Competing Consumers With Spring Boot and Hazelcast
Follow a simplified demo implementation of the competing Consumers pattern using Java, Spring Boot, and Hazelcast's distributed queue.
Join the DZone community and get the full member experience.
Join For FreeThe Competing Consumers pattern is a powerful approach that enables multiple consumer applications to process messages from a shared queue in a parallel and distributed manner. The implementation of this messaging pattern requires the utilization of a point-to-point channel. Senders deliver messages (or work items) to this channel and consumers compete with each other to be the receiver and process the message (i.e., perform some work based on the contents of the message) in an asynchronous and non-blocking manner.
How Does It Work?
Usually, a message broker (e.g., RabbitMQ, ActiveMQ) or a distributed streaming platform (e.g., Apache Kafka) is needed in order to provide the necessary infrastructure to implement this pattern. Producer applications connect to the broker and push messages to a queue (or a Kafka Topic with multiple partitions implemented as point-to-point channels). Then, consumer applications that are also connected to the broker, pull items from the queue (or belong to the same Kafka Consumer Group and pick up items from a designated partition). Each message is effectively delivered initially to only one available consumer or remains in the queue till a consumer becomes available.
Error Handling
In case of error during message processing, there are many things to consider that depending on the use case, may complicate things. Many brokers support acknowledgments and transactions while others rely on each microservice or application to implement its logic with its own choice of technology, communication paradigm, and error handling. If a consumer fails to send back an ACK after receiving and processing the message in a timely manner or rolls back the transaction when an exception occurs, the message may automatically (or based on application logic) be requeued or end up in a dead letter queue (DLQ).
However, there are always corner cases and scenarios that need attention. For example, if the consumer process has performed some work, and for some reason, "hangs" or there is a network error, then reprocessing the message may not be 100% safe. It depends on how idempotent the consumer processing logic is, and, depending on the use case, a manual inspection may be needed in order to decide if requeueing the message or processing it from a DLQ is ok. This is why we often run into delivery guarantee semantics like "at most once," "at least once," or "exactly once." The latter is the ideal, but in practice is technically impossible. Therefore aiming to achieve effectively once processing (i.e., as close as possible to "exactly once") should be our realistic goal.
In case of error messaging on the producer side, or if the message broker is unavailable, things are theoretically a bit less complicated. A recommended pattern to use on this side is the transactional outbox pattern. It involves storing messages in an "outbox" table or collection within the system's database and using a background process to periodically look up and deliver these messages. Only after the broker confirms it received the message, it is considered as sent.
Alternatives
Based on all the above, the existence of a central server that will act as the messaging broker seems essential. Actually, for production systems, we will need to set up a cluster consisting of multiple broker instances, running on separate VMs to ensure high availability, failover, replication, and so on. If for some reason this is not possible (operational costs, timelines, learning curve, etc.), other solutions exist that depending on the use case may cover our needs.

For simple cases, one could utilize a database table as a "queue" and have multiple consumer instances, polling the database periodically. If they find a record in a status appropriate for processing, then they have to apply a locking mechanism in order to make sure no other instance will duplicate the work. Upon finishing the task they need a release to update the status of the record and release the lock. Another solution is the one that we will demonstrate in the following sections. It relies on using Hazelcast in embedded mode and taking advantage of the distributed data structures it provides, namely the distributed queue.
Solution Description
For our demonstration, we will use 2 microservices implemented with Spring Boot: the Producer and the Consumer. Multiple instances of them can be executed. Hazelcast is included as a dependency on both of them, along with some basic Java configuration. As mentioned, Hazelcast will run in embedded mode, meaning that there will be no Hazelcast server. The running instances, upon startup, will use a discovery mechanism and form a decentralized cluster or Hazelcast IMDG (in-memory data grid). Hazelcast can also be used in the classic client-server mode. Each approach has its advantages and disadvantages. You may refer to Choosing an Application Topology for more details.
We have selected to have the Producers configured as Hazelcast "Members" and the consumers as Hazelcast "Clients." Let's have a look at the characteristics of each:
- Hazelcast Client: A Hazelcast client is an application that connects to a Hazelcast cluster to interact with it. It acts as a lightweight gateway or proxy to the Hazelcast cluster, allowing clients to access and utilize the distributed data structures and services provided by Hazelcast. The client does not store or own data; it simply communicates with the Hazelcast cluster to perform operations on distributed data. Clients can be deployed independently of the Hazelcast cluster and can connect to multiple Hazelcast clusters simultaneously. Clients are typically used for read and write operations, as well as for executing distributed tasks on the Hazelcast cluster. Clients can be implemented in various programming languages (Java, .NET, C++, Python, etc.) using the Hazelcast client libraries provided.
