Code Coverage for Embedded Target with Eclipse, gcc and gcov
Join the DZone community and get the full member experience.
Join For FreeThe great thing with open source tools like Eclipse and GNU (gcc, gdb) is that there is a wealth of excellent tools: one thing I had in mind to explore for a while is how to generate code coverage of my embedded application. Yes, GNU and Eclipse come with code profiling and code coverage tools, all for free! The only downside seems to be that these tools seem to be rarely used for embedded targets. Maybe that knowledge is not widely available? So here is my attempt to change this :-).
Or: How cool is it to see in Eclipse how many times a line in my sources has been executed?

Line Coverage in Eclipse

And best of all, it does not stop here….

Coverage with Eclipse

To see how much percentage of my files and functions are covered?

gcov in Eclipse
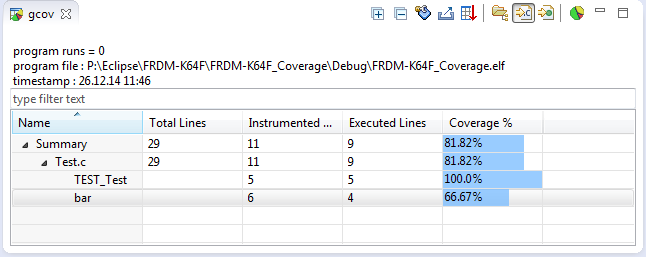
Or even to show the data with charts?

Coverage Bar Graph View

Outline
In this tutorial I’m using a Freescale FRDM-K64F board: this board has ARM Cortex-M4F on it, with 1 MByte FLASH and 256 KByte of RAM. The approach used in this tutorial can be used with any embedded target, as long there is enough RAM to store the coverage data on the target. I’m using Eclipse Kepler with the ARM Launchpad GNU tools (q3 2014 release), but with small modifications any Eclipse version or GNU toolchain could be used. To generate the Code Coverage information, I’m using gcov.

Freescale FRDM-K64F Board

Generating Code Coverage Information with gcov
gcov is an open source program which can generate code coverage information. It tells me how often each line of a program is executed. This is important for testing, as that way I can know which parts of my application actually has been executed by the testing procedures. Gcov can be used as well for profiling, but in this post I will use it to generate coverage information only.
The general flow to generate code coverage is:
- Instrument code: Compile the application files with a special option. This will add (hidden) code and hooks which records how many times a piece of code is executed.
- Generate Instrumentation Information: as part of the previous steps, the compiler generates basic block and line information. This information is stored on the host as *.gcno (Gnu Coverage Notes Object?) files.
- Run the application: While the application is running on the target, the instrumented code will record how many the lines or blocks in the application are executed. This information is stored on the target (in RAM).
- Dump the recorded information: At application exit (or at any time), the recorded information needs to be stored and sent to the host. By default gcov stores information in files. As a file system might not be alway available, other methods can be used (serial connection, USB, ftp, …) to send and store the information. In this tutorial I show how the debugger can be used for this. The information is stored as *.gcda (Gnu Coverage Data Analysis?) files.
- Generate the reports and visualize them with gcov.

General gcov Flow
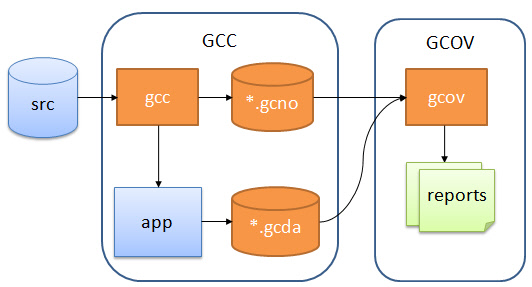
gcc does the instrumentation and provides the library for code coverage, while gcov is the utility to analyze the generated data.
Coverage: Compiler and Linker Options
To generate the *.gcno files, the following option has to be added for each file which should generate coverage information:
-fprofile-arcs -ftest-coverage
:idea: There is as well the ‘–coverage’ option (which is a shortcut option) which can be used both for the compiler and linker. But I prefer the ‘full’ options so I know what is behind the options.
-fprofile-arcs Compiler Option
The option -fprofile-arcs adds code to the program flow to so execution of source code lines are counted. It does with instrumenting the program flow arcs. From https://gcc.gnu.org/onlinedocs/gcc/Debugging-Options.html:
-fprofile-arcs Add code so that program flow arcs are instrumented. During execution the program records how many times each branch and call is executed and how many times it is taken or returns. When the compiled program exits it saves this data to a file called auxname.gcda for each source file. The data may be used for profile-directed optimizations (-fbranch-probabilities), or for test coverage analysis (-ftest-coverage). Each object file’s auxname is generated from the name of the output file, if explicitly specified and it is not the final executable, otherwise it is the basename of the source file. In both cases any suffix is removed (e.g. foo.gcda for input file dir/foo.c, or dir/foo.gcda for output file specified as -o dir/foo.o). See Cross-profiling.
If you are not familiar with compiler technology or graph theory: An ‘Arc‘ (alternatively ‘edge’ or ‘branch’) is a directed link between a pair ‘Basic Blocks‘. A Basic is a sequence of code which has no branching in it (it is executed in a single sequence). For example if you have the following code:
k = 0;
if (i==10) {
i += j;
j++;
} else {
foo();
}
bar();
Then this consists of the following four basic blocks:

Basic Blocks

The ‘Arcs’ are the directed edges (arrows) of the control flow. It is important to understand that not every line of the source gets instrumented, but only the arcs: This means that the instrumentation overhead (code size and data) depends how ‘complicated’ the program flow is, and not how many lines the source file has.
However, there is an important aspect to know about gcov: it provides ‘condition coverage‘ if a full expression evaluates to TRUE or FALSE. Consider the following case:
if (i==0 || j>=20) {
In other words: I get coverage how many times the ‘if’ has been executed, but *not* how many times ‘i==0′ or ‘j>=20′ (which would be ‘decision coverage‘, which is not provided here). See http://www.bullseye.com/coverage.html for all the details.
-ftest-coverage Compiler Option
The second option for the compiler is -ftest-coverage (from https://gcc.gnu.org/onlinedocs/gcc-3.4.5/gcc/Debugging-Options.html):
-ftest-coverage Produce a notes file that the gcov code-coverage utility (see gcov—a Test Coverage Program) can use to show program coverage. Each source file’s note file is called auxname.gcno. Refer to the -fprofile-arcs option above for a description of auxname and instructions on how to generate test coverage data. Coverage data will match the source files more closely, if you do not optimize.
So this option generates the *.gcno file for each source file I decided to instrument:

gcno file generated

This file is needed later to visualize the data with gcov. More about this later.
Adding Compiler Options
So with this knowledge, I need to add
-fprofile-arcs -ftest-coverage
as compiler option to every file I want to profile. It is not necessary profile the full application: to save ROM and RAM and resources, I can add this option only to the files needed. Actually as a starter, I recommend to instrument a single source file only at the beginning. For this I select the properties (context menu) of my file Test.c I add the options in ‘other compiler flags':

Coverage Added to Compilation File

-fprofile-arcs Linker Option
Profiling not only needs a compiler option: I need to tell the linker that it needs to link with the profiler library. For this I add
-fprofile-arcs
to the linker options:

-fprofile-arcs Linker Option

Coverage Stubs
Depending on your library settings, you might now get a lot of unresolved symbol linker errors. This is because by default the profiling library assumes to write the profiling information to a file system. However, most file systems do *not* have a file system. To overcome this, I add a stubs for all the needed functions. I have them added with a file to my project (see latest version of that file on GitHub):
/*
* coverage_stubs.c
*
* These stubs are needed to generate coverage from an embedded target.
*/
#include <stdio.h>
#include <stddef.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <errno.h>
#include "UTIL1.h"
#include "coverage_stubs.h"
/* prototype */
void gcov_exit(void);
/* call the coverage initializers if not done by startup code */
void static_init(void) {
void (**p)(void);
extern uint32_t __init_array_start, __init_array_end; /* linker defined symbols, array of function pointers */
uint32_t beg = (uint32_t)&__init_array_start;
uint32_t end = (uint32_t)&__init_array_end;
while(beg<end) {
p = (void(**)(void))beg; /* get function pointer */
(*p)(); /* call constructor */
beg += sizeof(p); /* next pointer */
}
}
void _exit(int status) {
(void) status;
gcov_exit();
for(;;){} /* does not return */
}
static const unsigned char *fileName; /* file name used for _open() */
int _write(int file, char *ptr, int len) {
static unsigned char gdb_cmd[128]; /* command line which can be used for gdb */
(void)file;
/* construct gdb command string */
UTIL1_strcpy(gdb_cmd, sizeof(gdb_cmd), (unsigned char*)"dump binary memory ");
UTIL1_strcat(gdb_cmd, sizeof(gdb_cmd), fileName);
UTIL1_strcat(gdb_cmd, sizeof(gdb_cmd), (unsigned char*)" 0x");
UTIL1_strcatNum32Hex(gdb_cmd, sizeof(gdb_cmd), (uint32_t)ptr);
UTIL1_strcat(gdb_cmd, sizeof(gdb_cmd), (unsigned char*)" 0x");
UTIL1_strcatNum32Hex(gdb_cmd, sizeof(gdb_cmd), (uint32_t)(ptr+len));
return len; /* on success, return number of bytes written */
}
int _open (const char *ptr, int mode) {
(void)mode;
fileName = (const unsigned char*)ptr; /* store file name for _write() */
return 0; /* success */
}
int _close(int file) {
(void) file;
return 0; /* success closing file */
}
int _fstat(int file, struct stat *st) {
(void)file;
(void)st;
st->st_mode = S_IFCHR;
return 0;
}
int _getpid(void) {
return 1;
}
int _isatty(int file) {
switch (file) {
case STDOUT_FILENO:
case STDERR_FILENO:
case STDIN_FILENO:
return 1;
default:
errno = EBADF;
return 0;
}
}
int _kill(int pid, int sig) {
(void)pid;
(void)sig;
errno = EINVAL;
return (-1);
}
int _lseek(int file, int ptr, int dir) {
(void)file;
(void)ptr;
(void)dir;
return 0; /* return offset in file */
}
#pragma GCC diagnostic push
#pragma GCC diagnostic ignored "-Wreturn-type"
__attribute__((naked)) static unsigned int get_stackpointer(void) {
__asm volatile (
"mrs r0, msp \r\n"
"bx lr \r\n"
);
}
#pragma GCC diagnostic pop
void *_sbrk(int incr) {
extern char __HeapLimit; /* Defined by the linker */
static char *heap_end = 0;
char *prev_heap_end;
char *stack;
if (heap_end==0) {
heap_end = &__HeapLimit;
}
prev_heap_end = heap_end;
stack = (char*)get_stackpointer();
if (heap_end+incr > stack) {
_write (STDERR_FILENO, "Heap and stack collision\n", 25);
errno = ENOMEM;
return (void *)-1;
}
heap_end += incr;
return (void *)prev_heap_end;
}
int _read(int file, char *ptr, int len) {
(void)file;
(void)ptr;
(void)len;
return 0; /* zero means end of file */
}
:idea: In this code I’m using the UTIL1 (Utility) Processor Expert component, available on SourceForge. If you do not want/need this, you can remove the lines with UTIL1.
-

Coverage Stubs File in Project

Coverage Constructors
There is one important thing to mention: the coverage data structures need to be initialized, similar to constructors for C++. Depending on your startup code, this might *not* be done automatically. Check your linker .map file for some _GLOBAL__ symbols:
.text._GLOBAL__sub_I_65535_0_TEST_Test 0x0000395c 0x10 ./Sources/Test.o
Such a symbol should exist for every source file which has been instrumented with coverage information. These are functions which need to be called as part of the startup code. Set a breakpoint in your code at the given address to check if it gets called. If not, you need to call it yourself.
:!: Typically I use the linker option ‘-nostartfiles’), and I have my startup code. In that case, these constructors are not called by default, so I need to do myself. See http://stackoverflow.com/questions/6343348/global-constructor-call-not-in-init-array-section
In my linker file I have this:
.init_array :
{
PROVIDE_HIDDEN (__init_array_start = .);
KEEP (*(SORT(.init_array.*)))
KEEP (*(.init_array*))
PROVIDE_HIDDEN (__init_array_end = .);
} > m_text
This means that there is a list of constructor function pointers put together between __init_array_start and __init_array_end. So all what I need is to iterate through this array and call the function pointers:
/* call the coverage initializers if not done by startup code */
void static_init(void) {
void (**p)(void);
extern uint32_t __init_array_start, __init_array_end; /* linker defined symbols, array of function pointers */
uint32_t beg = (uint32_t)&__init_array_start;
uint32_t end = (uint32_t)&__init_array_end;
while(beg<end) {
p = (void(**)(void))beg; /* get function pointer */
(*p)(); /* call constructor */
beg += sizeof(p); /* next pointer */
}
}
So I need to call this function as one of the first things inside main().
Heap Management
The other aspect of the coverage library is the heap usage. At the time of dumping the data, it uses malloc() to allocate heap memory. As typically my applications do not use malloc(), I still need to provide a heap for the profiler. Therefore I provide a custom sbrk() implementation in my coverage_stubs.c:
void *_sbrk(int incr) {
extern char __HeapLimit; /* Defined by the linker */
static char *heap_end = 0;
char *prev_heap_end;
char *stack;
if (heap_end==0) {
heap_end = &__HeapLimit;
}
prev_heap_end = heap_end;
stack = (char*)get_stackpointer();
if (heap_end+incr > stack) {
_write (STDERR_FILENO, "Heap and stack collision\n", 25);
errno = ENOMEM;
return (void *)-1;
}
heap_end += incr;
return (void *)prev_heap_end;
}
:!: It might be that several kBytes of heap are needed. So if you are running in a memory constraint system, be sure that you have enough RAM available.
The above implementation assumes that I have space between my heap end and the stack area.
:!: If your memory mapping/linker file is different, of course you will need to change that _sbrk() implementation.
Compiling and Building
Now the application should compile and link without errors.Check that the .gcno files are generated:
:idea: You might need to refresh the folder in Eclipse.
-

.gcno files generated

In the next steps I’m showing how to get the coverage data as *.gcda files to the host using gdb.
Using Debugger to get the Coverage Data
The coverage data gets dumped when _exit() gets called by the application. Alternatively I could call gcov_exit() or __gcov_flush() any time. What it then does is
- Open the *.gcda file with _open() for every instrumented source file.
- Write the data to the file with _write().
So I can set a breakpoint in the debugger to both _open() and _write() and have all the data I need :-)
With _open() I get the file name, and I store it in a global pointer so I can reference it in _write():
static const unsigned char *fileName; /* file name used for _open() */
int _open (const char *ptr, int mode) {
(void)mode;
fileName = (const unsigned char*)ptr; /* store file name for _write() */
return 0;
}
In _write() I get a pointer to the data and the length of the data. Here I can dump the data to a file using the gdb command:
dump binary memory <file> <hexStartAddr> <hexEndAddr>
I could use a calculator to calculate the memory dump range, but it is much easier if I let the program generate the command line for gdb :-):
int _write(int file, char *ptr, int len) {
static unsigned char gdb_cmd[128]; /* command line which can be used for gdb */
(void)file;
/* construct gdb command string */
UTIL1_strcpy(gdb_cmd, sizeof(gdb_cmd), (unsigned char*)"dump binary memory ");
UTIL1_strcat(gdb_cmd, sizeof(gdb_cmd), fileName);
UTIL1_strcat(gdb_cmd, sizeof(gdb_cmd), (unsigned char*)" 0x");
UTIL1_strcatNum32Hex(gdb_cmd, sizeof(gdb_cmd), (uint32_t)ptr);
UTIL1_strcat(gdb_cmd, sizeof(gdb_cmd), (unsigned char*)" 0x");
UTIL1_strcatNum32Hex(gdb_cmd, sizeof(gdb_cmd), (uint32_t)(ptr+len));
return 0;
}
That way I can copy the string in the gdb debugger:

Generated GDB Memory Dump Command

That command gets pasted and executed in the gdb console:

gdb command line

After execution of the program, the *.gcda file gets created (refresh might be necessary to show it up):
gcda file created
Repeat this for all instrumented files as necessary.
Showing Coverage Information
To show the coverage information, I need the *.gcda, the *.gcno plus the .elf file.
:idea: Use Refresh if not all files are shown in the Project Explorer view

Files Ready to Show Coverage Information

Then double-click on the gcda file to show coverage results:

Double Click on gcda File
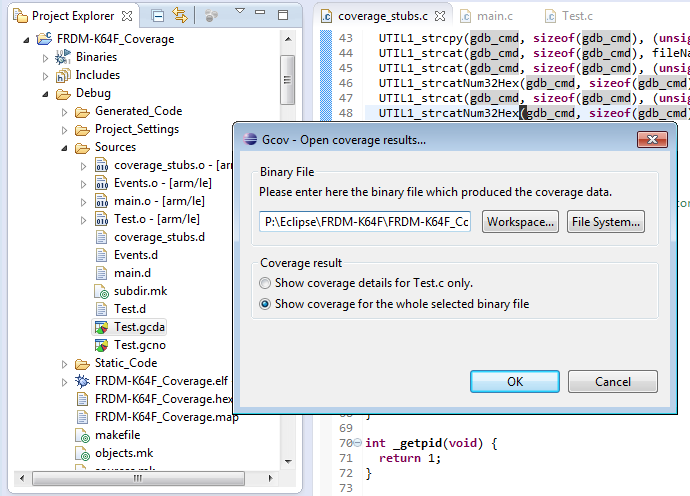
Press OK, and it opens the gcov view. Double click on file in that view to show the details:

gcov Views

Use the chart icon to create a chart view:

Chart view


Bar Graph View

Video of Steps to Create and Use Coverage
The following video summarizes the steps needed:
Data and Code Overhead
Instrumenting code to generate coverage information means that it is an intrusive method: it impacts the application execution speed, and needs extra RAM and ROM. How much heavily depends on the complexity of the control flow and on the number of arcs. Higher compiler optimizations would reduce the code size footprint, however optimizations are not recommended for coverage sessions, as this might make the job of the coverage much harder.
I made a quick comparison using my test application. I used the ‘size’ GNU command (see “Printing Code Size Information in Eclipse”).
Without coverage enabled, the application footprint is:
arm-none-eabi-size --format=berkeley "FRDM-K64F_Coverage.elf" text data bss dec hex filename 6360 1112 5248 12720 31b0 FRDM-K64F_Coverage.elf
With coverage enabled only for Test.c gave:
arm-none-eabi-size --format=berkeley "FRDM-K64F_Coverage.elf" text data bss dec hex filename 39564 2376 9640 51580 c97c FRDM-K64F_Coverage.elf
Adding main.c to generate coverage gives:
arm-none-eabi-size --format=berkeley "FRDM-K64F_Coverage.elf" text data bss dec hex filename 39772 2468 9700 51940 cae4 FRDM-K64F_Coverage.elf
So indeed there is some initial add-up because of the coverage library, but afterwards adding more source files does not add up much.
Summary
It took me a while and reading many articles and papers to get code coverage implemented for an embedded target. Clearly, code coverage is easier if I have a file system and plenty of resources available. But I’m now able to retrieve coverage information from a rather small embedded system using the debugger to dump the data to the host. It is not practical for large sets of files, but at least a starting point :-).
I have committed my Eclipse Kepler/Launchpad project I used in this tutorial on GitHub.
Ideas I have in my mind:
- Instead using the debugger/gdb, use FatFS and SD card to store the data
- Exploring how to use profiling
- Combining multiple coverage runs
Happy Covering :-)
Links:
- Blog article who helped me to explore gcov for embedded targets: http://simply-embedded.blogspot.ch/2013/08/code-coverage-introduction.html
- Paper about using gcov for Embedded Systems: http://sysrun.haifa.il.ibm.com/hrl/greps2007/papers/gcov-on-an-embedded-system.pdf
- Article about coverage options for GNU compiler and linker: http://bobah.net/d4d/tools/code-coverage-with-gcov
- How to call static constructor methods manually: http://stackoverflow.com/questions/6343348/global-constructor-call-not-in-init-array-section
- Article about using gcov with lcov: https://qiaomuf.wordpress.com/2011/05/26/use-gcov-and-lcov-to-know-your-test-coverage/
- Explanation of different coverage methods and terminology: http://www.bullseye.com/coverage.html
Published at DZone with permission of Erich Styger. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments