Changing Attitudes and Approaches Towards Privacy, AI, and IoT
Big data, IoT, and AI have all contributed to the widespread use of personal info. The privacy debate is at a crossroads where the public, authorities, and companies must decide in which direction the industry will turn.
Join the DZone community and get the full member experience.
Join For FreePrivacy differs from culture to culture, and changes along with technological advancements and sociopolitical events. Privacy today is a very fluid subject — a result of major changes that took place in the last five or so years.
The big bang of privacy awareness happened in June 2013, when the Snowden leaks came to light. The public was exposed to surveillance methods executed by the governments of the world, and privacy became a hot topic. Meanwhile, data collection continued, and by 2015, almost 90 percent of the data gathered by organizations was collected within only two years. Compare this with only 10 percent of data being collected before 2013. People started to realize that a person could be analyzed according to online behavior, and a complete profile of social parameters like social openness, extraversion, agreeableness, and neuroticism could be created from just ten likes on Facebook.
Google Chief Economist Hal Varian wrote in 2014, “There is no putting the genie back in the bottle. Widespread sensors, databases, and computational power will result in less privacy in today’s sense, but will also result in less harm due to the establishment of social norms and regulations about how to deal with privacy issues.”
In 2015, at the height of The Privacy Paradox, the general belief was that privacy would soon reach a tipping point with regulatory crackdowns on big companies and public demand for better protection. By late 2016, it was clear that the European Union was set to approve the new General Data Protection Regulation.
Privacy views continued to evolve in 2016. A survey of American consumers showed a drastic change in public opinion from only one year earlier. Ninety-one percent of respondents strongly agreed that users had lost control of how their data was collected and used. When asked again whether collecting data in exchange for improved services was okay, 47 percent approved, while only 32 percent thought it wasn’t acceptable — a drop of 39 percent in just one year. The feelings of powerlessness for “losing control of their data” changed to a more businesslike approach; users were willing to cooperate with the data collection in exchange for better services.
This shift continues with the realization that users are willing to exchange their data for personalized services and rewards. A survey conducted by Microsoft found that 82 percent of participants were ready to share activity data, and 79 percent were willing to share their private profile data, like gender, in exchange for better services. This correlated with the change in the willingness to purchase adaptive products. Fifty-six percent stated they were more likely to buy products that were adapting to their personal lives, rather than non-adaptive products.
This correlates with the first real commercial use of an AI service to personalize user apps and IoT devices to match users’ physical world personas, preferences, and needs. As users have seen the value of personalized experience, they have relaxed their grip on accessing their personalized data. It should be noted that this is not the same thing as more targeted advertising. When users think they are allowing access to their data or relevant notifications and products that anticipate their needs, and receive advertising instead, they are disappointed, annoyed, and in some cases, hostile. In other words, if the user feels they’ve been deceived, they are less likely to trust that brand and possibly other AI-enhanced apps and products in the near future.
As companies plan to integrate AI into their apps and IoT devices, they must be aware of the changes in privacy cultural norms and newly enacted laws. Prior to 2017, the most common reply regarding private data collection was, “you don’t have to be afraid if you don’t have anything to hide.” In 2017, we realized the power lies not in the secrets one might have, but in understanding one’s daily routines and behaviors. We have moved beyond the issue of individuals being tracked for the sake of ads. It has become a story of tracking for the sake of building social-psychological profiles and executing micro-campaigns, so users will act the way you want them to in the real world.
Two important privacy-related acts of 2017 were the removal of restrictions on data trading in the US and stricter regulation on data trading in the EU. Companies will need to know both to navigate privacy regulations in the global economy.
The most obvious, basic difference between the two approaches is that the European law includes the right to be forgotten, while the American law doesn’t. The European model says there should be strict regulations, followed by heavy penalties to the disobedient, to protect the end user from data collectors. The American model is more of a free market approach where everything is for sale, and in the end, the market will create the balance that is needed. It’s no coincidence that Europe, with its historical understanding of the dangers of going without privacy protection, has privacy laws that are much stricter than in the US. Juxtaposed with both approaches is the Chinese/Russian model, which says the state is the owner of the data, not the companies or the citizens.
And yet, despite all their fears and worries, most of the participants are not afraid to use the technology and have more than four devices connected to the internet. For example, 90 percent of young American adults use social media on a daily basis, and online shopping has never been better — almost 80 percent of Americans are making one purchase per month. It seems that on one hand, users are aware of the risks and problems the technology presents today, and on the other hand, most are heavy consumers of that technology.
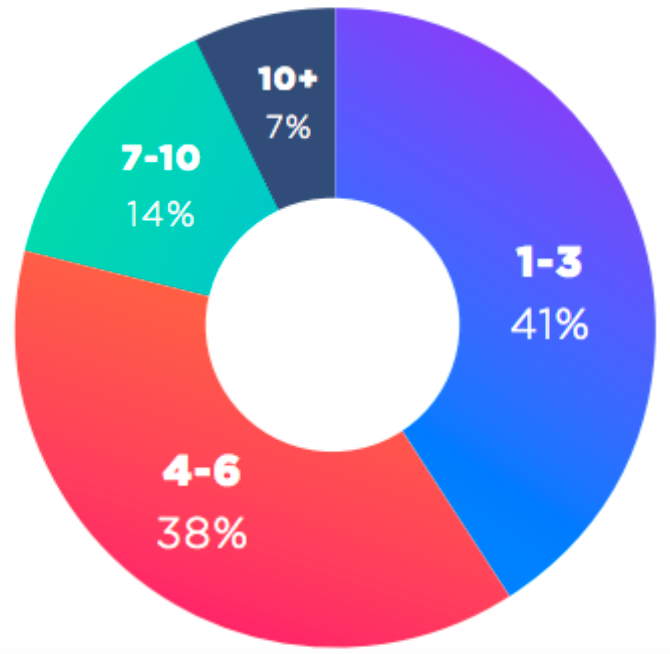
Figure 1: The number of devices people own that connect to the internet (i.e. computers, phones, fitness trackers, Internet-connected cars, Wi-Fi routers, cable boxes, etc.).
The average person uses various digital services and technologies that provide a lot of data to whoever collects it. Since most of the services by themselves are not harmful, or at least don’t mean any harm, there should be no problem, right?
Well, not exactly.
Today’s massive data collection has brought us to a place where our privacy is at risk. It is dependent on a partnership between organizations and consumers to ensure cultural and legal privacy standards are met.
Since there is so much at stake, companies need to take a stand regarding their approach toward privacy. The right solution is a model of transparency and collaboration with the users. This model assumes that private data should be owned by the users, and anyone who wishes to approach the users’ private data should ask their permission and explain why the data is needed. This way, we provide transparency and understanding of the data sharing to all sides. This is particularly important when collecting data that will learn a user’s persona and predict their needs or actions. AI holds great potential for user awareness and personalized experience that result in increased engagement and reduced churn. However, technology innovators must understand the benefits of AI can only be realized if users are willing, possibly even enthusiastic participants. It’s up to organizations collecting and utilizing user data to follow cultural norms and legal requirements. Only then will AI-enhanced apps and products reach their full potential.
Opinions expressed by DZone contributors are their own.
Comments