Building Data Pipelines With Jira API
Automate Jira workflows via API with Python: tickets on pipeline failures, JQL reports, and data sync. Start with failed transfers and expand to dashboards and testing.
Join the DZone community and get the full member experience.
Join For FreeI’ve spent years building data pipelines and connecting project management to technical workflows. Disconnected systems lead to manual errors and delays, problems that Jira’s API helps solve.
This tool lets code interact directly with project boards, automating tasks such as creating tickets when data checks fail or updating statuses after ETL.
For data engineers, the API bridges Jira and databases. Extract issue details into warehouses, build dashboards linking pipeline performance to project effort, or trigger data workflows from Jira events. It’s about seamless integration.
In this guide, I want to walk you through how I use the Jira API in my day-to-day data engineering work. We'll cover everything from basic authentication to creating issues automatically, querying data using JQL, and even syncing custom fields with databases. My goal is to give you practical, hands-on examples you can adapt for your own pipelines, helping you connect your project management directly to your database and data processing workflows. Let me show you how to automate tasks, extract the data you need, and integrate Jira smoothly into your data engineering stack.
Setting Up Your Jira API Environment
First, create an API token in Jira Cloud:
- Go to your Atlassian account settings.
- Under Security, generate an API token.
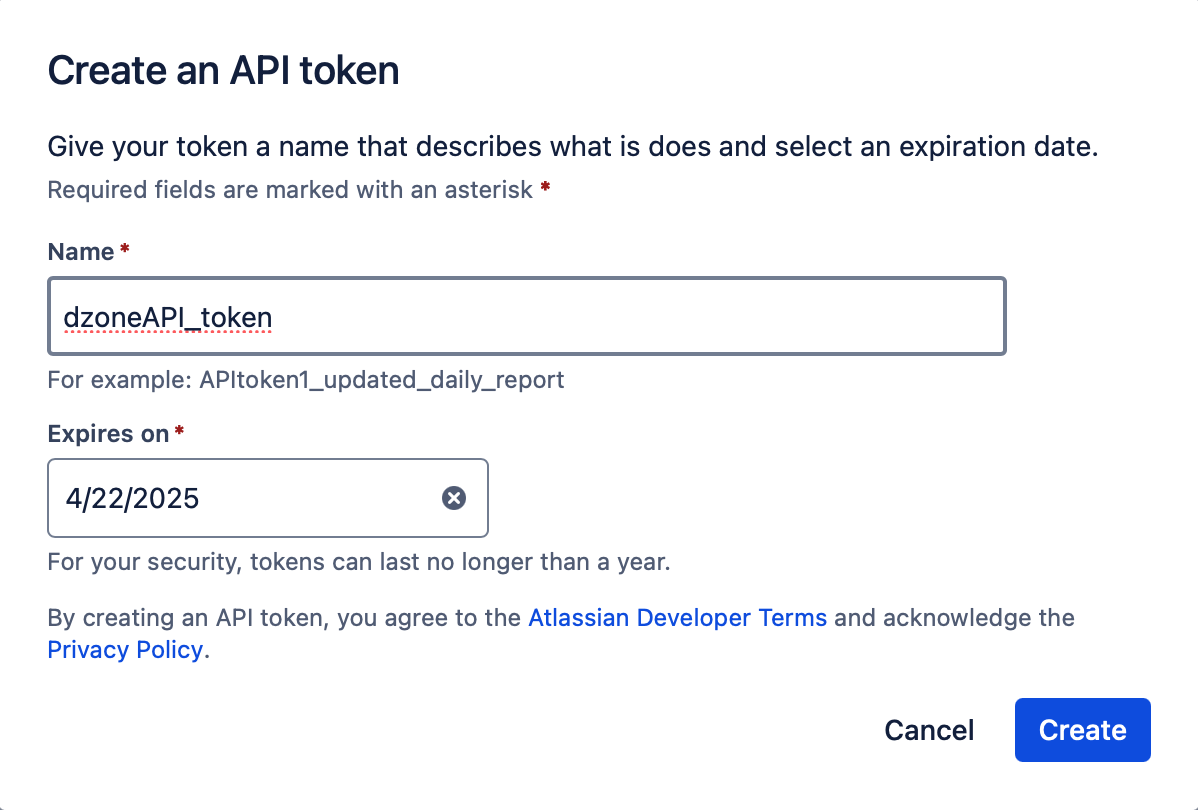
Here’s how to authenticate using Python:
import requests
auth = ("your-email@domain.com", "API_TOKEN")For cURL:
curl -u "email:API_TOKEN" https://your-domain.atlassian.net/rest/api/3/issue I always test connectivity by fetching basic project data:
response = requests.get("https://your-domain.atlassian.net/rest/api/3/project", auth=auth)
print(response.json())
Creating Issues Programmatically
Use this JSON template to create tickets. Replace PROJECT_KEY and ISSUE_TYPE_ID with your project’s values (found via Jira’s metadata API):
{
"fields": {
"project": { "key": "PROJECT_KEY" },
"summary": "Data pipeline failure",
"issuetype": { "id": "10001" },
"description": {
"type": "doc",
"content": [{"type": "text", "text": "Alert from our monitoring system"}]
}
}
}
Send it via Python:
url = "https://your-domain.atlassian.net/rest/api/3/issue"
headers = { "Content-Type": "application/json" }
response = requests.post(url, json=issue_data, headers=headers, auth=auth)
Querying Data for Analytics
Extract ticket data using JQL (Jira Query Language). This example fetches all bugs from the last 7 days:
jql = "project = PROJECT_KEY AND issuetype = Bug AND created >= -7d"
response = requests.get(
f"https://your-domain.atlassian.net/rest/api/3/search?jql={jql}",
auth=auth
)
Store results in a PostgreSQL database:
import psycopg2
data = response.json()["issues"]
conn = psycopg2.connect("dbname=etl user=postgres")
cur = conn.cursor()
for issue in data:
cur.execute("INSERT INTO jira_issues VALUES (%s, %s)", (issue["key"], issue["fields"]["summary"]))
conn.commit()
Syncing Custom Fields With Databases
Jira’s database schema (source) uses tables like customfield and jiraissue. While direct database access isn’t recommended, here’s how to map API data to SQL:
1. Fetch custom field metadata:
custom_fields = requests.get("https://your-domain.atlassian.net/rest/api/3/field", auth=auth).json()
2. Create a database table dynamically:
columns = ["issue_key VARCHAR PRIMARY KEY"]
for field in custom_fields:
columns.append(f"{field['id']} VARCHAR")
cur.execute(f"CREATE TABLE jira_custom_fields ({', '.join(columns)})")
Automating Workflows
Trigger data pipeline runs when Jira tickets update. Use webhooks:
1. Set up a Flask endpoint:
from flask import Flask, request
app = Flask(__name__)
@app.route("/webhook", methods=["POST"])
def handle_webhook():
data = request.json
if data["issue"]["fields"]["status"] == "Done":
# Start your ETL job here
return "OK"
2. Configure the webhook in Jira’s settings.
When to Work With Jira Consultants
While the API is powerful, complex setups like custom schema migrations or large-scale automation might require expertise. Jira consultants often help teams design these systems, like optimizing how ticket data flows into data lakes or aligning Jira workflows with CI/CD pipelines.
Troubleshooting Common Issues
API Rate Limits
Jira Cloud allows 100 requests/minute. Use exponential backoff:
import time
def make_request(url):
for _ in range(5):
response = requests.get(url, auth=auth)
if response.status_code != 429:
return response
time.sleep(2 ** _)
Data Type Mismatches
Jira’s timeworked field stores seconds, while many databases use intervals. Convert during ingestion:
timeworked_seconds = issue["fields"]["worklog"]["total"]
timeworked_interval = f"{timeworked_seconds // 3600}:{(timeworked_seconds % 3600) // 60}:{timeworked_seconds % 60}"
What I've shown you here really just gets you started.
Think of it like learning the basic chords on a guitar; you can play some simple songs now, but there's a whole world of music still out there. These pieces — authenticating, creating issues, searching data, using webhooks – are the essential building blocks. With these under your belt, you can start building some really useful connections between Jira and your data world.
For example, you can absolutely turn Jira into a live, real-time data source for your monitoring and reporting. Imagine dashboards that don't just show database performance, but also display the open engineering tickets related to that specific database.
You could pull data on how long issues stay in different statuses and feed that into Grafana or Kibana to visualize bottlenecks in your team's workflow. By regularly fetching data via the API, you get a constantly updated picture, much more alive than static reports.
And triggering your data pipelines directly from Jira events? That opens up serious automation possibilities. We touched on using webhooks for this.
Think about it: a Jira issue moves to 'Ready for Deployment'. A webhook fires, triggering your CI/CD pipeline to deploy a new data transformation script. Or, a new bug ticket is created with a specific tag like 'Data Quality'. A webhook could automatically trigger a diagnostic script to gather more information about the failure and add it to the ticket description. This links project decisions directly to technical actions, cutting out manual steps and delays.
Don't overlook the potential locked away in your past Jira tickets either. There are often years of history sitting there. Using the API, you can extract all that historical data — things like how long tasks actually took versus their estimates, which components had the most bugs, or how quickly critical issues were resolved.
This historical data is gold dust for analysis and even machine learning. You could train models to better predict how long future tasks might take, identify patterns that lead to recurring problems, or even forecast potential support load based on recent activity. The API is your key to unlocking that historical treasure chest.
But the most important piece of advice I can give is "start small". Seriously. Don't try to build a massive, all-singing, all-dancing integration on day one. You'll likely get overwhelmed.
Pick one simple, concrete pain point you have. Maybe it's manually creating tickets for ETL failures.
- Automate just that one thing first.
- Get it working reliably.
- See the time it saves you.
- Feel that little win.
- Then, pick the next small thing.
Maybe it's pulling a weekly report of completed tasks into a database table. Build that. This step-by-step approach keeps things manageable. You learn as you go, build confidence, and gradually create a more connected system that truly works for you and your team. Expand outwards from those small successes.
That’s how you make real progress.
Opinions expressed by DZone contributors are their own.
Comments