Building a Graph Database on a Key-Value Store?
Is the next generation of graph databases going to be based on key-value stores? Is there a renaissance on its way?
Join the DZone community and get the full member experience.
Join For Free[Excerpted from the eBook Native Parallel Graphs: The Next Generation of Graph Database for Real-Time Deep Link Analytics]
Until recently, graph database designs fulfilled some but not all of the graph analytics needs of enterprises. The first generation of graph databases (e.g., Neo4j) was not designed for big data. They cannot scale out to a distributed database, are not designed for parallelism, and perform slowly at both data loading and querying for large datasets and/or multi-hop queries.
The second generation of graph databases (e.g., DataStax Enterprise Graph) was built on top of NoSQL storage systems such as Apache Cassandra. This addressed the scale-out issue, but since they lack a native graph storage design, they still have slow performance for graph updates or multi-hop queries on large datasets. Faced with the apparent lack of a high-performance graph database solution, some organizations have considered building their own in-house graph solution. Rather than starting from scratch, a modern fast key-value store seems like a good base on which to build a custom graph solution.
The Lure of Key-Value Stores
The NoSQL revolution came about because relational databases were too slow and too inflexible. Big data users needed to ingest a variety of differently structured data, with both high volume and high velocity, and to scale out their physical infrastructure with minimal fuss. The key-value store arose as the simplest and therefore fastest NoSQL architecture. A key-value database is basically a two-column hash table, where each row has a unique key (ID) and a value associated with that key. Searching the key field can return single data values very quickly, much faster than a relational database. Key-value stores also scale well to very large data sets. Key-value stores are well understood, and many free open-source designs are available. It seems fairly straightforward to use a fast key-value store to hold a graph’s node entities and edge entities, implement a little more logic and call that a graph database.
The Real Cost of Building Your Own Graph Database
Building your own graph database on top of a key-value store, let alone a high-performance one, is much harder than it looks. Here are two obvious difficulties:
- You are following the architectural principles of the 2nd generation graph databases, but you are trying to improve upon those. Products such as DataStax Enterprise Graph have already optimized performance as much as they can, given the inherent limitations of a non-native graph storage design.
- What you really need is a complete database management system (DBMS), not just a graph database. A database is just a collection of data organized in a specific way such that storing and retrieving data are supported. A DBMS, on the other hand, is the complete application program for using and managing data via a database. A DBMS typically includes support for defining a database model, inserting, reading, updating, and deleting data, performing computational queries (not just reading the raw data), applying data integrity checks, supporting transactional guarantees and concurrency, interacting with other applications, and performing administrative functions, such as managing user privileges and security. A do-it-yourself design will need to implement and verify all of these additional requirements.
Let’s examine some of the common problems in building a high-performance graph on top of key-value storage.
- Data inconsistency and wrong query results
- Architectural mismatch with slow performance
- Expensive and rigid implementation
- Lack of enterprise support
1. Data Inconsistency and Wrong Query Results
Key-value stores are typically highly optimized for high throughput and low latency of single-record reads/writes. As a result, ACID (Atomicity, Consistency, Isolation, Durability) properties are guaranteed only at the single-record level for most key-value stores. This means that data consistency is at risk for any real-world transactional events that involve the writing of multiple records (e.g., customer purchases, money transfers, a rideshare request). Lack of data consistency means that queries that aggregate across two or more of these common multi-record transactions can result in incorrect results.
Developers hoping to build a system that businesses can truly trust should realize that data consistency and guaranteeing correct results is an all-or-nothing endeavor. There are no shortcuts for ACID properties. In a graph system, one transaction will often need to create multiple nodes and add new connections/edges between new or existing nodes, all within a single, all-or-nothing transaction. The easy way to guarantee ACID is to perform only one operation at a time, locking out all other operations. But this results in very slow throughput.
In a high-performance design, a transaction must never interfere with, slow down, or block any other existing or incoming read-only queries, even if they are traversing neighboring parts of the graph. If concurrent operations are a business requirement, then developers need to design and engineer a non-blocking graph transactional architecture where multiple key-value transaction support is added inside the distributed key-value system. There are many stories of development teams trying to implement a shortcut workaround that inevitably led to downstream data and query correctness issues.