Hazelcast Member: A Hazelcast member refers to an instance of Hazelcast that is part of the Hazelcast cluster and participates in the distributed data grid. Members store data, participate in the cluster's data distribution and replication, and provide distributed processing capabilities. Members join together to form a Hazelcast cluster, where they communicate and collaborate to ensure data consistency and fault tolerance. Members can be deployed on different machines or containers, forming a distributed system. Each member holds a subset of the data in the cluster, and data is distributed across members using Hazelcast's partitioning strategy. Members can also execute distributed tasks and provide distributed caching and event-driven capabilities.
Deciding which microservice will be a Member vs a simple Client again depends on multiple factors such as data volume, processing requirements, network communication, resource utilization, and the possible restrictions of your system. For our example, here's the diagram with the selected architecture:

On the Producer side, which is a Hazelcast Member, we have enabled Queueing with Persistent Datastore. The datastore of choice is a PostgreSQL database.
In the following sections, we dive into the implementation details of the Producer and Consumer. You can find the complete source code over on the GitHub repository. Note that it includes a docker-compose file for starting the PostgreSQL database and the Hazelcast Management Center, which we will also describe later on.
The Producer
The Producer's Hazelcast configuration is the following:
@Configuration
public class HazelcastConfig {
@Value("${demo.queue.name}")
private String queueName;
@Value("${demo.dlq.name}")
private String dlqName;
@Bean
public HazelcastInstance hazelcastInstance(QueueStore<Event> queueStore) {
Config config = new Config();
QueueConfig queueConfig = config.getQueueConfig("main");
queueConfig.setName(queueName)
.setBackupCount(1)
.setMaxSize(0)
.setStatisticsEnabled(true);
queueConfig.setQueueStoreConfig(new QueueStoreConfig()
.setEnabled(true)
.setStoreImplementation(queueStore)
.setProperty("binary", "false"));
QueueConfig dlqConfig = config.getQueueConfig("main-dlq");
dlqConfig.setName(dlqName)
.setBackupCount(1)
.setMaxSize(0)
.setStatisticsEnabled(true);
config.addQueueConfig(queueConfig);
config.addQueueConfig(dlqConfig);
return Hazelcast.newHazelcastInstance(config);
}
}We define 2 queues:
- The "main" queue, which will hold the messages (Events) to be processed and is backed by the PostgreSQL QueueStore
- A "main-dlq," which will be used as a DLQ, and consumers will push items to it if they encounter errors
To keep it shorter, the DLQ is not backed by a persistent store. For a full explanation of configuration options and recommendations, refer to Hazelcast's Configuring Queue documentation.
Our PostgreSQL QueueStore implements the QueueStore<T> interface and we inject a Spring Data JPA Repository for this purpose:
@Component
@Slf4j
public class PostgresQueueStore implements QueueStore<Event> {
private final EventRepository eventRepository;
public PostgresQueueStore(@Lazy EventRepository eventRepository) {
this.eventRepository = eventRepository;
}
@Override
public void store(Long key, Event value) {
log.info("store() called for {}" , value);
EventEntity entity = new EventEntity(key,
value.getRequestId().toString(),
value.getStatus().name(),
value.getDateSent(),
LocalDateTime.now());
eventRepository.save(entity);
}
@Override
public void delete(Long key) {
log.info("delete() was called for {}", key);
eventRepository.deleteById(key);
}
// rest methods ommited for brevity...
} For testing purposes, the Producer includes a REST Controller with a single endpoint. Once invoked, it creates an Event object with a random UUID and offers it to the main queue:
@RestController
public class ProducerController {
@Value("${demo.queue.name}")
private String queueName;
private final HazelcastInstance hazelcastInstance;
public ProducerController(HazelcastInstance hazelcastInstance) {
this.hazelcastInstance = hazelcastInstance;
}
private BlockingQueue<Event> retrieveQueue() {
return hazelcastInstance.getQueue(queueName);
}
@PostMapping("/")
public Boolean send() {
return retrieveQueue().offer(Event.builder()
.requestId(UUID.randomUUID())
.status(Status.APPROVED)
.dateSent(LocalDateTime.now())
.build());
}
}
You can create a script or use a load-generator tool to perform more extensive testing. You may also start multiple instances of the Producer microservice and monitor the cluster's behavior via the LOGs and the Management Console.
