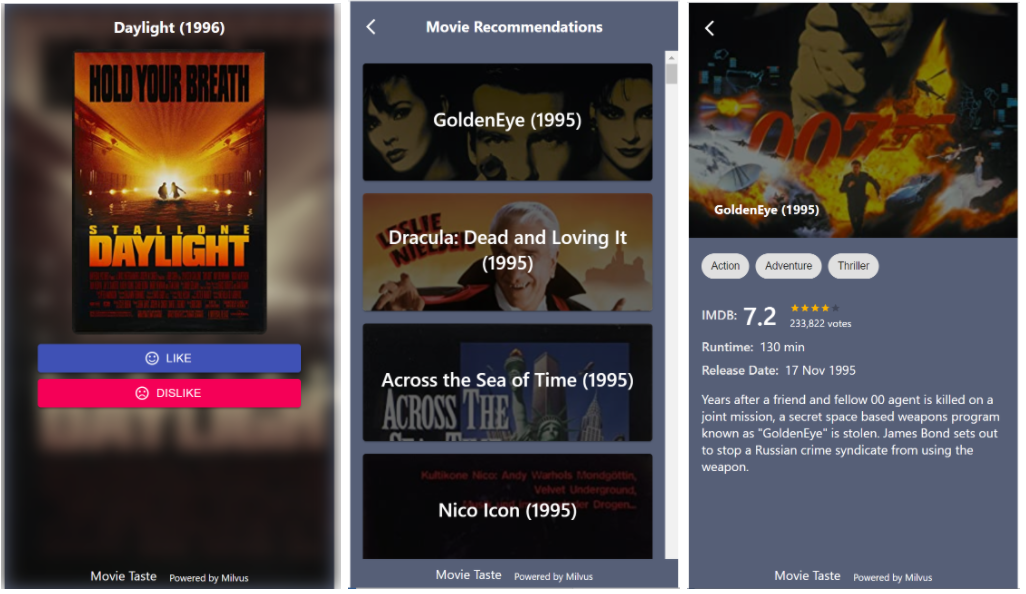
System Demo
In addition to a FastAPI method, the project also has a front-end demo. By simulating the process of a user clicking on the movies to his liking, the demo makes a movie recommendation.
The system also provides a FastAPI interface and front-end display that recommends movies catering to users’ tastes. You can simulate the process by logging into the Movie Recommendation System and marking the movies you like.
Conclusion
PinSage is a graph convolutional neural network that can be used for recommendation tasks. It generates high-quality embeddings of pins via a pins-boards bipartite graph.
We use the MovieLens datasets to create a users-movies bipartite graph, and the DGL open-source package, and the PinSage model to generate feature vectors of movies. The vectors are then stored in Milvus, a similarity embeddings search engine. Recommendations of movies are returned to users afterward.
Milvus embedding vector similarity search engine can be integrated into a wide variety of deep learning platforms and multiple AI scenarios. By fully leveraging the optimized vector retrieval algorithms and integrated heterogeneous computing resources, Milvus can continually empower companies with vector retrieval capabilities.
Opinions expressed by DZone contributors are their own.
Comments