2. Architectural Mismatch With Slow Performance
Queries involving single records are fast with a key-value store. But key-value store query speeds degrade sharply as queries become more complex. With each hop in the graph traversal, the application has to send a key-value retrieval command to the external key-value store. More hops generate more communication overhead and result in slower query performance. And computation on the data, such as filtering, aggregation, and evidence-gathering, cannot be completely pushed down to the key-value store. Instead, it must take place in the graph application layer, which creates additional input and output transmission with the key-value store while bogging down the query performance even more. Moreover, computing in the graph application layer instead of inside a native parallel graph platform is by default non-parallel. To match the parallelism in a Native Parallel Graph like TigerGraph, developers would need to take on the extra burden of parallelizing the computation in a single machine or take the even more extraordinary burden of scaling out the computation to multiple machines and taking care of the scheduling, messaging, failover, and other requirements of a distributed system.
Enterprises that want a high-performance graph want a system that analyzes complex relationships and surfaces hidden patterns, with fast query performance. To address these requirements, developers would need to do all of the following: build a graph over key-value application that handles basic graph modeling (describing the structure and behavior of a graph in general), implement basic graph data definition and data manipulation operations, ensure transactional guarantees, and then develop application queries on top of that. That is, in-house developers would need to implement an interpreter for a data definition language (DDL) and a graph query language. Developers should consider the significant time and resources required to support such a challenging endeavor and expect to deal with a lot of unforeseen downstream problem-solving.
3. Expensive and Rigid Implementation
Organizations thinking about creating their own graph database system on top of another database system should consider the resources needed, reliability desired, and ideal adaptability of their application.
Building a graph on key-value system would take a great deal of time to complete. The upfront costs of building custom software should not be underestimated. Furthermore, reliability is critical to application success. As previously discussed, developers should put great thought into how they will design, test, deploy, and support a graph ecosystem that includes full data consistency, correct results, and high performance of complex queries. Finally, management and development teams should consider that a single application likely doesn’t have the general purpose capabilities and flexibility of a high-performance distributed native graph database product. Decision makers should consider the big picture and whether their custom design project can address unforeseen future expansion. By choosing the right graph capabilities now, you can streamline tasks, reduce errors, and make everyone’s life a lot easier for years to come.
4. Lack of Enterprise Support
Last but not least, a custom design will not include many of the features that are crucial for secure and reliable enterprise deployment: user authorization and access control, logging, high availability, and integration with other applications. Some of these enterprise features might be available for the key-value store, but they need to be available at the graph (application) level.
Example: Graph Update for One Event
The following example shows the actions that occur in a typical graph database update. It illustrates how data inconsistency and incorrect results can occur when using a key-value store based graph system and discusses the development challenges and limitations in trying to build functional workarounds.
Consider this update scenario. A real-time event takes place where one user transfers money to another user using a bank card on a mobile phone. Such transactions can be modeled with a simple graph schema, as shown below.
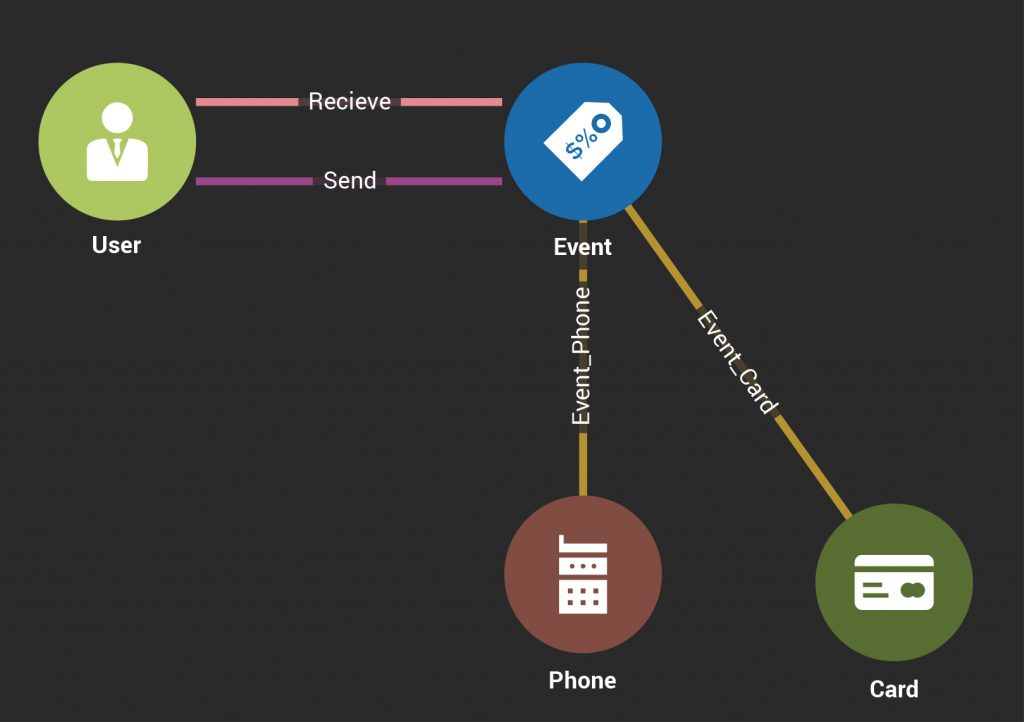
Figure 1: Graph Schema for Electronic Payments
This example applies to many other use cases. For example, you can replace the money transfer event with a product purchase event or a service engagement event, such as hiring a ridesharing service.
The money transfer Event e1 is a node which links together four related entities (u1, u2, c1, p1), where:
- u1 is the User sending money,
- u2 is the User receiving money,
- c1 is the payment Card used, and
- p1 is the Phone used.
For simplicity, we ignore all other attributes present in this event (such as dollar amount, location, and timestamp).
There are multiple ways to model a graph database with a graph over key-value system. One approach is to have two tables in the graph over key-value system: a node table V and an edge table E. Another approach is to just have a single node table (no edge table) which has a row for each node to store both node attributes and edge information (edge attributes and connected nodes). The challenges faced in either approach are similar, so we use the more straightforward two-table approach.
To update the graph by adding a new Event e1, we perform the following actions:
- Create a new Event node e1. Equivalently in the graph over key-value system approach, we need to insert one row in the node table V.
- For each entity u1, u2, c1, and p1, check if it already exists. Create a new node for each one that does not yet exist. Equivalently, key-value system approach, we need to insert from zero to four rows in the node table V.
- Add four edges between e1 and the four other entities: (e1,u1), (e1,u2), (e1,c1), and e1,p1). Equivalently, add four rows to the key-value system’s edge table E. This will directly connect all cards and phones used by a user but would make a graph over key-value system implementation even more complex and error-prone. In the equivalent key-value store, we need to insert four rows in the edge table E.Also we want to be able to find all events connected to a phone, a user, or a card. This requires ensuring that we can traverse connections in either direction. Depending on the graph implementation, we either need to mark the edges as bidirectional or we need to add four additional edges in the other direction: (u1,e1), (u2,e1), (c1,e1), and (p1,e1). The equivalent key-value system approach would need to insert four more rows in the edge table E.
In total, one new Event requires creating one to five nodes and four to eight edges. The following figure depicts three events which have some Users in common:
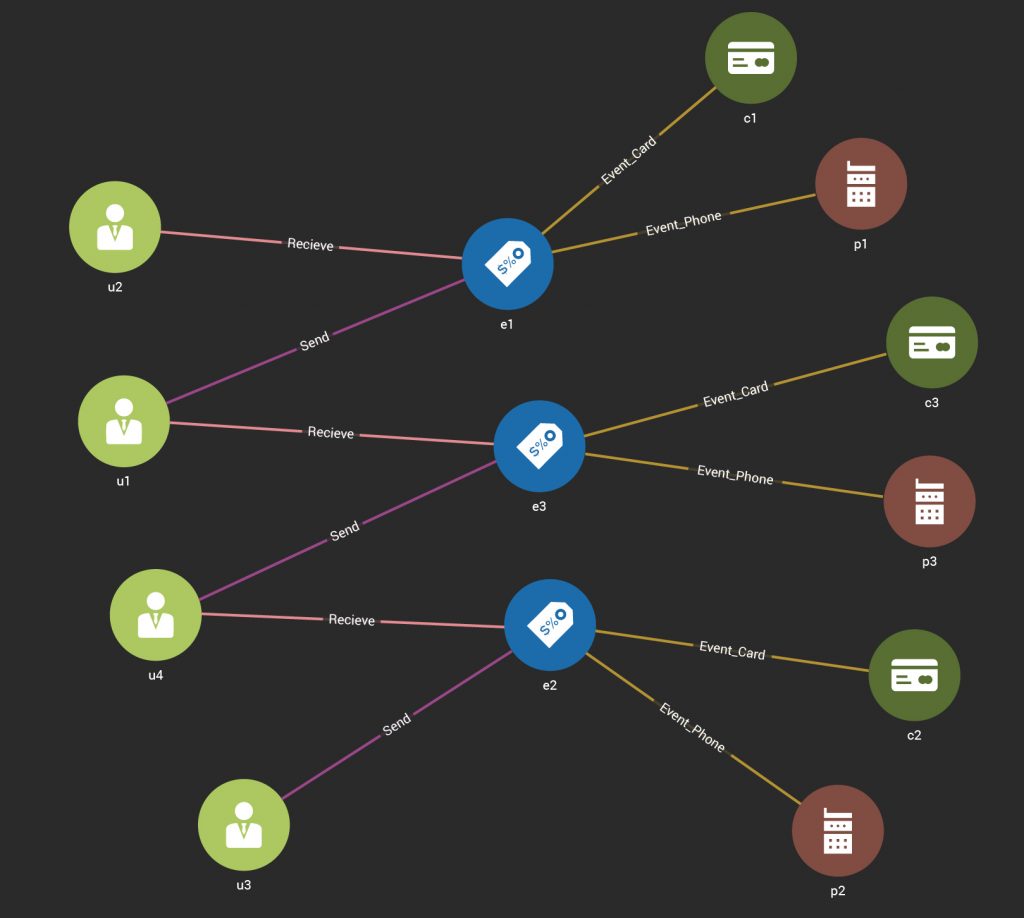
Transaction Update Graph Details
Since the Event e1 is treated as a single transaction, the above three actions need to happen to the graph (equivalently to two tables) in an atomic way, which means that:
- Either all three actions are guaranteed to take place fully, or none of them should take place. A non-transactional system which allows some but not all of the actions to take place (e.g., action 1 and 2 complete successfully but action 3 does not) leads to data inconsistency and wrong results. If any one or more actions do not complete, the result will be missing edges with wrong query results. For this graph model and event, the three actions contain up to 13 nodes and edges to add.
- During the time we apply actions 1, 2 and 3 and before they are completed, their effect should not be visible to any other read or write operations. This means that if you have another query q1, which is still traversing the edges/nodes in the graph before the event e1 comes into the system, q1 should not see any of the actions of 1, 2 and 3 even if they complete successfully before e1 finishes.
- This also means that if a read-only query q2 comes into the system later than e1 but before the three actions of e1 are all completed, the effects of e1 should not be visible to q2.
Possible Solutions to Graph Over Key-Value Shortcomings
A workaround is to simply ignore all data inconsistency and wrong query result issues and just insert key-value rows to node table V and edge table E and hope for the best. Even if a company’s business requirements can be relaxed to tolerate data inconsistency and wrong query results, this does not remove the implementation challenge. That is because the users don’t know whether or when they will miss a node or edge in the graph. To address this, developers will need to tack on protection code to ensure the application will not hang or crash due to traversing ghost/missing edges.
A better solution would be to implement true support for concurrent multi-step transactions inside the distributed key-value system. But this requires not only a huge engineering effort but also significant slowdown of key-value operations.
A third solution, a “placebo solution,” is to add some kind of locking mechanism inside the application level without changing the kernel of the underlying key-value store. Workarounds, like attempting to add a “commit” flag to each row or maintaining a “dirty” list of rows in their applications, can reduce data inconsistencies and incorrect results. However, such add-on features are not equivalent to an architecture designed for transactional guarantees, so data inconsistencies and incorrect results may persist albeit hidden. Ensuring that these workarounds consistently reconcile and address each transaction can be very difficult to guarantee.
Summary
In summary, designing an application-level graph on top of a key-value store is an expensive and complex job which will not yield a high-performance result. While key-value stores excel at single key-value transactions, they lack ACID properties and the complex transaction functionality required by a graph update. Thus, building a graph database on top of a key-value store opens the door to data inconsistencies, wrong query results, slow query performance for multi-hop queries, and an expensive and rigid deployment.
Published at DZone with permission of Yu Xu. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments