Continuous Delivery Anti-Patterns
DevOps one-stop shop solutions can slow you down over time. Tools that equal a stage to an environment deployment miss out on the real power of deployment pipelines.
Join the DZone community and get the full member experience.
Join For FreeAn anti-pattern is typically a behavior that hinders or at least negatively influences a target objective. There are many anti-patterns for Continuous Delivery documented by people like Jez Humble, Steve Smith, and ourselves.
Some CD anti-patterns arise not from an existing behavior, but by trying to actually implement the practices without understanding their goals first. That is especially frequent when adopting integrated tools that are supposed to support a full set of CD practices out-of-the-box. The idea that you can “just plug in a deployment pipeline” and get the bene ts of CD is a common anti-pattern.
In the following sections, we will look into some of these “unintentional” and often hard-to-notice anti-patterns that might emerge when adopting a “DevOps one-stop shop” solution.
Anti-Pattern #1: Avoiding Tool Integration Like the Plague
There is a prevalent notion, especially in larger enterprises, that integrating disparate tools is extremely expensive. That you’ll be locked for eternity maintaining glue code with high technical debt. That might have been true in the 2000s, but surely not today.
As long as you are integrating tools with clear and standard APIs, the orchestration code can be minimal and understandable by anyone familiar with API development (which all developers should be in 2017!).
Tooling integration cost is not zero, but it’s negligible when compared to the potential cost of not integrating. One-stop solutions might embed erroneous concepts. Any tool might. The problem is that the former will propagate them across the entire lifecycle.

Instead, single-purpose, focused tools with a well-de ned API help reduce the blast radius of bad practices. And you can swap them easily when they don’t match your requirements anymore. A flexible toolchain standardizes practices, not tools. It supports certain capabilities, which are easy to locate and expand on, replacing particular components (tools) when required.
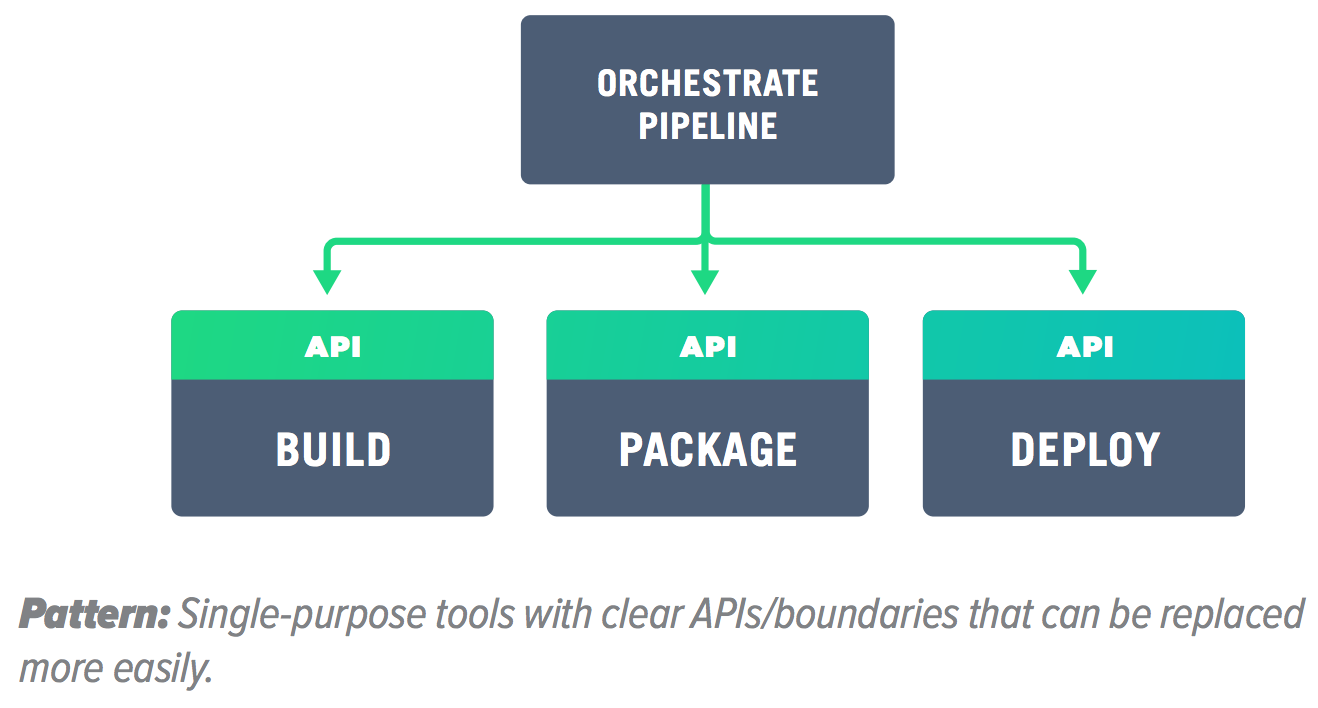
Another gain with individual tools: you can actually expect an answer from the vendor when you ask for a feature since they have a reduced feature set and faster change cycles. A vendor of a one-stop solution has a lot more requests in its backlog. Chances are, if you’re not a major client, your requests will get buried for months or even years.
Anti-Pattern #2: Error Handling and Logging Behind Closed Doors
Another hidden time-consuming anti-pattern in one-stop solutions derives from generic error messages or inaccessible logging. This tends to be especially painful with SaaS solutions.
Unfortunately, our industry is still plagued with the “abstraction everywhere bias”: a tendency to favor generic error messages (“VM could not be started” or “Deployment failed”) instead of spelling out what was the expected input or output and the difference to the actual result. Now add to the mix inaccessible logs for those failed operations, a common situation in one-stop solutions that provide only UI access to certain features or only let you access logs via queries.
The problem is these tools assume they have all the use cases and all the failure scenarios covered. That is untrue for any tool, or any software in fact. We will always need access to information to troubleshoot issues. The more information we have, the more likely we can correlate events and nd the causes.
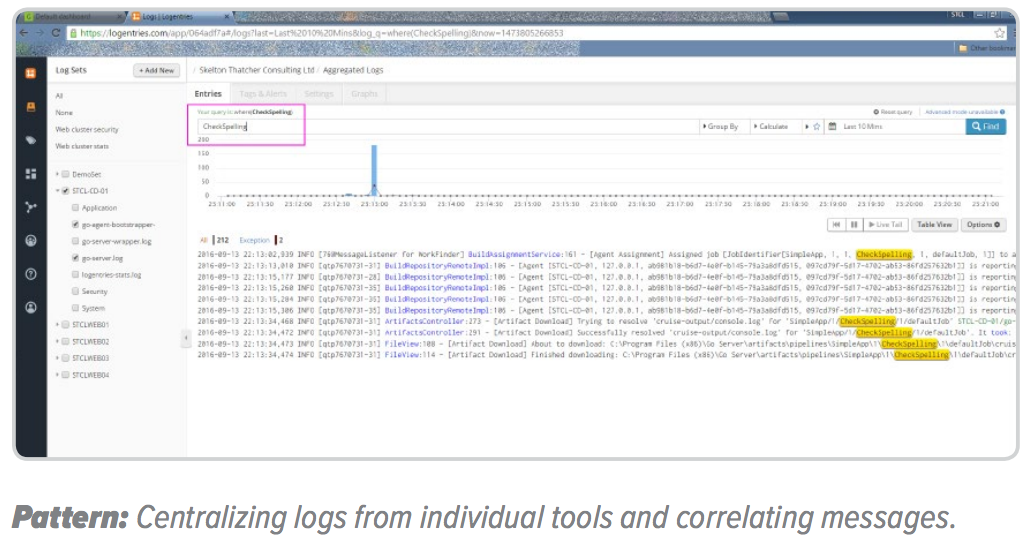
Think of all the time spent deciphering error messages, trying to guess what went wrong, or waiting for a vendor’s support to get back to you (if you hit the jackpot with a technical issue deep in the tool’s gut, good luck waiting for the support-to-engineering return trip time). That time alone is an order of magnitude higher than any individual tool integration time you’d have spent.
Anti-Pattern #3: Environment-Driven Pipelines
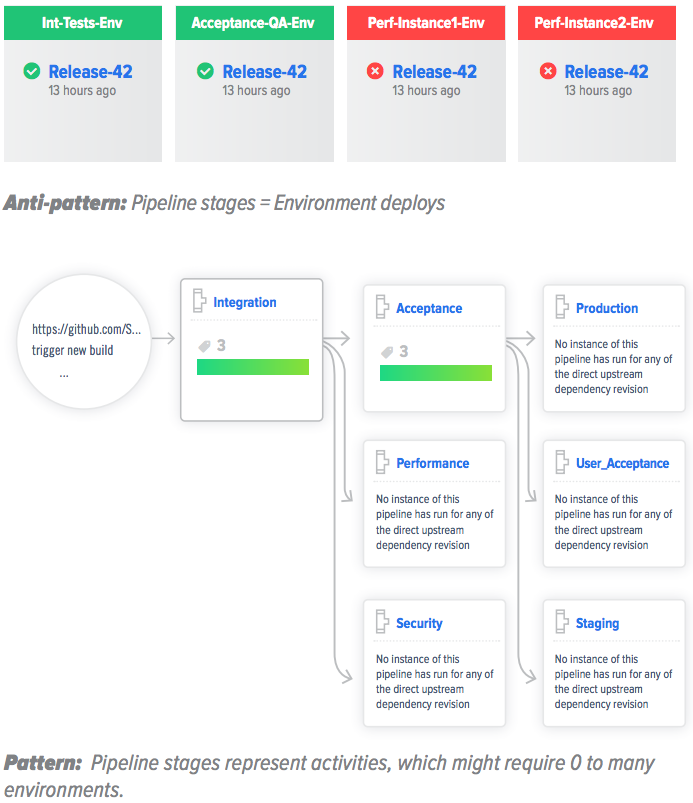
This one is pretty self-explanatory. Tools that assume your pipeline is nothing but a sequence of environments where you deploy your system and run some tests.
A pipeline stage represents an activity in the delivery chain. It might require:
- One environment: Typical for acceptance tests.
- Zero environments: Typical for manual checks/analysis or approval requests.
- Multiple environments: Typical for performance tests.
Thus pipeline stages should not be tightly coupled to environments. Assuming only the first option above leads to pipelines that contemplate only automatable activities, hiding other (often non-technical) activities that are part of delivery as well. In turn, this leads to lack of visibility on (real) bottlenecks and local optimization (technical steps) instead of global (cycle time).
Anti-Pattern #4: Flexing Is for Fitness, Not for Principles
Adopting core Continuous Delivery principles is hard and often requires mental and cultural shifts. Without them, the underlying practices become ceremonies, instead of actual improvements in delivery. Flexibility is fine for the gym, but not for core principles required for a (often radical) new way of working.
If the tools supporting the practices do not align with the principles, they end up unintentionally undermining the whole endeavor. In contrast, working with a set of single-purpose tools helps identify and address erroneous assumptions by any one tool.
Below are a couple of examples of misalignment between implementation and principles that we’ve seen in some out-of-the-box integrated tools.
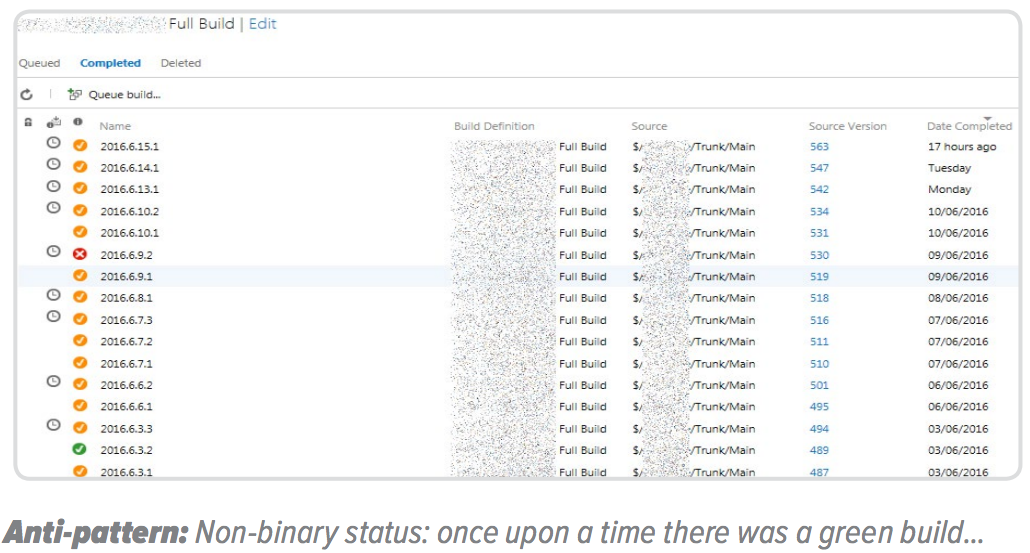
Status: ???
A pipeline status should be binary. Red or green. Not orange. Not gray. Not blue. Recurring ambiguities in status inevitably lead to disengagement by development teams. This is the
CD equivalent to warnings at compilation time. If the first warnings are ignored by developer A, then developer B and developer C will ignore them, as well. Soon, everyone just assumes having 372 warnings is OK.
Having an uncontested pipeline status is a prerequisite to the Continuous Delivery principle of “stopping the line” when a pipeline fails (then either x it quickly or revert the changes that broke it). Interestingly, this is also a prerequisite to getting rid of those nasty compilation warnings (try making the pipeline go red if there are compilation warnings).
Terminology Fail
Another plague in our industry is the proliferation of terminology. We have enough confusion as it is and quite frankly one-stop tool vendors are not helping. They, above all, should strive to align on common terminology, as they are informing their clients on the entire lifecycle. So, it better be correct. This is clearly complicated as those vendors have many different teams working on the integrated tools. But it is needed.
One puzzling example we have come across of terminology failures is calling a pipeline trigger from a successful build a “continuous deployment.”
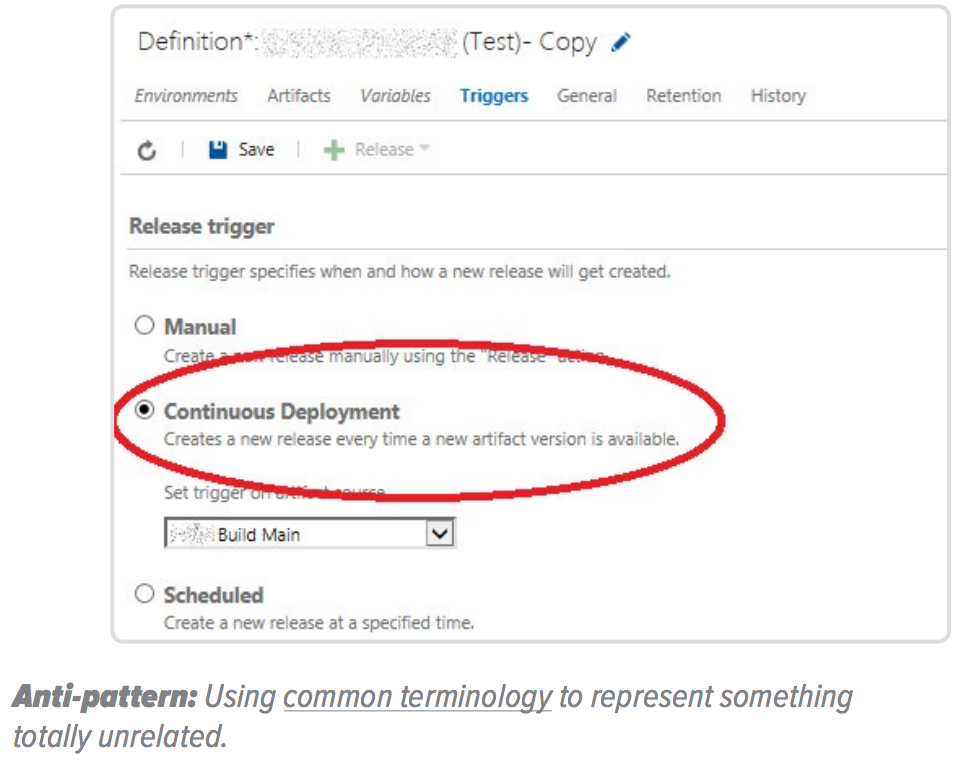
Another example are “release definitions” instead of “pipeline definitions” (the image above is a release definition configuration). Legacy terminology leads to legacy behaviors, thinking of releases and work batches instead of pipelines and frequent delivery of small, low-risk changes in production.
This might seem like just nitpicking, but the accumulation of all these misunderstandings leads to unknowingly misinformed organizations and teams.
Summary
We want to go faster and have faster-delivering products. To do so we should also be able to go faster and faster in adapting our pipeline to support that goal.
But one-stop tooling solutions often bring along several anti- patterns that slow us down or misguide us, as explored in this article.
We’re not advocating for always integrating your own toolchains. Your organization might have good reasons to go for a one-stop solution in terms of DevOps and Continuous Delivery. We just recommend being extremely conscious of the trade-off you’re making. And we hope the anti-patterns highlighted in this article help guide some of that thinking process.
More DevOps Goodness
If you'd like to see other articles in this guide, be sure to check out:
Published at DZone with permission of Manuel Pais. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments