Chaos Engineering: Path To Build Resilient and Fault-Tolerant Software Applications
Chaos engineering is a methodology to test software applications by deliberately injecting failures and faults. Learn more in this article.
Join the DZone community and get the full member experience.
Join For FreeModern software applications are developed using the latest cutting-edge technology stack providing the ability to scale by leveraging distributed processing as well as cloud processing capabilities. Applications along with superlative processing capabilities also provide features like extensibility and reusability.
Another essential feature expected in modern-day applications is highly resilient systems providing the ability to respond to any kind of failures and disruptions. This will require the application to have excellent fault-tolerance capabilities and provide seamless services to the end users.
As part of system development methodologies, systems are tested thoroughly against all known test scenarios and likely use cases, but always remain exposed to unknown test conditions and exception scenarios. With this said, the focus is on SRE capabilities and rigorous testing of applications to pass through any kind of negative scenarios like unlikely disruptions and weak points. One key methodology is chaos engineering, used to rigorously test the application against all kinds of abnormal scenarios to identify system vulnerabilities and enhance the application for any breakdowns as part of chaos testing outcomes. This will be an ongoing process that will be performed for any enhancement to the application, or any new test scenario identified for the applications.
Chaos testing methodology relies on proactive and systematic testing of systems to identify errors, thus improving system resiliency to prevent outages and negative impacts on the business and the end users. The objective of chaos engineering is to unearth system restraints, susceptibilities, and possible failures in a controlled and planned manner before they exhibit perilous challenges resulting in severe impact on the organizations. Few of the most innovative organizations based on learning from past failures understood the importance of chaos engineering and realized it as a key strategy to unravel profound hidden issues to avoid any future failures and impacts on business.
Chaos engineering lets the application developers forecast and detect probable collapses by disrupting the system on purpose. The disruption points are identified and altered based on potential system vulnerabilities and weak points. This way the system deficiencies are identified and fixed before they degrade into an outage.
Chaos engineering is a growing trend for DevOps and IT teams. A few of the world’s most technologically innovative organizations like Netflix and Amazon are pioneers in adopting chaos testing and engineering. Today, many DevOps and IT teams are adopting chaos engineering as a methodology to proactively identify hidden issues.
In this article, we will take a closer look at the core principles of chaos engineering, its advantages and disadvantages, tools used for chaos engineering like Simian Army leveraging Chaos Monkeys, and which applications and use-cases should adopt chaos engineering.
What Is Chaos Engineering?
Chaos engineering lays out a set of principles and guidelines to proactively and systematically test an application to make it more robust and fault-tolerant by improving the resiliency of complex systems and applications.
Key Principles and Theories
Key principles and theories of chaos engineering are listed below:
- Define hypotheses testing
- Executing chaos experiments
- Controlled scaling of hypotheses
- Testing infrastructure hypotheses
- Observing the experiment
- Post-experiment analysis
- Analyzing results
- Iterating and learning
- Continuous iteration and improvement
Chaos engineering has gained popularity as cloud-native and distributed systems have become more prevalent. Chaos engineering has expanded acceptance with cloud-native and distributed systems thus becoming an integral part of system development strategy. By intentionally creating failures and disruptions in a controlled environment, organizations can build more robust, fault-tolerant systems that are better equipped to handle unexpected challenges in production. Chaos engineering helps reduce downtime, improve customer experiences, and increase the overall reliability of complex software systems.
Key Benefits
Listed below are a few of the key benefits achieved by applying chaos engineering to the system.
- The system will undergo rigorous testing for all the negative test scenarios and all expected vulnerable use cases are addressed to make the system more robust resulting in making the system more reliable and resilient.
- All the vulnerable scenarios are detected and addressed, which results in reducing the turnaround time to respond to any incident.
- Chaos engineering also helps in advancing technology and implementation team confidence and collaboration.
- This results in all the stakeholders gaining more confidence in the system, which results in increased stakeholder satisfaction.
- Lastly, this will result in improved application performance monitoring.
Key Principles and Theories Explained
Below is a detailed explanation of all the key principles and theories of Chaos Engineering:
1. Define Hypotheses Testing
Chaos engineers start by formulating hypotheses about the system. These hypotheses are based on real-world experiences and knowledge of the system's architecture.
- Identify critical scenarios for the system: Define chaos experiments for these critical scenarios by introducing controlled disturbances into the system, and modeling the identified critical scenarios. The objective is to examine how resilient the system is in response to these fabricated disturbances injected to assess the critical features in the system.
- Identify critical data elements used for the use cases onboarded in the system and assess the change to critical data elements during the planned disruptions.
- Other hypothesis scenarios to be covered: Network disruptions, DB disruptions, and infrastructure disruptions, like a few of the nodes in the cluster going down.
- Stress testing scenarios with identification of additional negative scenarios identified as weak spots and expected to break the system. SMEs are involved in assessing the system from both functional and technical perspectives to identify all such vulnerable points and hypotheses are defined on top of those identified scenarios.
- Define the hypothesis for all the identified items in the above list.
- Define any additional negative test scenarios along with exception test cases.
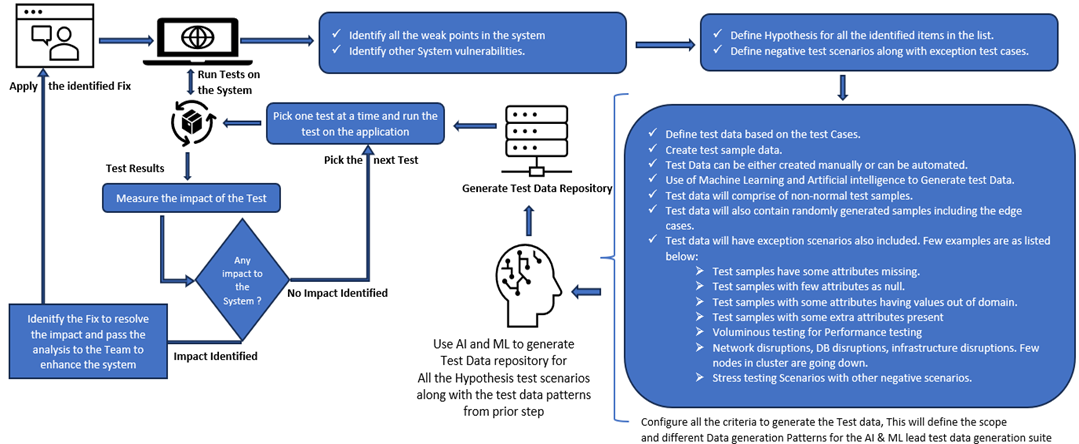
Once all the test hypotheses are defined, the test data is created based on the different kinds of scenarios identified for the test data creation. A few of the most prominent scenarios and patterns for the test data creation are listed below:
- Define test data based on the critical functionalities associated with the application.
- Test data will comprise of abnormal and unusual test conditions.
- Test data will contain critical data elements identified for the hypothesis testing.
- Test data will also contain randomly generated samples including the edge cases.
- Test data will have exception scenarios also included. A few examples are listed below:
- Test samples have a few of the critical data attributes missing
- Test samples with few critical attributes as null
- Test samples with some attributes having values out of domain
- Test samples with some extra attributes are present
- Voluminous testing for performance testing
- Test scenarios where some portion of the dataset is missing or not present from multiple different dataset scenarios needed for testing
Next, different test categories are created based on the type of hypothesis.
- Infrastructure hypothesis: Tools like Simian Army designed to simulate and test responses to simulated random disruptions and failures can be used. Leveraging such a tool will enable randomly terminated instances within the system; the tool simulates failures that can occur in real-world scenarios. Chaos Monkey, part of the Simian Army, helps organizations assess weaknesses in their system in a controlled environment through chaos engineering to address arcane and unpredictable failures.
- Negative functional hypothesis: This type of chaos testing will involve testing all the exceptional functional and non-functional scenarios. In this category of testing, all the weak and vulnerable scenarios identified in the prior step are to be tested.
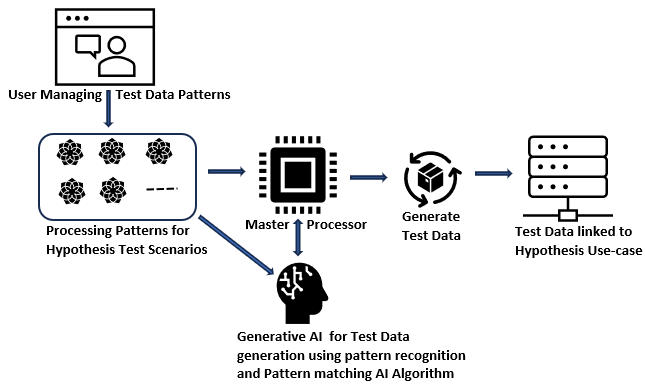
- Firstly, the test case and test data for such scenarios are prepared. For every hypothesis falling into this category, the test processing patterns are configured as depicted in the diagram below. Every pattern will represent one distinct processing scenario corresponding to a specific hypothesis. The pattern will contain the critical data elements and the data domains to be used in the processing scope, processing constructs, processing sequence, and expected outcome. To prepare the test data along with the testing steps and the sequence of execution steps, we can leverage AI and ML features. The generative AI technique can be leveraged to automate such scenarios. We can have a master processor that will control the entire test scenario automation process. The master processor will use the generative AI algorithms to read the processing pattern for a hypothesis.
- Next, based on pattern matching and pattern recognition algorithms, generative AI components will be able to generate testing steps along with generating the test data covering the negative test scenarios, exception scenarios, and edge cases.
- Finally, the test data generation component will be structuring all this into a format that can be used to generate the testing orchestration along with test data and expected outcomes for performing the testing.
2. Executing Chaos Experiments
In this step, all the hypotheses defined for the system will be executed one after another in a controlled manner. The functional and non-functional hypotheses will be run in a controlled structure. The key intention is to validate the hypotheses to ensure the system can endure those scenarios and still produce expected outcomes without any abnormality or disruption.
3. Controlled Scaling of Hypothesis
Generally, the system is exposed to simpler hypothesis scenarios first to test system resilience, and as it shows endurance to simpler scenarios, gradually the complexity and disruption scale is amplified to abate any risk of causing significant outages or damage. The system is exposed to brute force testing where all possible combinations of abnormal test data combinations are tested. Also, this is a test of the system's endurance, and a highly resilient system with exceptional error-handling capabilities will perform well in these tests. The final intent of this process is to enhance the system's capabilities to be highly fault-tolerant and handle and exit from fault scenarios gracefully.
4. Testing Infrastructure Hypotheses
Common chaos techniques include intentionally introducing flaws to a system to make certain it can weather and reclaim from faulty conditions. All the infrastructure hypotheses scenarios explained above will be tested in this step. Testing infrastructure hypotheses can be automated using tools available in the market like Simian Army and Spinnaker (Chaos Monkey is fully integrated with Spinnaker) which can inject all kinds of infrastructure vulnerabilities into the system to assess the system performance. A few commonly assessed flaws are network latency, simulating hardware failures, distributed processing nodes going down, API-centric applications abruptly bringing down APIs, randomly terminating processes, and other forms of fault injection. This type of chaos engineering is usually tested in higher environments like a UAT or pre-production environment, prior to deployment to production to discover any prospective flaws that may have been uncovered during production. A fault is injected into the source code during the application deployment time. It introduces a failure of a system to validate its robustness. The code changes can include the addition or modification of a code. These controlled disruptions help identify system weaknesses and vulnerabilities.
5. Observing the Experiment
This step involves closely examining the system's behavior to assess the impact of interruptions and gather data for analysis.
6. Post-Experiment Analysis
After conducting chaos experiments, engineers analyze the results to determine whether the system behaved as expected and to identify areas for improvement. Successful experiments often lead to refinements in system architecture, configurations, and processes.
7. Analyzing Results
After the experiment is completed, chaos engineers analyze the results to determine whether their hypotheses are correct. They assess whether the system's behavior aligned with their expectations or if there were unexpected outcomes. This analysis includes examining metrics, logs, and other observability data.
8. Iterating and Learning
Based on the analysis of the results, engineers iterate on the system's design, configurations, or processes to enhance its resilience. If a hypothesis is validated and the system behaves as expected, it may reinforce confidence in the system's reliability. If a hypothesis is invalidated, it may lead to improvements and adjustments to make the system more robust. This step involves iterating through all the defined hypotheses for the system, testing all hypotheses in an iterative manner, and improving the system to overcome any shortcomings or faults encountered during the chaos testing.
9. Continuous Iteration and Improvement
Chaos engineering is an ongoing process. As the system develops, new hypotheses are created, and new tests are added to the list of chaos test repositories to continuously enhance the system's resilience. It involves SMEs to periodically assess and identify any new scenario and add to the list of tests to enhance the test cases on the system's functional and non-functional features, and resilience mechanisms based on the lessons learned from previous experiments. Hypothesis testing and chaos experiments are part of an ongoing, iterative process.
Examples
Below are a few examples of chaos scenarios:
- Introducing latency between services for a small percentage of the dataset
- Adding faulty data scenarios, like setting a few critical data elements as null or a value not from the given list of values
- Executing a routine in driver code emulating I/O errors
- Adding extra attributes to the input datasets
- Bringing down a few microservices for a service-based system
- Stopping the master node in the clustered application
- API throttling: Limiting the number of API calls a user can make in a selected period
- Altering the memory management for an application
- Bringing down DB instance for a multi-tier application to test seamless connection to backup DB
- Injecting some faulty data scenarios for an application
- Function-based chaos: Injecting a run-time scenario, causing functions to throw exceptions
- Faulty code insertion to the target program to validate its robustness
- Client-side vulnerabilities validation: Injection attacks, cross-site scripting, command injection, code injection, XML external entity (XXE) injection, XML external entity (XXE) injection, HTTP header injection (CRLF injection), NoSQL injection attacks
- Reducing the number of nodes in a cluster
- Test cyber resiliency through controlled but random experiments
- Testing on critical system resources outside of the normal range for an application
- The principles in chaos engineering can also be applied in other phases of application development and operations. One such scenario is of “canary analysis:" When new code is to be rolled out and deployed, the organization can start with having a controlled rollout by measuring the performance of the new features on a limited number of non-critical systems before deploying it more widely across all users. This eliminates the risk and impact on business and end users.
Conclusion
I hope this article was helpful in providing high-level insight into the internals of chaos engineering and different kinds of testing use cases and scenarios to be incorporated as part of chaos testing to enhance the SRE capabilities in the organization. The SRE is becoming an integral part of system development with cloud-based applications and microservice-based architecture. Chaos engineering brings value to the table to make such kind of applications robust, resilient, and fault-tolerant. The article provided a few perspectives and examples, but actual implementation will vary from application to application to define the scope for chaos testing based on the application features as well as functional and non-functional use cases applicable to the given system. One key intent of this article is to create awareness for chaos engineering to make it an integral part of the development lifecycle to build highly resilient and fault-tolerant applications.
Opinions expressed by DZone contributors are their own.
Comments