CQRS Is an Anti-Pattern for DDD
CQRS solves a very particular set of problems, like executing queries in event-stores or building web applications with extremely high scalability requirements.
Join the DZone community and get the full member experience.
Join For FreeAre you interested in new ways to build better software systems? If you work with distributed systems or build any kind of web application, you most likely have heard of the new trends like using Domain-Driven Design with Event-Sourcing and Command Query Responsibility Segregation (CQRS). Well, they are not exactly brand new. However, they are now becoming increasingly popular.
Let’s say you have the task to build a new application and have the freedom to do everything the way you want. Your new application should manage the relationship between external companies (customers) and the people working in your marketing department (salesperson). Every salesperson can work with multiple customers and every customer can have multiple salespeople assigned to it. While the application is not exactly highly complex from a business point of view (it is just an N:M relationship between customers and salespeople) you decide to use it as a proof of concept for CQRS.
You separate your implementation in query and command part, build your read and write models, find a way to keep them synchronized using some sort of event-handlers. You are feeling really happy with your project. Then, the users start testing your application and complain. Those damn users.
Their main complaint is that they add a salesperson to a customer, but they don`t see the change taking effect. The list of salespeople does not contain the latest change. And for you everything is clear. It takes some time for the read and writes model to be synchronized, so the user has to refresh the page. However, your users are less than happy with this behavior and want you to improve it. The users want to see the change immediately. You could try to explain CQRS or eventual consistency to them. Even if they do listen, they will ask you, why is it so hard to add an entry to a list? I was in this position. I asked myself this too.
Why is it so hard to add a simple entry to some list and return the new list as a response?
In the following, I will explore this question to show you the pitfalls of using CQRS to “improve” the design of your application.
Command Query Separation
I believe that to understand some concepts, you should know how it originated and what problems it was meant to solve. Let`s go back to the 90s.
Command Query Separation (CQS) was first introduced by Bertrand Meyer in his book Object-Oriented Software Construction in 1994. Martin Fowler has also written about the topic on his blog.
The idea is to divide the methods of an object into two categories:
- Queries: return some result, but do not change the state of the object, a.k.a. side-effect free functions
- Commands: change/mutate the state of the object, but do not return a result, e.g. void functions
This is a sound principle. If your function sounds like a query, e.g. calculateMonthlyCost(), it would be unexpected and very frustrating to find out that it also publishes the value as a report in some database. In practice, such behavior leads to bugs, which are extremely hard to pinpoint.
But what about the void return value of functions? Isn`t it a bad practice to return void instead of some concrete type? Let`s take the following example:
Without CQS:
Certificate cert = certificateAuthority.generateCert(key);
With CQS:
xxxxxxxxxx
certificateAuthority.generateCert(key);
Certificate cert = certificateAuthority.getCertificate();
At first glance, the CQS option takes more lines of code and feels unnecessary clumsy. However, proponents of CQS would rightly point, that the first example often returns null or error codes, when something goes wrong, e.g. the key is not valid. This does not make the API of an object easier to understand. Using void functions, you are not tempted to do this. Instead, you must throw an exception, which is the better practice compared to error codes as the return value.
You can write much more about CQS, but this is not the focus of the article. The example should be enough to get the idea. I think that most systems would profit from using the CQS pattern. However, like every other pattern you should not use it fanatically. As Martin Fowler points in his summary of CQS, the pop() of a stack is a good example of a useful function, which ignores the separation.
Command Query Responsibility Segregation
Command Query Separation has the segregation of commands and queries at the method/function level of a single object. Fast forward to 2010 and Greg Young introduces Command Query Responsibility Segregation. CQRS takes this approach one level higher and separates the whole domain model in command and query objects. This seemingly small difference has a profound impact on architecture. Therefore, most people consider CQS and CQRS to be completely different patterns
Taking our example with the application for a marketing department, you would normally build something like this interface.
xxxxxxxxxx
interface Marketing {
List<Salesperson> assignSalesperson(Company customer, Salesperson salesperson);
List<Salesperson> getResponsibleSalespeople(Company customer);
List<Company> getAssignedCompanies(Salesperson salesperson);
}
Applying CQRS to this interface would lead to splitting it into a read part and a write part.
xxxxxxxxxx
interface MarketingRead {
List<Salesperson> getResponsibleSalespeople(Company customer);
List<Company> getAssignedCompanies(Salesperson salesperson);
}
xxxxxxxxxx
interface MarketingWrite {
void assignSalesperson(Company customer, Salesperson salesperson);
}
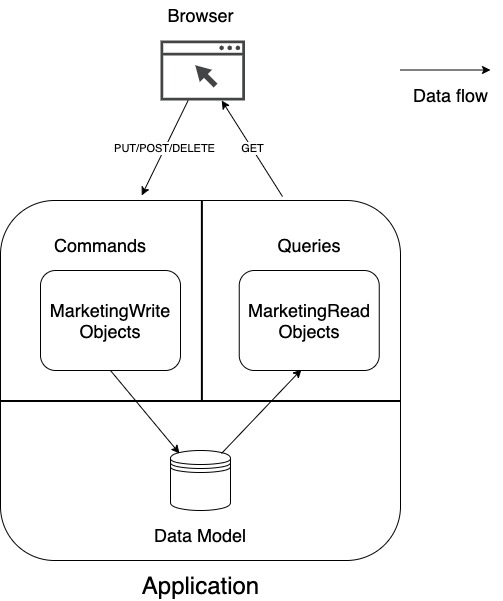
And this is the definition of CQRS! It is this simple. You split your domain model, in object-oriented programming your objects, in a read model and a write model.
But people do not stop here. You can go even further and take this segregation to the data model. This leads us to the two main variants of CQRS – using one data model or building separate read and write data models.
CQRS With One Data Model
Using only one data model is still CQRS. The pattern refers only to the segregation of the domain model, e.g. your objects. When you read about this “classical” version of CQRS, people point out, that you enjoy the same benefits as CQS. Calling functions, which either query the state or modify it, reduces the chance of unwanted side effects. Furthermore, dividing the whole domain in read and write, makes it easier to understand the domain and in turn to maintain it. This should be particularly helpful with complex domain models. If CQS is a good thing, segregating the whole architecture should be even better, right?
This is where I do not agree with most CQRS practitioners. It does make a substantial difference on which level you segregate. Borrowing an example from the animal kingdom, let`s consider the difference between a mouse and an elephant. Both animals consist of the same cells. However, the size of the animal has a considerable influence on its metabolic processes and how those cells build a more complex system (see How to Make an Elephant Explode). If we go even further and compare bacteria to an elephant, you could even argue that these organisms live in different physical dimensions, governed by different physical laws.
Going back to software development, it does make a difference, whether you separate the functions of an object or the whole domain in two sets of objects. In the former example, the object remains a coherent unit. This unit is solely responsible for its internal implementation and state. You should be able to change some implementation detail without affecting the clients of this object. With two sets of objects, you distribute the internal logic across two components.
CQRS conflicts with one of the main principles for writing software – low coupling. “If changing one module in a program requires changing another module, then coupling exists”. Almost every pattern in software is referring to this problem directly or indirectly. How do you divide your system into components, in such a way, that you can change one component with minimum impact on the other components? Or what is the right responsibility in the Single Responsibility Principle?
It is really hard for me to accept, that you can evolve the read and write part of the system separately. Reading and writing are not the right responsibilities for building domain models, because business people do not think in terms of reading and writing. The real value lies in process flows. Only the most minor changes in a process flow would affect only the read or only the write part of the domain model.
Maybe you are thinking of my example with the marketing application? It does sound a bit like a CRUD application, right? Not the best candidate for CQRS. Well, there were indeed more complex requirements in my original project. For example, when you assign a salesperson to a customer, the system must decide, whether he/she is the primary salesperson or a supporting salesperson. The first assignee becomes the primary salesperson automatically, all next assignees will have the supporting role. You can also change the primary person manually at a later point.
You could take the business requirements from your project as an example. The important aspect here is, that the command must read the state of the customer to make a business decision. Well, the query must build more or less the same state. You can either have the command call the query or implement this function twice. I find both options disappointing.
Using CQRS for complex domain models, as you read in many online blogs, ignores the fact, that we already have a good solution for complex domain models. You can use the ideas from Domain-Driven Design like Aggregate and Bounded Context. I find it very strange, that CQRS is so closely connected to DDD, but tries to offer a new solution. If your Bounded Context is so complex, that you need the segregation in commands and queries, I would first question how this context could become so complex.
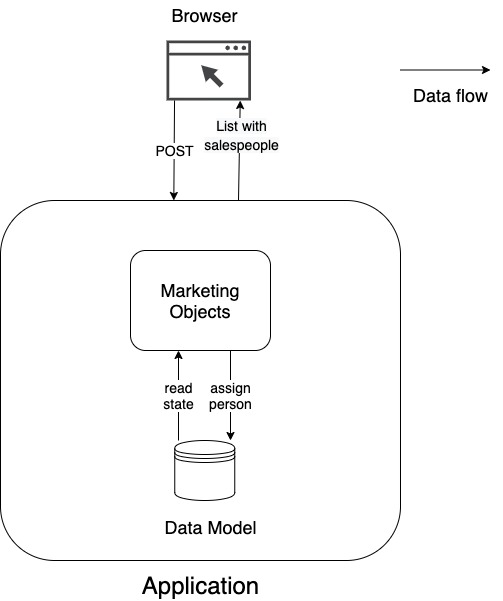
In case you have forgotten my original question – why is adding an entry to a list and returning the new state so complex? When using CQRS with one model, this is not complex. You just call two functions instead of one. You fire a command to modify the state and then query the new state. Because you have only one model, you can be sure that it has already been updated, when you query the new state.
However, CQRS with one data model seems to be the exception. It is much more “interesting” to use separate read and write models.
CQRS With Read and Write Models
Even Greg Young has said that the real value of CQRS lies in using separate read and write models. The command part operates only on the write model. Updates of the write model trigger events, which in turn update the read model. The query part of the system can see only the read model.
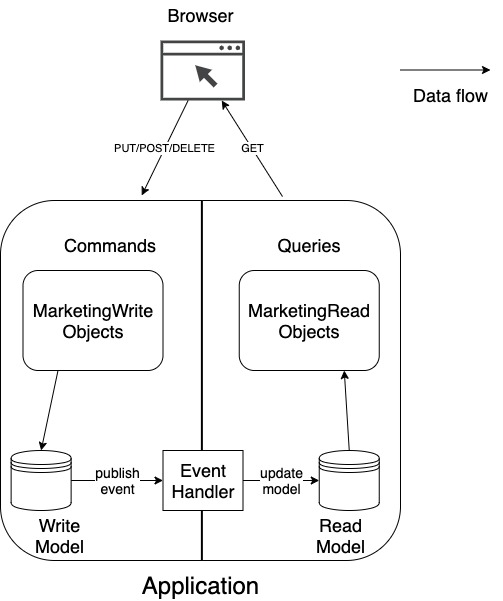
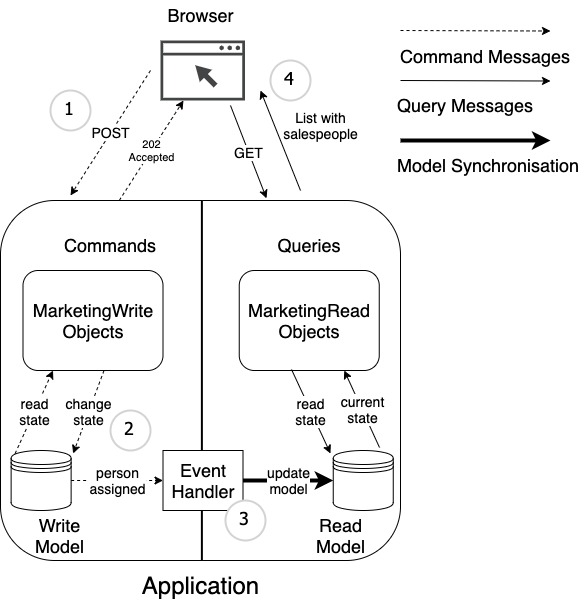
Figure 3 shows an example of how you could implement CQRS with two data models. You could argue with some of the arrows and propose different solutions. However, you can only persist state changes in the write model (step ① and ②) and present the current state from the read model (step ④). And you cannot guarantee when to step ③, the synchronization will be executed.
- WebSockets: allow duplex communication. The server can notify the client after all events have been processed. Then the client can query the new state, or the server can push it directly to the client. Both client and server must support WebSockets though.
- Client accepts HTTP requests: If the client can accept HTTP requests, it could send a callback endpoint with the original request. After the server is ready, it would notify the client using this endpoint. The client functions as both an HTTP client and an HTTP server, so it must implement both roles.
- Client polling: If the client cannot implement WebSockets or accept HTTP requests, it can always poll the server for the new state. It is not an elegant solution and it has drawbacks too. How do you notify the client of an exception? However, it is very lightweight and straightforward.
- Server polling/callback: If the client does not want to implement a callback mechanism or polling, the server would have to implement it on its side. After the command is triggered, the server would have to wait for the read model to be updated and deliver the new state as a response. The additional complexity is on the server`s side.
As you see it is possible to solve the problem, however, either the client or the server (or both) have to deal with eventual consistency. This additional complexity is part of the deal. You cannot use just the standard request-response mechanism of HTTP.
Compare the messages in Figure 3 to those in Figure 4, a more conservative implementation with only one data model. Why does Figure 4 have fewer arrows? Because once I write in my single model, I can be sure, that the operation has ended successfully. Then I can return the new state without additional synchronization.
When you want to deliver events to an external system (and your read model is an external system from the write model`s point of view), you have to deal with all the problems of unreliable communication in distributed systems. I strongly advise you against trying to implement this event handling on your own. I speak from experience. This challenge is a major driver of complexity. Sadly, it is rarely discussed in CQRS training, but just briefly sketched on some slide.
So far, I am proposing the thesis, that CQRS with one data model does nothing but increase coupling. And CQRS with read and write models is ridiculously complicated because you are building your application as a small distributed system. However, success stories are using CQRS. Most notably Twitter and Facebook rely on this pattern. Could it be, that I have used it the wrong way?
We have to go back in time again and talk about the origins of CQRS one more time.
The Dark Ages
There were some dark years in enterprise software development. Especially in the early 2000s digitalization has become so important, that almost every big company was building its software – some kind of enterprise software. At this time, the most popular architecture was a monolithic three-layer architecture – with presentation, logic, and data layers. Even big complex projects had a single database with a single database schema. Additionally, these applications were often built as CRUD services.
Their interfaces were mostly accepting and retrieving DTOs. You get the customer DTO, modify some flags, and push it back into the system. The application then had to check how the flags have changed, to “reverse engineer” the meaning of your changes. And because there was a single customer table in the database, this table had around 400 columns. It had to fulfill every possible requirement, that has something to do with a customer.
The Enlightenment
In the meantime, a counter-movement was starting to gain attention. Domain-Driven Design was pushing many new ideas. One of them was, that the API should not be based on CRUD operations, but on task flows. A task flow being the digital representation of the real business processes. Some people, like Greg Young, were even proposing to go further and change the way, how we persist data. Instead of saving the current state and overwriting it with every change, one should save the changes as events instead. If you replay all events in the system, you get the current state. This method is known as event-sourcing. Additionally, you can do things, which were never possible with the CRUD applications. Like rebuilding the state at any point in time and thus analyzing, how the data has evolved. This was revolutionary for people, who wanted to analyze customer behavior without knowing what they were looking for in advance. The possible use-cases are endless.
CQRS was a natural fit for event-sourcing because it solved one important problem with persisting only in the events. You cannot execute queries on the event-store in a reasonable time. You would have to rebuild the whole state from all the events for every query.
You save the events in some event-store – the write model. With these events, you can build a representation of the current state of the system – the read model. This way you build the read model once and then just update some small part of it when a new event is saved. The queries run only on the read model. This opens other new possibilities too. You can optimize the write model for write operations and the read model for reading operations. Greg Young describes the following advantages:
- Consistency
- Command – can be implemented with strong consistency in the write model
- Query – can be eventually consistent in the read model
- Data storage
- Command – storage optimized for writing, e.g. normalized form
- Query – storage optimized for reading, e.g. reduce joins with denormalized form
- Scalability
- Command – mostly low scalability requirements, because writes are few compared to reads
- Query – most of the operations in a typical system are reading data
If you read the original white paper about CQRS and event-sourcing by Greg Young, you see that CQRS was part of a bigger change in the way we think about building applications. Saying that CQRS improves the design on its own, ignores a large part of the story. The main difference between the old CRUD-world and this new approach is that the API is based on task flows. The API tells you something about the business purpose of the call. Furthermore, event-sourcing allows you to implement use-cases, which are impossible when overwriting the state.
Now, look at the advantages of CQRS one more time – improved consistency, data storage, and scalability. There is nothing here about better design, which is easier to maintain. All of these are performance optimizations. Don`t get me wrong. These advantages are correct. It is just that they are relevant if you are building a system, which should scale extremely well.
Why Is CQRS so Complex?
Now I can finally answer the original question. Why is it so hard to add an entry to the list and return the new list as a response?
The correct answer is – it depends on the context.
First let’s take the most common context, where the data fits on one machine and the users are within some reasonable size, for example, hundreds of users. This was the context of my project, where we used CQRS. In our case, CQRS was complex, because our system was optimized for the wrong use-cases. We have prioritized availability where the users wanted to receive consistency. We have built an overengineered system, without needing this scalability.
From a technical point of view, one model cannot achieve the same performance as specialized read and write models. However, for our use-cases (the marketing example at the beginning of this post) one model would have been good enough. The time we invested in building our scalable system, could have been better invested in implementing more use-cases for the users. Our users were right to complain, that they don`t have to put up with eventual consistency.
In another context, let’s take Facebook or Twitter, which has to support millions of users simultaneously, you have to optimize for scalability and availability. Nobody cares if you see 4 likes instead of 5 likes for several minutes, as long as you can use the system and stay engaged. CQRS is not hard in this context, because the pain of synchronizing multiple models is less than the pain of building one model, which does it all. Reducing the scalability challenges offsets the added complexity for synchronizing the two models.
Following I will describe many bad and some good arguments (in my opinion) for using CQRS. I have heard them during discussions with colleagues.
Bad Arguments for CQRS
- I want to make it easier to change my application later
- CQRS introduces complexity, which makes changing the system more difficult. This makes sense only if you have some ridiculous performance problems, which are solved better with two data models, instead of one. Most applications do not fall into this category.
- My application must scale well
- It could be, that CQRS is a match for you. However, have you tested a simpler approach first? Do you have some numbers, which prove, that a traditional relational database will not be sufficient? You will be surprised how well an RDBS can scale, without your users noticing any delay.
- Eventual consistency is a problem, which you cannot avoid. Furthermore, whether eventual consistency is a deal-breaker, is decided by the business people, not by you.
- I`m using NoSQL and I must do some complex queries. So, I`ll use my NoSQL database as a write model and Elasticsearch as read model.
- Maybe, you should not have used a NoSQL solution in the first place? As said, you will be surprised how much an RDBS can handle. Instead of using CQRS, consider moving to a single relational data model.
- You can use CQRS and event-sourcing independently
- “Your scientists were so preoccupied with whether or not they could, they didn’t stop to think if they should.” Most systems, which do not use event-sourcing, don`t have the scalability requirements to justify CQRS.
- I have a microservices system and save the data from other microservices in a read model, while saving my data in a write model
- Receiving data from another system as context mapping has nothing to do with two data models. You can save it in one data model as well and use it as a read table for your business decisions. Even Greg Young has said, that CQRS and event-sourcing is not a global decision for all microservices. Every bounded context has different requirements.
- I make asynchronous calls to external systems, so this maps well to the asynchronous events in CQRS
- The asynchronous calls can just as easily be handled with one data model. Having two data models makes the asynchronous nature of your application even more complex.
- I use DDD with commands and events, so I can easily implement CQRS
- The commands/events from DDD are only a very small part of CQRS. It is a good start, but they do not solve important problems like synchronization.
Good Arguments for CQRS
- Event-sourcing
- Try with one data model first. Write the events (the write part) and their projections (the read part) in the same model. If one model does not work for you, then move on to two models. As said, you will be surprised how far you can go with a simple RDBS. There is a reason, they are still around.
- Scalability Requirements
- You must prove that you have a performance problem first. Have you tried using one model? Do you have numbers, which point to performance problems? Or are you building a Twitter architecture for your small proof of concept application?
Conclusion
Somehow CQRS has achieved a status, where it is considered a normal part of Domain-Driven Design. Most people, who apply this pattern, hope to improve the design of their system and make it easier to maintain. This is a huge misunderstanding about the advantages and disadvantages of this architecture. CQRS is to be used with extreme caution because there are very few use-cases, where it solves more problems than it creates.
Published at DZone with permission of Hristiyan Pehlivanov. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments