A Guide to Building Data Intelligence Systems: Strategic Practices to Building Robust, Ethical, and AI-Driven Data Structures
The foundation of data intelligence systems centers around transparency, governance, and the ethical and responsible exploitation of cutting-edge technologies, particularly GenAI.
Join the DZone community and get the full member experience.
Join For FreeEditor's Note: The following is an article written for and published in DZone's 2024 Trend Report, Data Engineering: Enriching Data Pipelines, Expanding AI, and Expediting Analytics.
Remarkable advances in deep learning, combined with the exponential increase in computing power and the explosion of available data, have catalyzed the emergence of generative artificial intelligence (GenAI). Consequently, huge milestones have propelled this technology to greater potential, such as the introduction of the Transformer architecture in 2017 and the launch of GPT-2 in 2019. The arrival of GPT-3 in 2020 then demonstrated astounding capabilities in text generation, translation, and question answering, marking a decisive turning point in the field of AI.
In 2024, organizations are devoting more resources to their AI strategy, seeking not only to optimize their decision-making processes, but also to generate new products and services while saving precious time to create more value. In this article, we plan to assess strategic practices for building a foundation of data intelligence systems. The emphasis will center around transparency, governance, and the ethical and responsible exploitation of cutting-edge technologies, particularly GenAI.
An Introduction to Identifying and Extracting Data for AI Systems
Identifying and extracting data are fundamental steps for training AI systems. As data is the primary resource for these systems, it makes it a priority to identify the best sources and use effective extraction methods and tools. Here are some common sources:
- Legacy systems contain valuable historical data that can be difficult to extract. These systems are often critical to day-to-day operations. They require specific approaches to extract data without disrupting their functioning.
- Data warehouses (DWHs) facilitate the search and analysis of structured data. They are designed to store large quantities of historical data and are optimized for complex queries and in-depth analysis.
- Data lakes store raw structured and unstructured data. Their flexibility means they can store a wide variety of data, providing fertile ground for exploration and the discovery of new insights.
- Data lakehouses cleverly combine the structure of DWHs with the flexibility of data lakes. They offer a hybrid approach that allows them to benefit from the advantages of both worlds, providing performance and flexibility.
Other important sources include NoSQL databases, IoT devices, social media, and APIs, which broaden the spectrum of resources available to AI systems.
Importance of Data Quality
Data quality is indispensable for training accurate AI models. Poor data quality can distort the learning process and lead to biased or unreliable results. Data validation is, therefore, a crucial step, ensuring that input data meets quality standards such as completeness, consistency, and accuracy. Similarly, data versioning enables engineers to understand the impact of data changes on the performance of AI models. This practice facilitates the reproducibility of experiments and helps to identify sources of improvement or degradation in model performance.
Finally, data tracking ensures visibility of the flow of data through the various processing stages. This traceability lets us understand where data comes from, how it is transformed, and how it is used, thereby contributing to transparency and regulatory compliance.
Advanced Data Transformation Techniques
Advanced data transformation techniques prepare raw data for AI models. These techniques include:
- Feature scaling and normalization. These methods ensure that all input variables have a similar amplitude. They are crucial for many machine learning algorithms that are sensitive to the scale of the data.
- Handling missing data. Using imputation techniques to estimate missing values, this step is fundamental to maintaining the integrity and representativeness of datasets.
- Detection and processing of outliers. This technique is used to identify and manage data that deviate significantly from the other observations, thus preventing these outliers from biasing the models.
- Dimensionality reduction. This method helps reduce the number of features used by the AI model, which can improve performance and reduce overlearning.
- Data augmentation. This technique artificially increases the size of the dataset by creating modified versions of existing data, which is particularly useful when training data is limited.
These techniques are proving important because of their ability to enhance data quality, manage missing values effectively, and improve predictive accuracy in AI models. Imputation methods, such as those found in libraries like Fancyimpute and MissForest, can fill in missing data with statistically derived values. This is particularly useful in areas where outcomes are often predicted on the basis of historical and incomplete data.
Key Considerations for Building AI-Driven Data Environments
Data management practices are evolving under the influence of AI and the increasing integration of open-source technologies within companies. GenAI is now playing a central role in the way companies are reconsidering their data and applications, profoundly transforming traditional approaches.
Let's take a look at the most critical considerations for building AI-driven data systems.
Leveraging Open-Source Databases for AI-Driven Data Engineering
The use of open-source databases for AI-driven data engineering has become a common practice in modern data ecosystems. In particular, vector databases are increasingly used in large language model (LLM) optimization. The synergy between vector databases and LLMs makes it possible to create powerful and efficient AI systems.
In Table 1, we explore common open-source databases for AI-driven data engineering so that you can better leverage your own data when building intelligent systems:
Table 1. Open-source databases for AI-driven data engineering
| category | capability | technology |
|---|---|---|
| Relational and NoSQL | Robust functionality for transactional workloads | PostgreSQL and MySQL |
| Large-scale unstructured data management | MongoDB, Cassandra | |
| Real-time performance and caching | Redis | |
| Support for big data projects on Hadoop; large-scale storage and analysis capabilities | Apache HBase, Apache Hive | |
| Vector databases and LLMs | Rapid search and processing of vectors | Milvus, Pinecone |
| Support for search optimization | Faiss, Annoy, Vespa | |
| Emerging technologies | Homomorphic databases | SEAL, TFHE |
| Differential privacy solutions | OpenDP, differential privacy | |
| Sensitive data protection via isolated execution environments | Intel SGX, ARM TrustZone |
Emerging Technologies
New database technologies, such as distributed, unified, and multi-model databases, offer developers greater flexibility in managing complex datasets. Data-intensive AI applications need these capabilities to bring greater flexibility in data management. Additionally, privacy-oriented databases enable computations on encrypted data. This enhances security and compliance with regulations such as GDPR. These advances enable developers to build more scalable and secure AI solutions. Industries handling sensitive data need these capabilities to ensure flexibility, security, and regulatory compliance.
As shown in Table 1, homomorphic encryption and differential privacy solutions will prove impactful for advanced applications, particularly in industries that deal with sensitive data. For example, homomorphic encryption lets developers operate computations on encrypted data without ever decrypting it.
Ethical Considerations
Ethical considerations related to training models on large datasets raise important questions about bias, fairness, and transparency of algorithms and applications that use them. Therefore, in order to create AI systems that are more transparent, explainable AI is becoming a major requirement for businesses because the complexity of LLM models often makes it difficult, sometimes even impossible, to understand the decisions or recommendations produced by these systems.
For developers, the consequence is that they not only have to work on performance, but also ensure that their models can be interpreted and validated by non-technical stakeholders, which requires extra time and effort when designing models. For example, developers need to install built-in transparency mechanisms, such as attention maps or interpretable results, so that decisions can be traced back to the specific data.
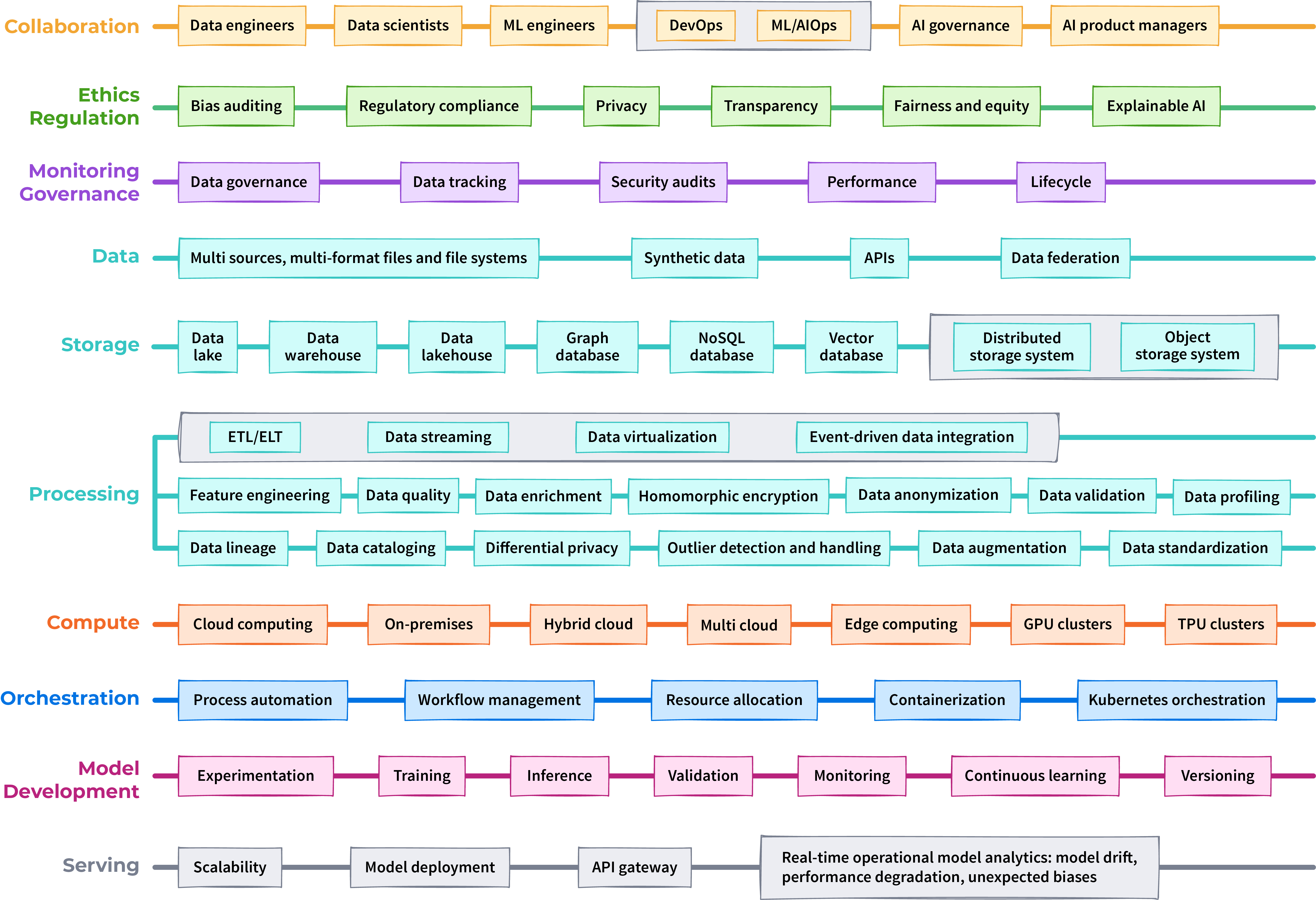
Building a Scalable AI Infrastructure
Building a scalable AI infrastructure is based on three main components:
- Storage. Flexible solutions, such as data lakes or data lakehouses, enable massive volumes of data to be managed efficiently. These solutions offer the scalability needed to adapt to the exponential growth in data generated and consumed by AI systems.
- Computing. GPU or TPU clusters provide new processing power required by deep neural networks and LLMs. These specialized computing units speed up the training and inference of AI models.
- Orchestration. Orchestration tools (e.g., Apache Airflow, Dagster, Kubernetes, Luigi, Prefect) optimize the management of large-scale AI tasks. They automate workflows, manage dependencies between tasks, and optimize resource use.
Figure 1. Scalable AI architecture layers
Hybrid Cloud Solutions
Hybrid cloud solutions offer flexibility, resilience, and redundancy by combining public cloud resources with on-premises infrastructure. They enable the public cloud to be used for one-off requirements such as massive data processing or complex model training. At the same time, they combine the ability to maintain sensitive data on local servers. This approach offers a good balance between performance, security, and costs because hybrid cloud solutions enable organizations to make the most of both environments.
Ensuring Future-Proof AI Systems
To ensure the future proofing of AI systems, it is essential to:
- Design flexible and modular systems. This makes it easy to adapt systems to new technologies and changing business needs.
- Adopt data-centric approaches. Organizations must ensure that their AI systems remain relevant and effective. To achieve that, they have to place data at the heart of strategy.
- Integrate AI into a long-term vision. AI should not be seen as an isolated project since technology for technology's sake is of little interest. Instead, it should be seen as an integral component of a company's digital strategy.
- Focus on process automation. Automation optimizes operational efficiency and frees up resources for innovation.
- Consider data governance. Solid governance is essential to guarantee the quality, security, and compliance of the data used by AI systems.
- Prioritize ethics and transparency. These aspects are crucial for maintaining user confidence and complying with emerging regulations.
Collaboration Between Data Teams and AI/ML Engineers
Collaboration between data engineers, AI/ML engineers, and data scientists is critical to the success of AI projects. Data engineers manage the infrastructure and pipelines that allow data scientists and AI/ML engineers to focus on developing and refining models, while AI/ML engineers operationalize these models to deliver business value.
To promote effective collaboration, organizations need to implement several key strategies:
- Clearly define the roles and responsibilities of each team; everyone must understand their part in the project.
- Use shared tools and platforms to facilitate seamless interaction and data sharing among team members.
- Encourage regular communication and knowledge sharing through frequent meetings and the use of shared documentation platforms.
These practices help create a cohesive work environment where information flows freely, leading to more efficient and successful AI projects. For example, in a recommendation engine used by an e-commerce platform, data engineers collect and process large volumes of customer data. This includes historical browsing data and purchasing behavior. AI/ML engineers then develop algorithms that predict product preferences, and developers integrate the algorithms into the website or application. When an update to the recommendation model is ready, MLOps pipelines then automate testing and deployment.
Conclusion
Beyond tool implementation, strategic considerations must be accounted for in the same way as purely technical ones:
- Projects based on AI technologies must be built on a foundation of high-quality, well-managed data. The quality of AI systems depends in particular on the diversity and richness of their data sources, whether these are existing systems or data lakes.
- Ensuring AI models are interpretable and ethically compliant is essential to nurture trust and compliance with regulatory frameworks.
- The success of all AI initiatives is also directly dependent on the level of collaboration between data engineers, AI/ML specialists, and DevOps teams.
- AI applications, generative models, and hardware infrastructures are evolving rapidly to meet market demands, which require companies to adopt scalable infrastructures that can support these advancements.
As organizations move forward, they need to focus on data engineering automation, cross-functional collaboration, and alignment with ethical and regulatory standards in order to maximize the value of their AI investments.
This is an excerpt from DZone's 2024 Trend Report,
Data Engineering: Enriching Data Pipelines, Expanding AI, and Expediting Analytics.
Read the Free Report
Opinions expressed by DZone contributors are their own.
Comments