The Consumer
Let's start again with the Consumer's Hazelcast configuration. This time we are dealing with a Hazelcast client:
@Configuration
public class HazelcastConfig {
@Value("${demo.queue.name}")
private String queueName;
@Value("${demo.dlq.name}")
private String dlqName;
@Bean
public HazelcastInstance hazelcastInstance() {
ClientConfig config = new ClientConfig();
// add more settings per use-case
return HazelcastClient.newHazelcastClient(config);
}
@Bean
public IQueue<Event> eventQueue(HazelcastInstance hazelcastInstance) {
return hazelcastInstance.getQueue(queueName);
}
@Bean
public IQueue<Event> dlq(HazelcastInstance hazelcastInstance) {
return hazelcastInstance.getQueue(dlqName);
}
}We are calling the HazelcastClient.newHazelcastClient() method this time in contrast to Hazelcast.newHazelcastInstance() on the Producer side. We are also creating 2 beans corresponding to the queues we will need access to; i.e., the main queue and the DLQ.
Now, let's have a look at the message consumption part. Hazelcast library does not offer a pure event-based listener approach (see related GitHub issue). The only way of consuming a new queue entry is through the queue.take() blocking method (usually contained in a do...while loop). To make this more "resource-friendly" and to avoid blocking the main thread of our Spring-based Java application, we will perform this functionality in background virtual threads:
@Component
@Slf4j
public class EventConsumer {
@Value("${demo.virtual.threads}")
private int numberOfThreads = 1;
@Value("${demo.queue.name}")
private String queueName;
private final IQueue<Event> queue;
private final DemoService demoService;
private final FeatureManager manager;
public static final Feature CONSUMER_ENABLED = new NamedFeature("CONSUMER_ENABLED");
public EventConsumer(@Qualifier("eventQueue") IQueue<Event> queue, DemoService demoService,
FeatureManager manager) {
this.queue = queue;
this.demoService = demoService;
this.manager = manager;
}
@PostConstruct
public void init() {
startConsuming();
}
public void startConsuming() {
for (var i = 0; i < numberOfThreads; i++) {
Thread.ofVirtual()
.name(queueName + "_" + "consumer-" + i)
.start(this::consumeMessages);
}
}
private void consumeMessages() {
while (manager.isActive(CONSUMER_ENABLED)) {
try {
Event event = queue.take(); // Will block until an event is available or interrupted
// Process the event
log.info("EventConsumer::: Processing {} ", event);
demoService.doWork(event);
} catch (InterruptedException e) {
// Handle InterruptedException as per your application's requirements
log.error("Encountered thread interruption: ", e);
Thread.currentThread().interrupt();
}
}
}
}Depending on the nature of the processing we need and the desired throughput, we can have a multi-threaded EventConsumer by specifying the desired number of virtual threads in the configuration file.
The important thing to note here is that because Hazecast Queue is like a distributed version of java.util.concurrent.BlockingQueue, we are assured that each item will be taken from the queue by a single consumer even if multiple instances are running and on different JVMs.
The actual "work" is delegated to a DemoService, which has single @Retryable method:
@Retryable(retryFor = Exception.class, maxAttempts = 2)
@SneakyThrows
// @Async: enable this if you want to delegate processing to a ThreadPoolTaskExecutor
public void doWork(Event event) {
// do the actual processing...
EventProcessedEntity processed = new EventProcessedEntity();
processed.setRequestId(event.getRequestId().toString());
processed.setStatus(event.getStatus().name());
processed.setDateSent(event.getDateSent());
processed.setDateProcessed(LocalDateTime.now());
processed.setProcessedBy(InetAddress.getLocalHost().getHostAddress() + ":" + webServerAppCtxt.getWebServer().getPort());
eventProcessedRepository.save(processed);
}
@Recover
void recover(Exception e, Event event) {
log.error("Error processing {} ", event, e);
var result = dlq.offer(event);
log.info("Adding {} in DQL result {}", event, result);
}If the method fails for a configurable number of retries, the @Recover annotated method is fired and the event is delegated to the DLQ. The demo does not include implementation for the manipulation of DLQ messages.
One more thing to add here is that we could possibly annotate this method with @Async and configure a ThreadPoolTaskExecutor(or a SimpleAsyncTaskExecutor for which Spring will soon add first-class configuration options for virtual threads - check here for more info). This way the consumption of messages would be less blocking if the processing task (i.e., the actual work) is more "heavy."
At this point and regarding error handling, we need to mention that Hazecast also supports Transactions. For more information about this capability, you may check the official documentation here. You could easily modify the Consumer's code in order to try a transactional approach instead of the existing error handling.
Testing and Monitoring
As mentioned above, once executed our docker-compose file will start the PostgreSQL database (with the necessary tables in place) and the Hazelcast Management console which you can access at http://localhost:8080.
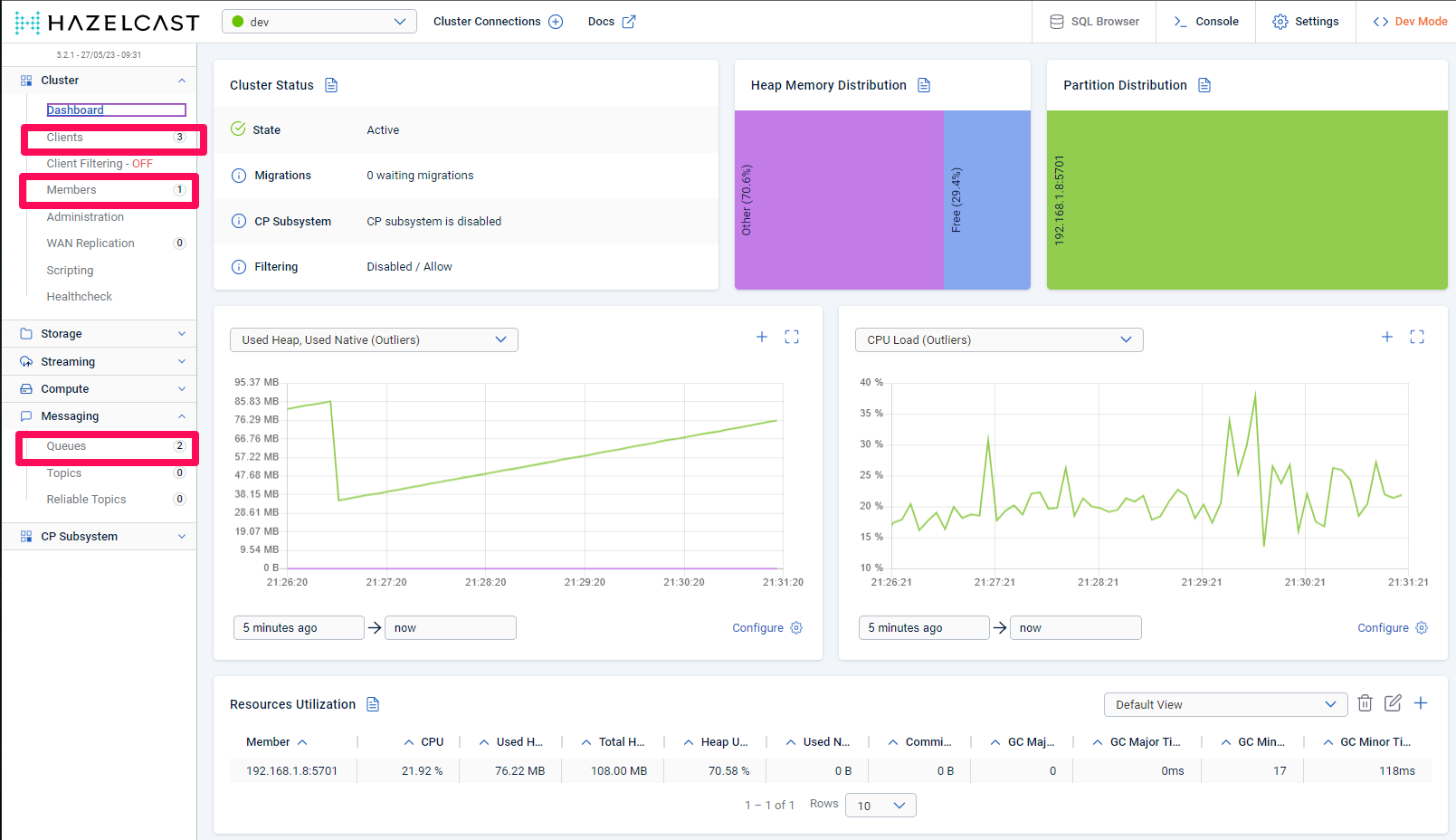
Hazelcast Management Console
You can start multiple instances of Producers and Consumers and monitor them via the console. At the same time, you may start producing some traffic and confirm the load-balancing and parallelization achieved with our competing consumers.
Moreover, the Consumer application includes the Chaos Monkey dependency as well, which you can use to introduce various exceptions, delays, restarts, etc., and observe the system's behavior.
Wrap Up
To wrap it up, competing consumers with Hazelcast and Spring Boot is like a friendly race among hungry microservices for delicious messages. It's a recipe for efficient and scalable message processing, so let the testing begin, and may the fastest consumer prevail!
Opinions expressed by DZone contributors are their own.
Comments