Serverless AI Inference
Serverless platforms abstract out the complexities involved in the deployment of machine learning models, handle compute demand and help reduce infrastructure costs.
Join the DZone community and get the full member experience.
Join For FreeServerless computing is a cloud computing model where cloud providers like AWS, Azure, and GCP manage the server infrastructure, dynamically allocating resources as needed. Developers either invoke APIs directly or write code in the form of functions, and the cloud provider executes these functions in response to certain events. This means developers can scale applications automatically without worrying about server management and deployments, leading to cost savings and improved agility.
The main advantage of serverless computing is that it abstracts away much of the complexity related to release management, and developers don’t need to worry about capacity planning, hardware management, or even operating systems. This simplicity frees up time and resources to focus more on building innovative applications and services on top of the deployed models.
AI Model Deployment
Model deployment involves several critical steps to take a machine learning or AI model from development to production, ensuring it is scalable, reliable, and effective. Key elements include model training and optimization, where the model is fine-tuned for performance, and model versioning, which helps manage different iterations. Once trained, the model is serialized and packaged with its necessary dependencies, ready to be deployed in an appropriate runtime environment, such as a cloud platform or containerized service. The model is exposed via APIs or web services, allowing it to provide real-time predictions to external applications.
In addition to deployment, continuous monitoring and the establishment of CI/CD pipelines for automated retraining and model updates are crucial. Security measures are also essential to safeguard data privacy and ensure compliance with regulations. Models must be interpretable, particularly in industries that require an explanation of AI decisions, and feedback loops should be incorporated to refine the model over time based on user input or data changes. Managing resources efficiently to optimize operational costs is also a key element, ensuring that the deployed model remains cost-effective and sustainable. Collectively, these elements ensure that a machine learning model can operate efficiently, securely, and with high performance in a production environment.
Serverless AI Inference
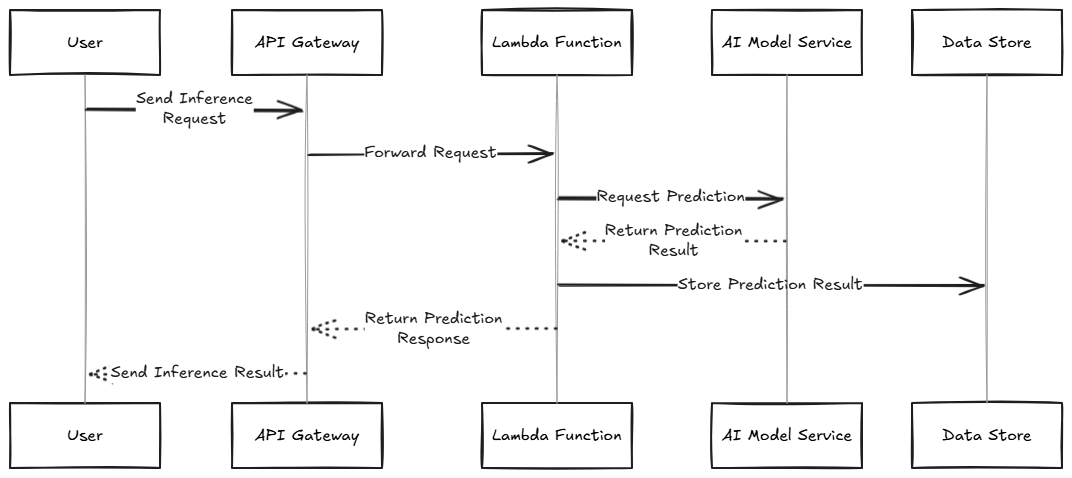
Serverless AI inference refers to the use of serverless computing platforms to deploy and execute machine learning models for making predictions without the need to manage infrastructure or worry about scaling resources.
In this setup, the model is hosted as an API endpoint and users are charged only for the compute time their models actually use, offering cost efficiency and flexibility. Serverless platforms like AWS Lambda, Google Cloud Functions, and Azure Functions enable developers to upload their trained models and expose them through APIs for real-time predictions. This allows businesses to integrate AI-driven decision-making into their applications without needing to manage complex server infrastructure.
One of the primary advantages of serverless AI inference is its ability to seamlessly scale with varying request volumes, making it ideal for use cases like fraud detection, recommendation systems, and real-time image or speech recognition. Additionally, it reduces operational overhead, enabling data scientists and developers to focus on the model's accuracy and performance rather than managing infrastructure. Serverless AI inference is becoming increasingly popular for lightweight, low-latency applications that require fast and cost-effective AI predictions without the need for dedicated infrastructure.
Advantages of Serverless AI
Traditional AI models often require significant resources to deploy and scale, especially in production environments. With serverless infrastructure, developers can tap into a highly flexible, pay-as-you-go model that optimizes both cost and efficiency. Here are several key advantages of serverless AI:
Simplicity
AI models typically require a lot of configuration, especially when scaling across multiple machines for distributed computing. Serverless computing abstracts much of the infrastructure management and allows developers to quickly deploy and iterate on their AI models. Developers can focus solely on the core logic, and as a result, businesses can develop AI-powered solutions faster than ever before.
Scalability
Serverless computing offers virtually unlimited scalability, allowing applications to handle increased demand without additional setup or configuration. For instance, if a particular AI model is serving real-time predictions for a web app and suddenly faces a spike in users, serverless infrastructure can automatically scale to handle this surge without manual intervention.
Cost-Efficiency
Serverless computing operates on a consumption-based pricing model, where users only pay for the actual resources used. This is particularly advantageous when working with AI, as many AI workloads have bursts in traffic, i.e., they need heavy resources during certain times but little or none during others.
Event-Driven Architecture
Serverless platforms are inherently event-driven, making them ideal for AI applications that need to respond to real-time data. This is crucial for scenarios such as fraud detection, anomaly detection, etc.
Serverless Solutions
By leveraging a serverless ecosystem, organizations can focus on innovation, benefit from automatic scaling, optimize costs, and deliver applications faster, all while maintaining a secure and efficient development environment.
- Serverless with AWS: AWS provides a range of services that support serverless AI, such as AWS Lambda, which allows users to run code in response to events without provisioning or managing servers. For machine learning tasks, services like Amazon Sage Maker enable developers to quickly train, deploy, and manage models at scale.
- Serverless with Microsoft Azure: Azure's serverless offerings, such as Azure Functions, allow developers to run AI models and code in response to specific events or triggers, automatically scaling based on demand. Azure also provides robust machine learning services through Azure Machine Learning, which offers tools for training, deploying, and managing AI models at scale.
- Serverless with GCP: GCP provides key serverless services like Cloud Functions for event-driven computing. These services enable seamless integration with GCP’s AI and machine learning offerings, such as Vertex AI, allowing businesses to easily deploy AI models and process real-time data.
Serverless Challenges
Cold Start Latency
Serverless functions can experience a delay when they are invoked after a period of inactivity. For AI models that require high responsiveness, cold starts could introduce latency, which might be a problem for real-time applications.
State Management
Serverless functions are stateless by design, which means that managing the state of an AI model during inference can be tricky. Developers must design their applications to handle session persistence or state externally using databases or distributed caches.
Resource Governance
Many serverless platforms impose limitations on memory, execution time, and CPU/GPU usage. For particularly resource-intensive AI models, this could pose a problem, though it's often possible to design efficient models or split large tasks into smaller functions.
Scheduling Fairness
Scheduling fairness in serverless AI inference ensures equitable resource allocation across concurrent tasks, preventing resource monopolization and delays. It is crucial for balancing latency-sensitive and resource-intensive workloads while maintaining consistent performance. Achieving fairness requires strategies like priority queues, load balancing, and predictive scheduling, though the dynamic nature of serverless environments makes this challenging. Effective scheduling is key to optimizing throughput and responsiveness in AI inference tasks.
Conclusion
Serverless architectures revolutionize the way developers and businesses approach technology by delivering unparalleled scalability, cost efficiency, and simplicity. By eliminating the need to manage and maintain underlying infrastructure, these architectures allow developers to channel their energy into innovation, enabling them to design and implement cutting-edge AI applications with ease. Businesses leveraging serverless computing gain the ability to rapidly adapt to changing demands, reduce operational costs, and accelerate development cycles. This agility fosters the creation of more efficient and powerful AI-driven solutions.
References
Opinions expressed by DZone contributors are their own.
Comments