Coding Agents Need a Feedback Loop; Cloud-Native Systems Make That Hard
The utility of coding agents compounds with the quality of their feedback loop. In cloud-native systems, closing that loop involves solving two problems.
The first time I watched a coding agent finish a task in under a minute and then spent the next hour figuring out whether the change actually worked, I understood what the productivity numbers were hiding.
Generating the code was fast. Validating that it worked was not. It was slow because the change touched a service that talked to four other services, and there was no way for the agent to exercise that path without me standing up an environment, redeploying, and running the request myself. By the time I verified the change worked, I had spent more time validating than the agent had spent writing.
Coding agents are great for accelerating the rate of code generation and experimentation early in the development cycle. But the utility of an agent compounds with the quality of the feedback loop it has access to. An agent that can run its change and observe the result iterates on its own, catches its own mistakes, and hands over a PR the developer can trust without retracing every step.
An agent without that loop still produces code, but more of the correctness work falls back on the developer. In single-service codebases, closing this loop is fairly trivial. In cloud-native systems, providing that loop is much harder, and the gap determines how much of an agent's promised productivity actually materializes for distributed-systems teams.
What Validation Actually Means
In a single-service codebase with good test coverage, validation is well-understood. The agent writes a change, runs the tests, fixes the failures, and produces a diff that passes. Self-validation has become the default mode for modern coding agents: given access to a test runner, a linter, or a build command, an agent iterates against that feedback on its own and surfaces the result only once the checks pass.
The direction makes sense. A model that writes plausible code without checking it pushes more of the correctness work back to the developer. An agent that validates its own work iterates longer, catches more of its own mistakes, and produces output the developer can review at a higher level. The quality of the validation the agent can perform directly shapes how much of the review work stays with the agent rather than the human.
This works well for green-field work on a self-contained codebase or building on a monolith. The change is local, the tests are local, and the validation loop closes in the same process that the agent is already running in.
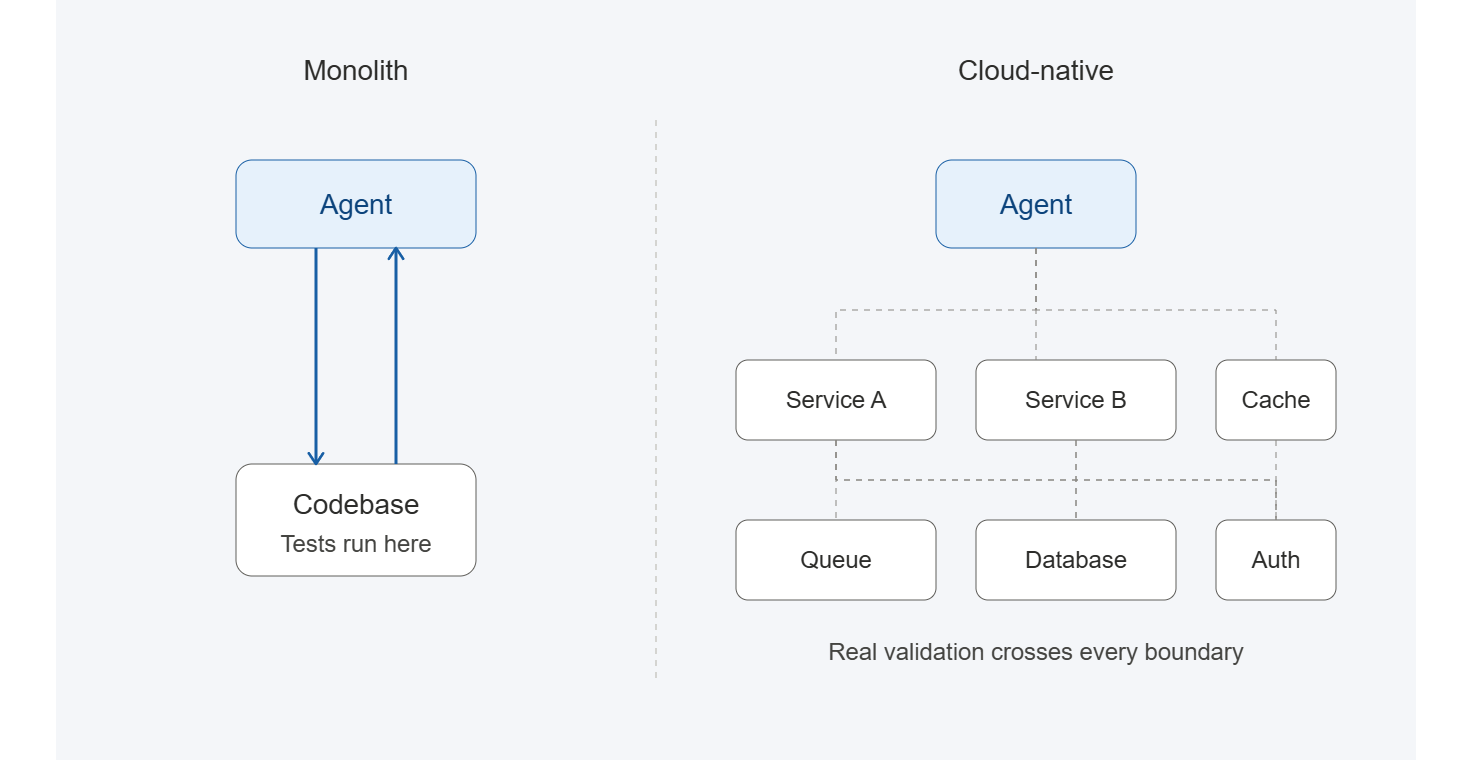
It works less well for a service inside a microservice architecture. The tests that matter in those systems are not "does my code pass its unit tests," but rather "does my change behave correctly when a real request flows through five services, hits the queue, lands in the database, and comes back through the cache."
That kind of test is difficult to mock convincingly. The mock returns whatever the agent told it to return, so an agent can pass its own integration tests without having meaningfully verified the integration. Real validation in distributed systems calls for real dependencies, real traffic, and a real environment. Providing those to every agent, at the pace agents operate, is where the difficulty lies.
The Shape of the Gap
Distributed-systems teams typically have one of two ways to give an agent a real environment, and both carry meaningful tradeoffs.
The first is to point the agent at the team's shared staging environment. This tends to break down quickly in practice. Multiple agents and developers pushing experimental changes into the same staging cluster interfere with each other. One bad change can destabilize staging for everyone, and the agent that caused it has no way to know its successful-looking run actually broke a teammate's parallel work.
The second is to give each agent its own full-stack ephemeral environment. This is cleaner in principle but expensive and slow in practice. Standing up the entire application stack, including all dependencies, takes minutes per environment. Multiplied across a team running multiple agents in parallel, the infrastructure cost becomes significant, and the spin-up time itself starts to bound how fast agents can iterate.
Neither approach gives the agent the feedback loop it actually needs: something that runs in seconds, exercises real dependencies, and stays out of the way of other developers and agents on the team.
What Is Needed to Close the Loop
A useful agent environment for cloud-native work has three properties, and the difficulty is satisfying all of them at once.
It has to be realistic. The agent is working on code that runs across service boundaries, so those boundaries need to exist in the environment and behave close to how they do in production. An environment that flattens or simplifies the topology ends up validating a version of the system that won't match what the code encounters when it moves to CI or ships.
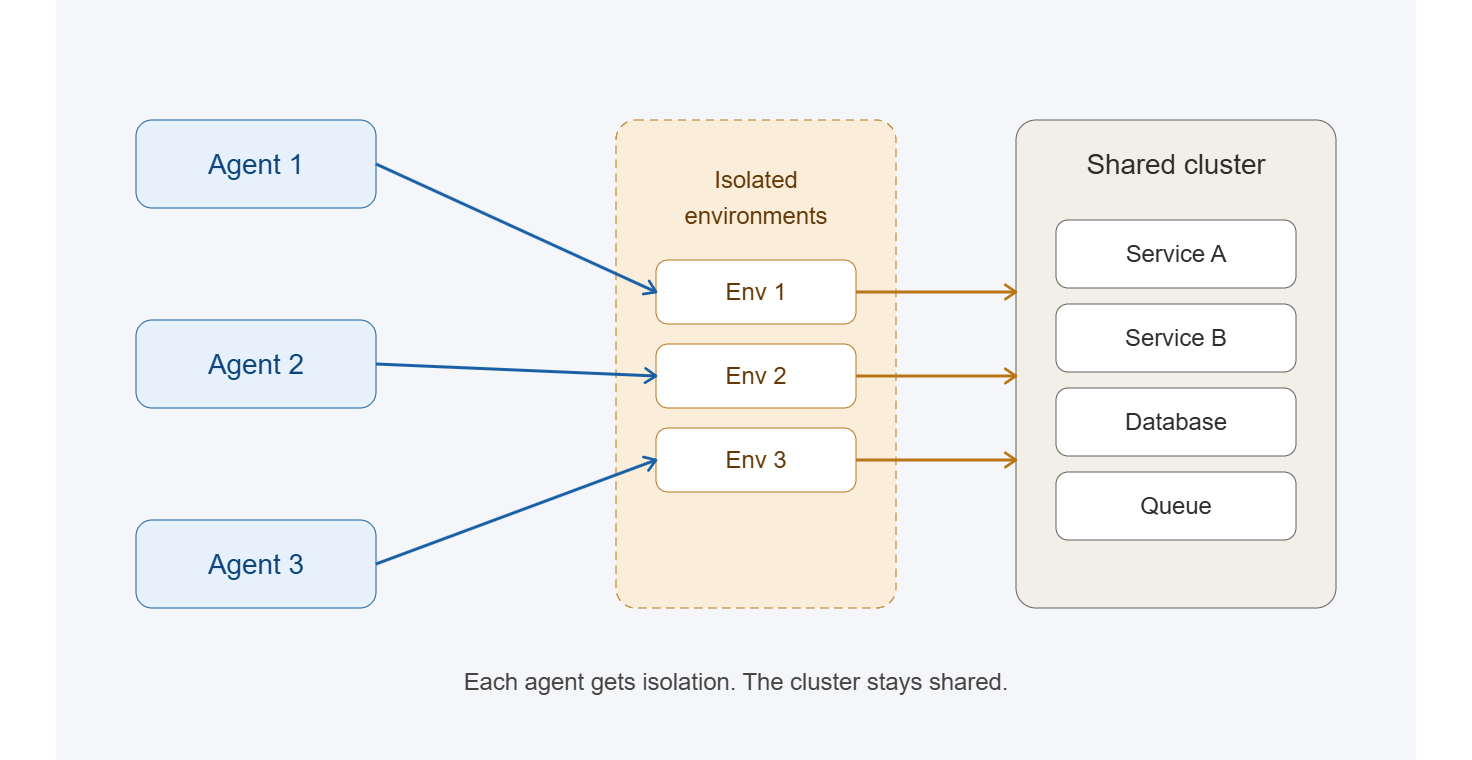
It has to be isolated. A realistic environment typically serves many agents and developers simultaneously, often against overlapping parts of the system. One agent's test run should not affect what anyone else sees. When validation becomes a coordination problem for the humans around it, the loop has closed for that agent at the cost of a bigger one for the team.
And it has to scale with how agents work. A team running coding agents is usually running many tasks at once, each on a different branch, each needing its own realistic place to validate. An approach that requires duplicating the full stack per agent becomes unrealistic at scale. The environment model has to keep the marginal cost of another in-flight agent low.
An environment that hits all three is the foundation for agent validation in cloud-native systems. The common off-the-shelf options, shared staging and per-task ephemeral stacks, each tend to fall short on at least one.
What is needed is a way to give each agent a local environment that duplicates only the service with their change, with isolated access to a stable shared environment to virtualize a realistic production-like environment without the spin-up cost or risk of contention.
Access Without Context Is Not Enough
An environment that satisfies those three properties is necessary but not sufficient. An agent with access to a production-like system and no guidance about how to use it tends to behave like a new engineer on their first day. The access is there. The judgment is not.
That judgment has two parts. The first is the team's operational knowledge about its own system: which upstream callers to exercise when a code path changes, which downstream dependencies actually affect the outcome, how to tell whether a failing request was caused by the change under review or by a flake three services away. This is the kind of knowledge a senior engineer on the team carries in their head, and a new hire learns over time.
The second is fluency with the tooling the environment provides: how to route traffic for testing, how to inspect state across services, which commands generate synthetic load or reset test data. This part is specific to the environment itself, and it is the difference between an agent that can act on its judgment and one that has opinions but no way to test them.
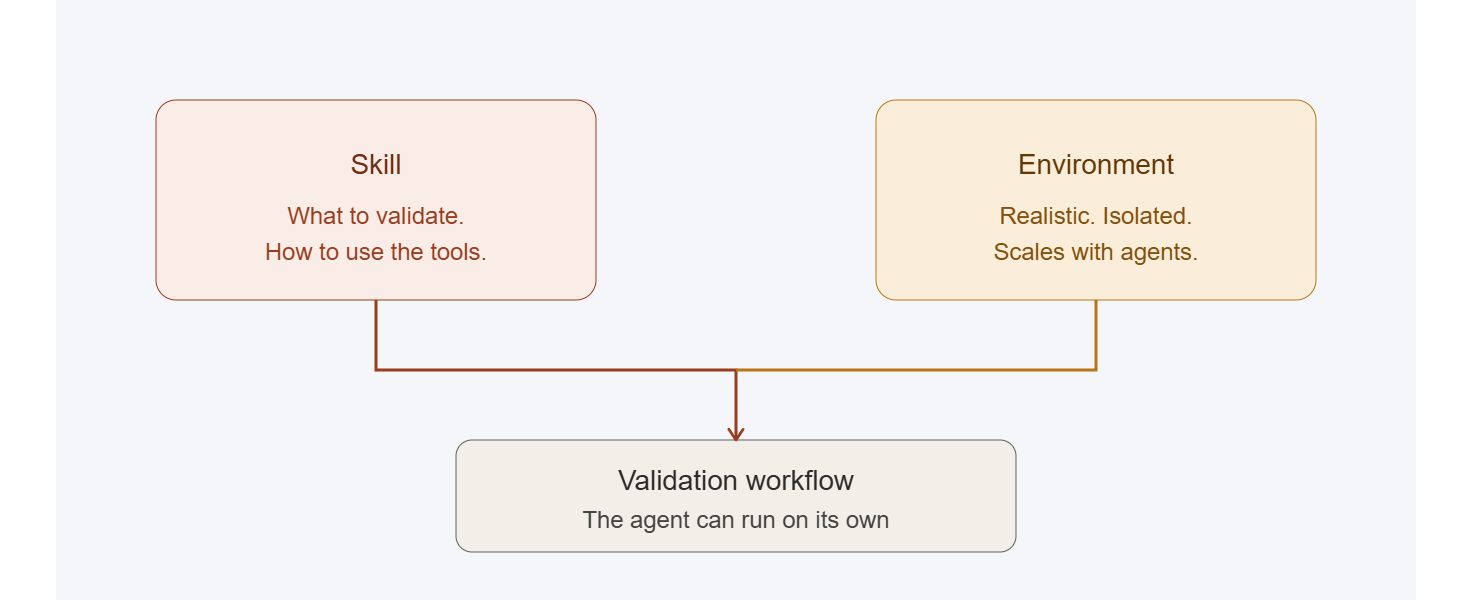
Agent skills have emerged as a lightweight way to address both. A skill can capture how changes in a particular system should be validated and debugged, plus how to drive the tools the environment provides to do that work. Handed to the agent alongside access, it is what turns raw access into a validation workflow the agent can actually run reliably.
Without the skill, the environment is a room full of equipment the agent doesn't know how to operate. Without the environment, the skill is a manual for machinery that isn't there.
Where This Is Going
Closing the validation loop changes more than how fast the individual agent runs completely. It changes how agents fit into the team's development cycle.
Today, the inner loop and the outer loop are largely separate. The inner loop is where a developer iterates against live dependencies in their own workspace. The outer loop is where CI runs the full test suite on a pull request.
Agents start to blur that line in both directions. When a test fails in CI, a natural next step for an agent is to drop the change back into an inner-loop environment, reproduce the failure against real dependencies, debug it, and push a fix. The outer loop's signal becomes the inner loop's starting condition.
It runs the other way, too. An ad-hoc validation that an agent runs once in the inner loop often deserves to outlive the task. Encoded into the outer loop, it becomes part of the team's standing regression suite.
Both directions rest on the same foundation: a realistic, isolated, agent-scale environment, plus skills that tell the agent how to use it. This is the problem we work on at Signadot, and it is the shape of solution we think cloud-native teams will increasingly need as they look to improve the utility of coding agents and address the growing review problem that agents without a closed loop create.
Note: Featured photo by Growtika on Unsplash
Check out the full Signadot article collection here.
Comments