Caching In Distributed Systems: A Complete Guide
Explore a comprehensive guide about caching in distributed systems including its benefits, caching strategies, cache invalidation methods, and more.
Join the DZone community and get the full member experience.
Join For FreeIn today’s digital landscape, where user expectations for speed and responsiveness are at an all-time high, optimizing system performance is crucial for businesses to stay competitive. One effective approach to address performance bottlenecks is the implementation of caching mechanisms. In this article, we’ll delve into the importance of caching in enhancing system performance, explore various caching strategies and cache invalidation methods, and examine common cache-related problems along with real-world solutions.
Problem Statement
Consider a popular e-commerce platform experiencing a surge in user traffic during a festive season sale. As the number of users increases, so does the volume of database queries, resulting in sluggish performance and delayed response times.
This performance degradation impacts user experience and may lead to lost sales opportunities for the business.
Caching as a Solution
To mitigate the performance issues caused by increased database queries, the e-commerce platform decides to implement caching.
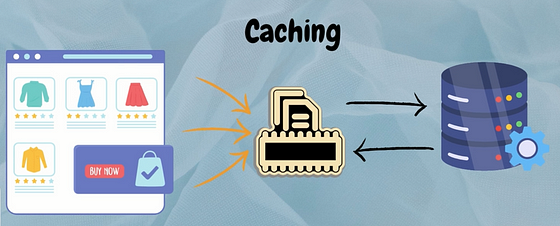
By caching frequently accessed product information, such as product details, prices, and availability, in memory, the platform aims to reduce the need for repetitive database queries and deliver faster response times to users browsing the website or making purchases.
How Caching Works
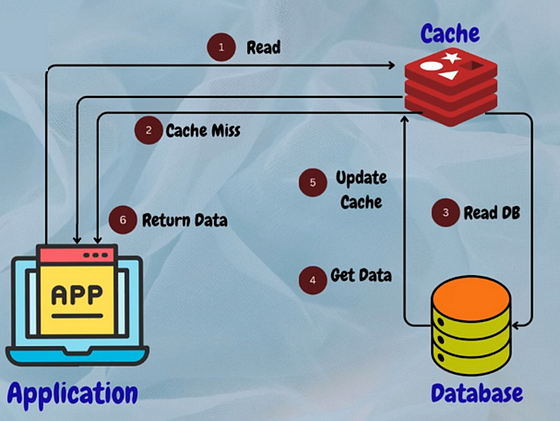
When a user visits the e-commerce platform to view product listings, the system first checks the cache for the requested product information. If the data is found in the cache (cache hit), it is retrieved quickly and served to the user, resulting in a seamless browsing experience. However, if the data is not present in the cache (cache miss), the system retrieves the information from the database, serves it to the user, and updates the cache to prevent future incidents of not finding the data in the cache.
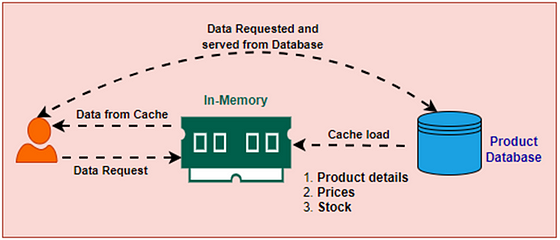
If the data is found in the cache it is called cache hit and if not, it’s called cache miss.
But, how does the desired data get loaded to the cache? There are several caching strategies that help us load the data to the cache.
Caching strategies are approaches to manage how data is stored and retrieved in a cache to optimize performance and efficiency. These strategies determine how data is cached, when it is updated or invalidated, and how it is accessed.
Caching Strategies
Read-Through Cache
With this approach, when a cache miss occurs, the system automatically fetches the data from the database, populates the cache, and returns the data to the user.
Example: Memcached is used for caching frequently accessed database queries in a web application.
2. Cache-Aside (Lazy Loading)
In cache-aside caching, the application first checks the cache for the requested data. If the data is not found in the cache, the application fetches it from the database, populates the cache, and returns the data to the user.
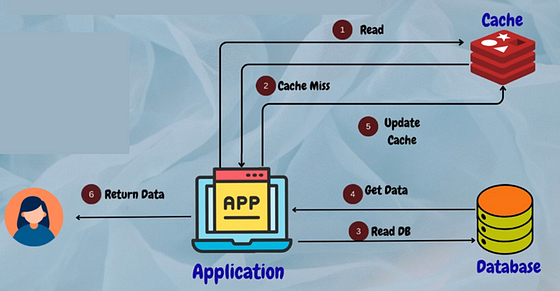
Example: MongoDB caching frequently accessed user profiles in a social media platform.
3. Write-Back Cache
With write-back caching, data is written to the cache first and then asynchronously written to the underlying storage at a later time. This strategy improves write performance by reducing the latency associated with synchronous disk writes.
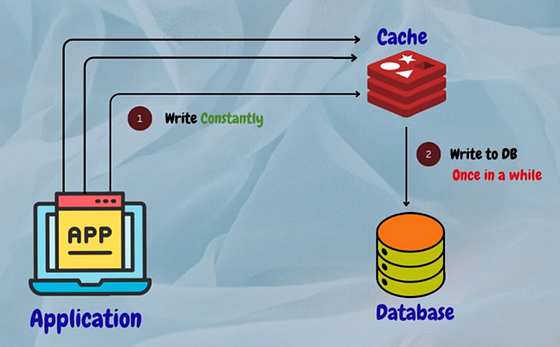
Example: A database system caching write operations in memory before committing them to disk to improve overall system responsiveness and throughput.
4. Write-Around Cache
In this strategy, data is written directly to the underlying storage without being cached initially. Only subsequent read requests for the same data trigger caching. This approach is beneficial for data with low access frequency or data that doesn’t benefit from caching.
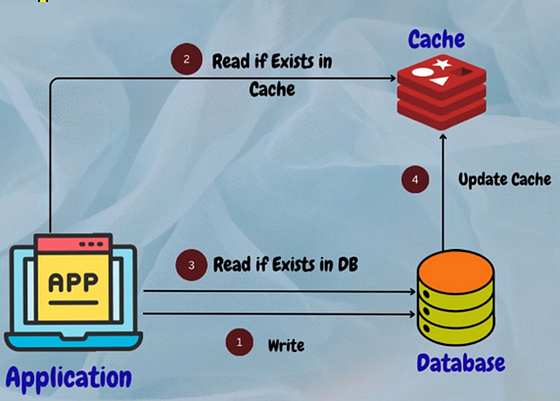
Example: A file storage system where large files are written directly to disk without being cached to optimize cache utilization for frequently accessed files.
5. Write-Through Cache
In this strategy, every write operation to the database is also written to the cache simultaneously. This ensures that the cache is always up-to-date with the latest data.
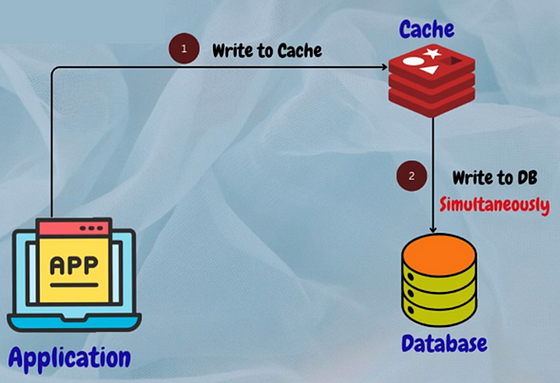
Example: Redis cache with write-through caching for user session management.
Cache Invalidation Methods
Okay, now that we’ve loaded the data in the cache, how do we make sure it’s still good? Since cached data can be outdated, we need ways to check if it’s still reliable. Cache invalidation methods confirm that the cached data matches the latest information from the original source.
Cache invalidation is the process of removing or updating cached data when it becomes stale or outdated. This ensures that the cached data remains accurate and reflects the most recent changes from the source of truth, such as a database or a web service.
“Purge,” “refresh,” and “ban” are commonly used cache invalidation methods that are frequently used in the application cache, content delivery networks (CDNs), and web proxies. Here’s a brief description of a few famous cache invalidation methods:
1. Time-Based Invalidation
Cached data is invalidated after a specified period to ensure freshness.
- Example: Expire user authentication tokens in the cache after a certain time interval.
Time-To-Live(TTL) Expiration
This method involves setting a time-to-live value for cached content, after which the content is considered stale and must be refreshed. When a request is received for the content, the cache checks the time-to-live value and serves the cached content only if the value hasn’t expired. If the value has expired, the cache fetches the latest version of the content from the origin server and caches it.
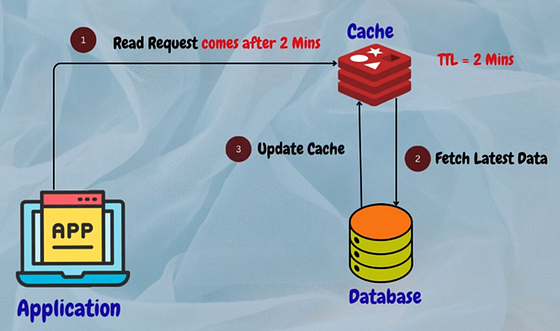
For example, in a news application, articles in the cache may have a TTL of 24 hours. After 24 hours, the articles expire and are removed from the cache.
2. Event-Based Invalidation
Cache entries are invalidated based on specific events or triggers, such as data updates or deletions.
- Example: Invalidate product cache when inventory levels change in an e-commerce platform.
Purge
The purge method removes cached content for a specific object, URL, or a set of URLs. It’s typically used when there is an update or change to the content and the cached version is no longer valid. When a purge request is received, the cached content is immediately removed, and the next request for the content will be served directly from the origin server.
Refresh
Fetches requested content from the origin server, even if cached content is available. When a refresh request is received, the cached content is updated with the latest version from the origin server, ensuring that the content is up-to-date. Unlike a purge, a refresh request doesn’t remove the existing cached content; instead, it updates it with the latest version.
Ban
The ban method invalidates cached content based on specific criteria, such as a URL pattern or header. When a ban request is received, any cached content that matches the specified criteria is immediately removed, and subsequent requests for the content will be served directly from the origin server.
Stale-While-Revalidate
This method is used in web browsers and CDNs to serve stale content from the cache while the content is being updated in the background. When a request is received for a piece of content, the cached version is immediately served to the user, and an asynchronous request is made to the origin server to fetch the latest version of the content. Once the latest version is available, the cached version is updated.
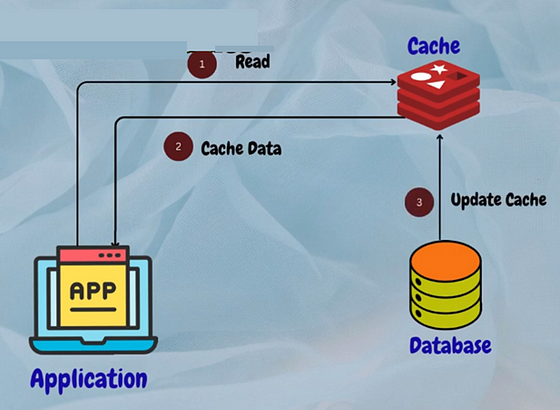
This method ensures that the user is always served content quickly, even if the cached version is slightly outdated.
Cache Eviction
After the cache invalidation, it appears that the cache is full. But, the cache misses have increased tremendously. What steps should be taken next? We need to make room in the cache for new items and reduce cache misses. This process, known as cache eviction, is crucial for optimizing cache performance.
Cache eviction refers to the process of removing items from a cache to make room for new entries when the cache reaches its capacity limit. Cache eviction policies determine which items are selected for removal based on certain criteria.
There are various cache eviction policies:
1. Least Recently Used (LRU)
Removes the least recently accessed items when space is needed for new entries. For instance, in a web browser’s cache using LRU, if the cache is full and a user visits a new webpage, the least recently accessed page is removed to make room for the new one.
2. Most Recently Used (MRU)
Evicts the most recently accessed items to free up space when necessary. For example, in a mobile app cache, if the cache is full and a user accesses a new feature, the most recently accessed feature is evicted to accommodate the new data.
3. First-In-First-Out (FIFO)
Evicts items based on the order they were added to the cache. In a FIFO cache, the oldest items are removed first when space is required. For instance, in a messaging app, if the cache is full and a new message arrives, the oldest message in the cache is evicted.
4. Least Frequently Used (LFU)
Removes items that are accessed the least frequently. LFU keeps track of access frequency, and when space is limited, it removes items with the lowest access count. For example, in a search engine cache, less frequently searched queries may be evicted to make room for popular ones.
5. Random Replacement (RR)
Selects items for eviction randomly without considering access patterns. In a cache using RR, any item in the cache may be removed when space is needed. For instance, in a gaming app cache, when new game assets need to be cached, RR randomly selects existing assets to replace.
Each cache eviction policy has its advantages and disadvantages, and the choice depends on factors such as the application’s access patterns, memory constraints, and performance requirements.
The e-commerce platform in our example has implemented a caching solution, leading to noticeable improvements in website performance. However, several cache-related issues have recently emerged.
Cache-related problems occur due to issues such as multiple users or processes accessing data simultaneously, outdated cached data, limited cache size, network problems, incorrect cache configurations, implementation errors, dependencies on external systems, and inadequate cache warming strategies.
Common Cache-Related Problems and Solutions
1. Thundering Herd Problem
This occurs when multiple requests simultaneously trigger cache misses, overwhelming the system.
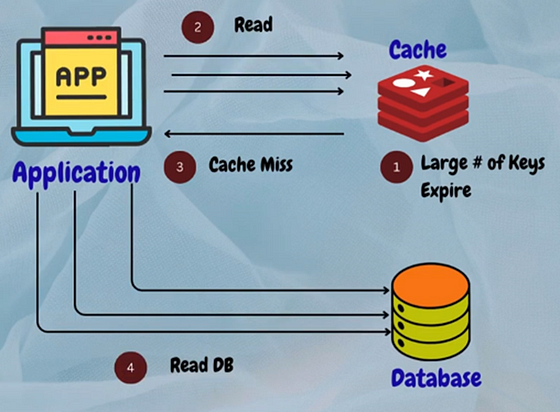
Solution
Implement cache warming techniques to pre-load frequently accessed data into the cache during low-traffic periods.
2. Cache Penetration
This happens when malicious users bombard the system with requests for non-existent data, bypassing the cache and causing unnecessary load on the backend.
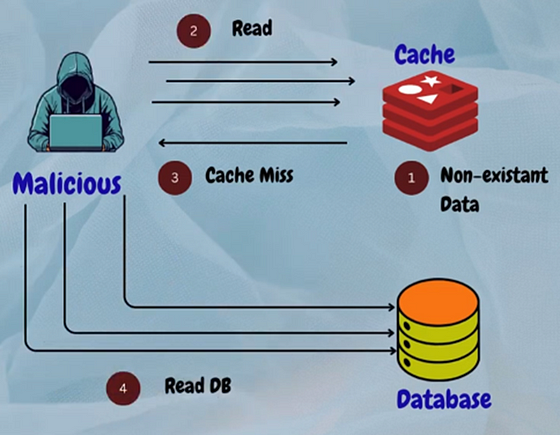
Solution
Implement input validation and rate limiting to mitigate the impact of cache penetration attacks.
3. Cache Breakdown
This occurs when the cache becomes unavailable or unresponsive, leading to increased load on the backend database.
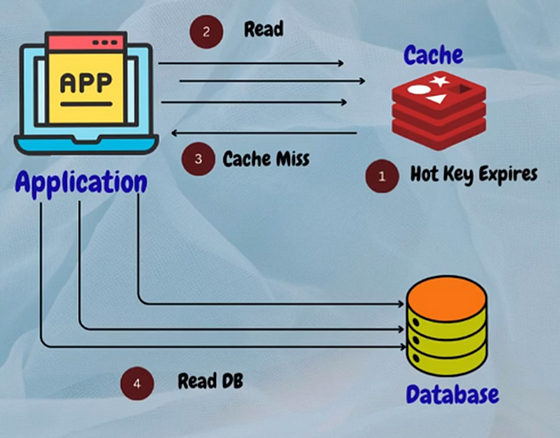
Solution
Implement cache redundancy and failover mechanisms to ensure high availability and fault tolerance.
4. Cache Crash
This happens when the cache experiences failures or crashes due to software bugs or hardware issues.
Solution
Regularly monitor cache health and performance, and implement automated recovery mechanisms to quickly restore cache functionality.
In companies like Amazon, Netflix, Meta, Google and eBay distributed caching solutions like Redis or Memcached are commonly used for caching dynamic data, while CDNs are employed for caching static content and optimizing content delivery to users.
Summary
In summary, caching is vital for optimizing system performance in high-traffic environments. Strategies like read-through cache and cache-aside cater to diverse needs, while invalidation methods ensure data accuracy. However, issues like thundering herds and cache breakdowns pose challenges. Solutions like cache warming and redundancy mitigate these problems, ensuring system resilience. Overall, a well-designed caching strategy is essential for delivering optimal performance in dynamic digital landscapes.
Video
Must Read for Continuous Learning
- Head First Design Patterns
- Clean Code: A Handbook of Agile Software Craftsmanship
- Java Concurrency in Practice
- Java Performance: The Definitive Guide
- Designing Data-Intensive Applications
- Designing Distributed Systems
- Clean Architecture
- Kafka — The Definitive Guide
- Becoming An Effective Software Engineering Manager
Published at DZone with permission of Roopa Kushtagi. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments