Creating an SRE Practice: Why and How
Explore who SREs are, what they do, key philosophies shared by successful SRE teams, and how to start migrating your operations teams to the SRE model.
Join the DZone community and get the full member experience.
Join For FreeThis is an article from DZone's 2022 Performance and Site Reliability Trend Report.
For more:
Read the Report
Site reliability engineering (SRE) is the state of the art for ensuring services are reliable and perform well. SRE practices power some of the most successful websites in the world. In this article, I'll discuss who site reliability engineers (SREs) are, what they do, key philosophies shared by successful SRE teams, and how to start migrating your operations teams to the SRE model.
Who Are SREs?
SREs operate some of the busiest and most complex systems in the world. There are many definitions for an SRE, but a good working definition is a superhuman-merged engineer who is a skilled software engineer and a skilled operations engineer. Each of these roles alone are difficult to hire, train, and retain — and finding people who are good enough at both roles to excel as SREs is even harder. In addition to engineering responsibilities, SREs also require a high level of trust, a keen eye for software quality, the ability to handle pressure, and a little bit of thrill-seeking (in order to handle being on call, of course).
The Variance in SREs
There are many different job descriptions that are used when hiring SREs. The prototypical example of SRE hiring is Google, who has SRE roles in two different job families: operations-focused SREs and "software engineer" SREs. The interview process and career mobility for these two roles is very different despite both roles having the SRE title and similar responsibilities on the job.
In reality, most people are not equally skilled at operations work and software engineering work. Acknowledging that different people have different interests within the job family is likely the best way to build a happy team. Offering a mix of roles and job descriptions is a good idea to attract a diverse mix of SRE talent to your team.
What Do SREs Do?
As seen in Figure 1, the SRE's work consists of five tasks, often done cyclically, but also in parallel for several component services.
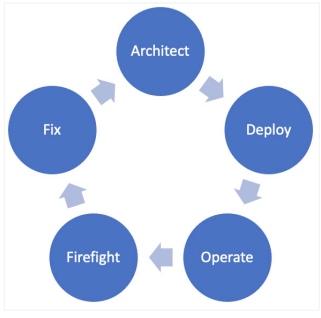
Figure 1: SRE responsibility cycle
Depending on the size and maturity of the company, the roles of SRE vary, but at most companies, they are responsible for these elements: architecture, deployment, operations, firefighting, and fixing.
Architect Services
SREs understand how services actually operate in production, so they are responsible for helping design and architect scalable and reliable services. These decisions are generally sorted into design-related and capacity-related decisions.
Design Considerations
This aspect focuses on reviewing the design of new services and involves answering questions like:
- Is a new service written in a way that works with our other services?
- Is it scalable?
- Can it run in multiple environments at the same time?
- How does it store data/state, and how is that synchronized across other environments/regions?
- What are its dependencies, and what services depend on it?
- How will we monitor and observe what this service does and how it performs?
Capacity Considerations
In addition to the overall architecture, SREs are tasked with figuring out cost and capacity requirements. To determine these requirements, questions like these are asked:
- Can this service handle our current volume of users?
- What about 10x more users? 100x more users?
- How much is this going to cost us per request handled?
- Is there a way that we can deploy this service more densely?
- What resource is bottlenecking this service once deployed?
Operate Services
Once the service has been designed, it must be deployed to production, and changes must be reviewed to ensure that those changes meet architecture goals and service-level objectives.
Deploy Software
This part of the job is less important in larger organizations that have adopted a mature CI/CD practice, but many organizations are not yet there. SREs in these organizations are often responsible for the actual process of getting binaries into production, performing a canary deployment or A/B test, routing traffic appropriately, warming up caches, etc. At organizations without CI/ CD, SREs will generally also write scripting or other automation to assist in this deployment process.
Review Code
SREs are often involved in the code review process for performance-critical sections of production applications as well as for writing code to help automate parts of their role to remove toil (more on toil below). This code must be reviewed by other SREs before it is adopted across the team. Additionally, when troubleshooting an on-call issue, a good SRE can identify faulty application code as part of the escalation flow or even fix it themselves.
Firefight
While not glamorous, firefighting is a signature part of the role of an SRE. SREs are an early escalation target when issues are identified by an observability or monitoring system, and SREs are generally responsible for answering calls about service issues 24/7. Answering one of these calls is a combination of thrilling and terrifying: thrilling because your adrenaline starts to kick in and you are "saving the day" — terrifying because every second that the problem isn't fixed, your customers are unhappy. SREs answering on-call pages must identify the problem, find the problem in a very complicated system, and then fix the problem either on their own or by engaging a software engineer.

Figure 2: The on-call workflow
For each on-call incident, SREs must identify that an issue exists using metrics, find the service causing the issue using traces, then identify the cause of the issue using logs.
Fix, Debrief, and Evaluate Incidents
As the on-call incidents described above are stressful, SREs have a strong interest in making sure that incidents do not repeat. This is done through post-incident reviews (sometimes called "postmortems"). During these sessions, all stakeholders for the service meet and figure out what went wrong, why the service failed, and how to make sure that the exact failure never happens again.
Not listed above, but sometimes an SRE's responsibility is building and maintaining platforms and tooling for developers. These include source code repositories, CI/CD systems, code review platforms, and other developer productivity systems. In smaller organizations, it is more likely that SREs will build and maintain these systems, but as organizations grow, these tasks generally grow in scale to where it makes sense to have a separate (e.g., "developer productivity") team handle them.
SRE Philosophies
One of the most common questions asked is how SREs differ from other operations roles. This is best illustrated through SRE philosophies, the most prevalent of which are listed below. While any operations role will likely embrace at least some of these, only SREs embrace them all.
- "Just say no" to toil
- Toil is the enemy of SREs and is described as "tedious, repetitive tasks associated with running a production environment" by Google. You eliminate toil by automating processes so that manual work is eliminated.
- One philosophy around toil held by many SREs is to try to "automate yourself out of a job" (though there will always be new services to work on, so you never quite get there).
- Cattle, not pets
- In line with reducing toil and increasing automation, an important philosophy for SREs is to treat servers, environments, and other infrastructure as disposable. Small organizations tend to take the opposite approach — treating each element of the application as something precious, even naming it. This doesn't scale in the long run.
- A good SRE will work to have the application's deployment fully automated so that infrastructure and code are stored in the same repositories and deploy at the same time, meaning that if the entire existing infrastructure was blown away, the application could be brought back up easily.
- Uptime above all
- Customer-facing downtime is not acceptable. The storied "five nines" of uptime (less than six minutes down per year) should be a baseline expectation for SREs, not a maximum. Services must have redundancy, security, and other defenses so that customer requests are always handled.
- Errors will happen
- Error budgeting and the use of service-level indicators is the secret sauce behind delivering exceptional customer facing uptime. By accepting some unreliability in services and architecting their dependent services to work around this, customer experience can be maintained.
- Incidents must be responded to
- An incident happening once sometimes happens. The same incident happening twice is beyond the pale. A thorough, blameless post-incident review process is essential to the goal of steadily increasing reliability and performance over time.
How to Migrate an Ops Team to SRE
Moving from a traditional operations role to an SRE practice is challenging and often seems overwhelming. Small steps add up to big impact. Adopting SRE philosophies, advancing the skill set of your team, and acknowledging that mistakes will occur are three things that can be done to start this process.
Adopt SRE Philosophies
The most important first step is to adopt the SRE philosophies mentioned in the previous section. The one that will likely have the fastest payoff is to strive to eliminate toil. CI/CD can do this very well, so it is a good starting point. If you don't have a robust monitoring or observability system, that should also be a priority so that firefighting for your team is easier.
Start Small: Uplevel Expectations and Skills
You can't boil the ocean. Everyone will not magically become SREs overnight. What you can do is provide resources to your team (some are listed at the end of this article) and set clear expectations and a clear roadmap to how you will go from your current state to your desired state.
A good way to start this process is to consider migrating your legacy monitoring to observability. For most organizations, this involves instrumenting their applications to emit metrics, traces, and logs to a centralized system that can use AI to identify root causes and pinpoint issues faster. The recommended approach to instrument applications is using OpenTelemetry, a CNCFsupported open-source project that ensures you retain ownership of your data and that your team learns transferable skills.
Acknowledge There Will Be Mistakes
Downtime will likely increase as you start to adopt these processes, and that must be OK. Use of SRE principles described in this article will ultimately reduce downtime in the long run as more processes are automated and as people learn new skills. In addition to mistakes, accepting some amount of unreliability from each of your services is also critical to a healthy SRE practice in the long run. If the services are all built around this, and your observability is on-point, your application can remain running and serving customers without the unrealistic demands that come with 100 percent uptime for everything.
Conclusion
SRE, traditionally, merges application developers with operations engineers to create a hybrid superhuman role that can do anything. SREs are difficult to hire and retain, so it's important to embrace as much of the SRE philosophy as possible. By starting small with one app or part of your infrastructure, you can ease the pain associated with changing how you develop and deploy your application. The benefits gained by adopting these modern practices have real business value and will enable you to be successful for years to come.
Resources:
- Site Reliability Engineering, Google
- "How to Run a Blameless Postmortem," Atlassian
- Implementing Service Level Objectives, Alex Hidalgo
This is an article from DZone's 2022 Performance and Site Reliability Trend Report.
For more:
Read the Report
Opinions expressed by DZone contributors are their own.
Comments