Creating Your First GenAI RAG App: Sony TV Manual Example
For novices, this tutorial demonstrates how to chunk PDF manuals, embed them with OpenAI, retrieve relevant text via FAISS, and produce GPT-based answers using RAG.
Join the DZone community and get the full member experience.
Join For FreeIn the last few months, I’ve spoken with a lot of industry professionals like software engineers, consultants, senior managers, scrum masters, and even IT support staff about how they use generative AI (GenAI) and what they understand about Artificial Intelligence. Many of them believe that using "AI" means interacting with applications like ChatGPT and Claude or relying on their integrated applications like Microsoft Copilot. While these are excellent tools for your day-to-day activities, they don't necessarily teach you how to build a GenAI application from the ground up. Understanding these technicalities is crucial to brainstorming ideas and creating use cases to solve and automate your work.
There are thousands of tutorials on large language models (LLMs), RAG (retrieval-augmented generation), and embeddings; many still leave novice AI enthusiasts confused about the "why" behind each step.
This article is for those beginners who want a simple, step-by-step approach to building their own custom GenAI app. We’ll illustrate everything with an example that uses two Sony LED TV user manuals. By the end, you’ll understand:
- How to organize your data (why chunking is important).
- What embeddings are, and how to generate and store them.
- What RAG is, and how it makes your answers more factual.
- How to put it all together in a user-friendly way.
Why Build a GenAI Chatbot for Sony TV Manuals?
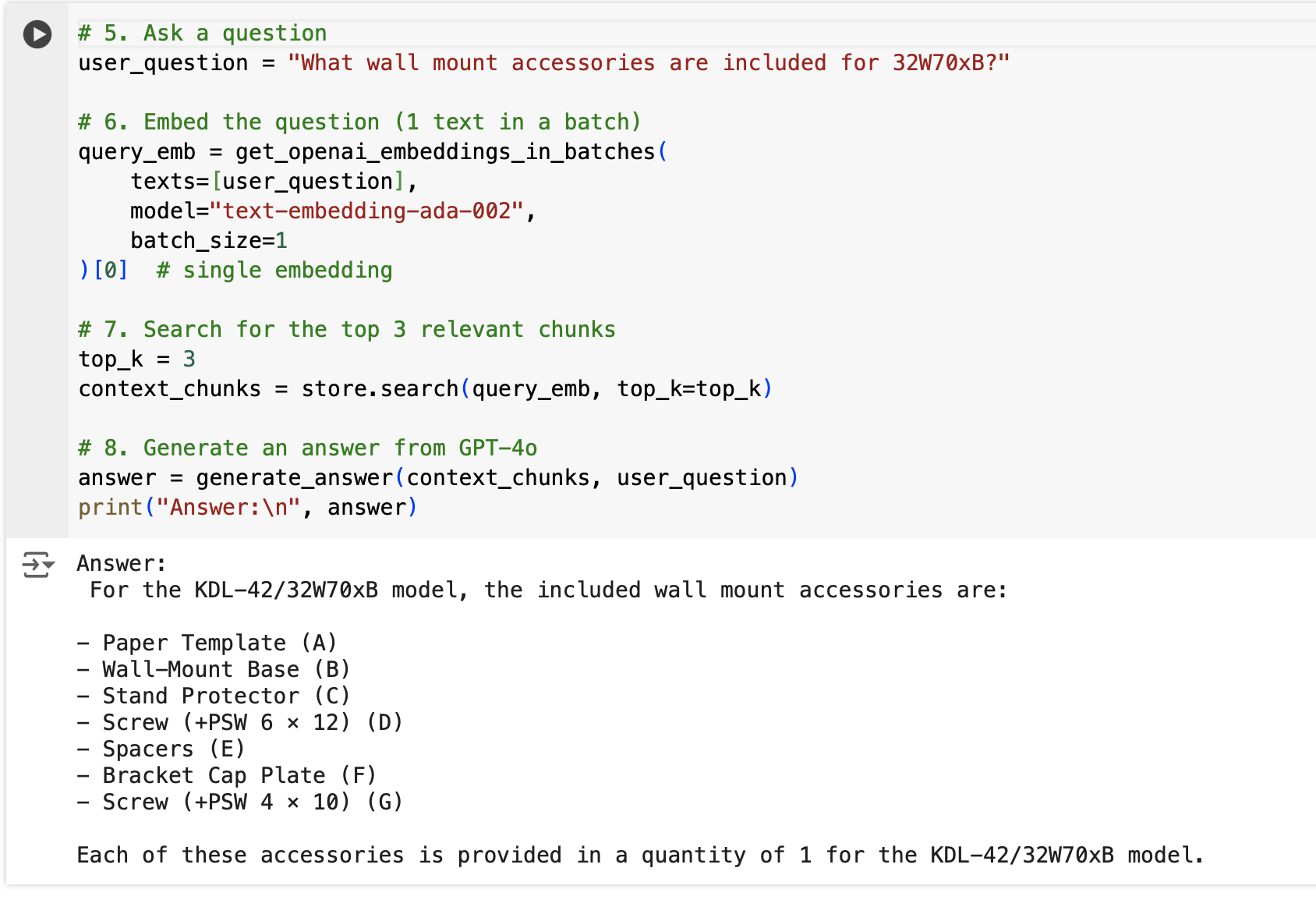
From an industry standpoint, imagine your company has a customer support division, and you have 100 different products with a 50-page user manual for each of them. Instead of reading through a 5000-page PDF, a user can ask, "What wall mount accessories are included for 32W70xB?" and get a targeted answer.
A GenAI application in this scenario can dramatically reduce customer support overhead and enable your representatives to correct answers quickly. Applications like ChatGPT or Claude can give you a generic answer, but this application will be specific to your product line. Whether you’re a support engineer, a tech writer, or a curious developer, this approach makes documentation more accessible, speeds up troubleshooting, and enhances customer satisfaction.
Conceptual Overview
1. Prompt Engineering in Plain English
Prompt engineering is the art of telling the model exactly what you want and how you want it. Think of it as crafting a "job description" for your AI assistant. The more context you provide (e.g., "Use these manual excerpts" or "Use this context"), the better and more on-topic the AI's responses will be.
2. RAG (Retrieval-Augmented Generation) and Why It Matters
Retrieval-augmented generation (RAG) ensures your answers remain grounded in facts from your data source (e.g., the Sony manuals). Without RAG, a model might "hallucinate" or produce outdated info. As we discussed before, you had 100 products and 50-page manuals for each; now, imagine you added 50 more products. Your manual size increased from 5000 pages to 7500. If you use RAG, it will dynamically fetch the relevant document chunks before generating the answer, making your application both flexible and accurate.
3. Vector Embeddings 101
Words can be turned into numerical vectors that capture semantic meaning. So if someone asks, "Which screws are not provided?" the model can find relevant text about "not supplied" even if the exact keywords aren’t used. This technique is crucial for building user-friendly, intuitive search and Q&A experiences.
Project Setup
Below is a step-by-step guide on building a GenAI application that can reference the contents of two Sony LED TV user manuals, all using Google Colab. We’ll cover why Google Colab is a great environment for rapid prototyping, how to set it up, where to download the PDF manuals, and how to generate embeddings and run queries using the OpenAI API and FAISS. This guide is specifically for novices who want to understand why each step matters rather than just copy-pasting code.
1. Why Google Colab?
Google Colab is a free, cloud-based Jupyter notebook environment that makes it easy to:
- Bootstrap your environment: Preconfigured with Python, so you don’t have to install Python locally.
- Install dependencies quickly: Use
!pip install ...commands to get the libraries you need. - Leverage GPU/TPU (optional): For larger models or heavy computations, you can select hardware accelerators.
- Share notebooks: You can easily share a single link with peers to demonstrate your GenAI setup.
In short, Colab handles the overhead so you can focus on writing and running your code.
2. What Are We Building?
We’re going to build a small question-answering (QA) system that uses RAG to answer queries based on the contents of two Sony LED TV manuals:
Here’s the basic workflow:
- Split and read PDFs into text chunks.
- Embed those chunks using OpenAI’s embeddings endpoint.
- Store embeddings in a FAISS vector index for semantic search.
- When a user asks a question:
- Convert the question into an embedding.
- Search FAISS for the most relevant chunks.
- Pass those chunks + the user question to an LLM (like GPT-4) to generate a tailored answer.
This approach is RAG because the language model is "augmented" with additional knowledge from your data, ensuring it stays factual to your specific domain.
3. About the OpenAI API Key
To use OpenAI’s embeddings and chat completion services, you’ll need an OpenAI API key. This key uniquely identifies you and grants you access to OpenAI’s models.
How to get it:
- Sign up (or log in) at OpenAI’s Platform.
- Go to your account dashboard/settings and find the "API Keys" section.
- Create a new secret key.
- Copy and save it; you’ll use it in your code to authenticate requests.
Architecture
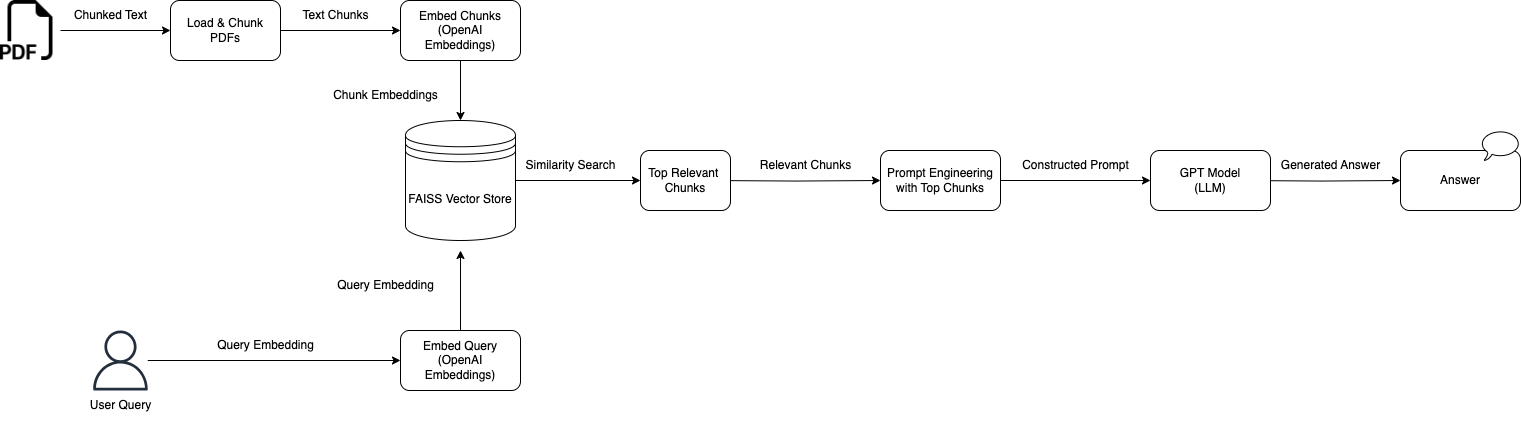
The diagram above outlines a RAG pipeline for answering questions from Sony TV manuals. We:
- Load and chunk PDFs
- Embed chunks using OpenAI’s embeddings
- Store them in a FAISS index
- Embed the user query
- Search FAISS for the top-matching chunks
- Construct a prompt and pass it to GPT
- Generate a context-aware answer
By combining text retrieval with a powerful LLM, which, in our case, we'll use OpenAI's GPT 4o. One of the key advantages of this RAG architecture is that it augments the language model with domain-specific, retrieved context from PDFs, significantly reducing hallucinations and improving factual accuracy.
By breaking down the process into these discrete steps — from chunking PDFs to embedding, to searching in FAISS, to constructing a prompt, and finally generating a response — we enable an effective and scalable Q/A solution that’s easy to update with new manuals or additional documents.
Code and Step-by-Step Guide
For the sake of brevity, we'll move to Google Colab and go through these steps one by one.
By the end of the tutorial, you'll see how this application was able to answer a very specific question related to the PDFs:
Real-World Insights: Speed, Token Limits, and More
- Startup time: Generating embeddings each time can be really slow. Caching or precomputing them on startup will significantly accelerate your response time.
- Parallelization: For larger corpora, consider multiprocessing or batch requests to speed up embedding generation.
- Token limits: You need to keep an eye on how large your combined text chunks and user queries are. Consider setting up some limits while developing your application.
Conclusion
For all the novice developers or tech enthusiasts out there: learning to build your own AI-driven application is immensely empowering. Instead of being limited to ChatGPT, Claude, or Microsoft Copilot, you can craft an AI solution that’s tailored to your domain, your data, and your users’ needs.
By combining prompt engineering, RAG, and vector embeddings, you’re not just following a trend, you’re solving real problems, saving real time, and delivering direct value to anyone who needs quick, factual answers. That’s where the true impact of GenAI lies.
Opinions expressed by DZone contributors are their own.
Comments