Data Science and Credit Scorecard Modeling Methodology
Data scientists are responsible for designing and developing accurate, useful, and stable models. This is especially important when it comes to credit risk models.
Join the DZone community and get the full member experience.
Join For Free"Great design is great complexity presented via simplicity." (M. Cobanli)
My responsibility, as a data scientist, is to design and develop an accurate, useful, and stable credit risk model. I also need to make sure that other data scientists and business analysts can assess my model or replicate the same steps and produce the same or similar results.
During the model development process, I try to find answers from the business to a number of questions. Those answers sometimes require a subjective judgment. There is nothing wrong with this subjectivism as long as I can document my questions and corresponding answers. Obviously, if I keep adding those questions and answers to a list, there is a danger of ending up with the huge list that is difficult to follow. I might also end up with some repeated questions or even contradictory answers.
How can I be sure that:
...I will not miss answers to important questions?
...my model will successfully pass a peer-review or audit process?
...my colleagues will be able to replicate the model results?
In order to satisfy the above points, I need:
- Systematic steps — methodology — that I will follow to ensure best practice;
- A supporting structure — theoretical framework — that I will start filling in with my answers;
- A description of a credit risk model setting out important characteristics — model design — that proves business benefits such as generating higher profits.
Once I have identified these important elements, I can start filling in my questions in the right buckets of my theoretical framework and proceed with designing and building the model. The process might look something like this:
Question: How do I tell "bad" from "good" customers? Do they pay 60, 90 or 180 days-past due?
Answer: This is part of my model design. I will seek the answer from the business and I will document it under "operational definition."
Question: When the model predicts "bad"/"good" customers, how long should be the outcome period? Should I fix the date or the length of that period?
- Answer: This is also part of my model design. Again, I need to check with the business what they expect the model to predict. I will file this answer under the "performance window." Once I have established the definition, and the outcome period, I can derive the outcome variable from my data, which will form part of my framework.
Question: Who should be included in the analysis? Do I need to exclude fraudulent customers or those who are somewhere between "good" and "bad" status?
- Answer: In my model design, I need to add a list with all assumptions I make so I can ask the business to confirm.
Question: What are the main characteristics that tell "bad" from "good" customers?
- Answer: This is part of my theoretical framework — specifically, identification of independent variables. I will carry out data exploration to establish the relationships between customers' characteristics and the outcome variable. For example, "customers that have regular income are less likely to default" or "older customers are less likely to default." In scientific terminology, each characteristic, such as income or age, represents a hypothesis that is tested for significance using a statistical method such as logistic regression. Based on statistical analysis, I can decide whether to retain such variables in the model.
The subsequent sections describe scorecard modeling methodology in more details.
Development Methodologies
Any business, research, or software project requires a sound methodology, often in a form of theoretical or conceptual framework. The purpose of the framework is to describe the order of steps and their interactions. This ensures that all important stages are carried out, provides an understanding of the project itself, sets out important milestones and establishes active collaboration among the project stakeholders.
Often, there is more than one established methodology that could be adopted. Data mining projects are typical examples where multiple conceptual frameworks are available. Data mining usually relates to the development of a predictive model used for business purposes. Having a multidisciplinary nature, data mining projects require consideration from different perspectives, including:
- Business: For assessing potential business benefits
- Data science: Ffor creating a theoretical model
- Software development: For developing a viable software solution
Each viewpoint may require a separate methodology but at least two would be required in order to accommodate the above perspectives. Examples of two popular methodologies are Agile-Scrum and CRISP-DM (Cross-Industry Standard Process for Data Mining); the former adopted for addressing both business and software development requirements and the latter adopted for building a business model.
Agile-scrum methodology is a time-boxed, iterative approach to software development that builds software incrementally and has the key objective of delivering value to the business. The methodology promotes active user involvement, effective interactions among stakeholders, and frequent deliveries. As such, it is well suited for data mining projects, which are usually carried out within short time frames and require frequent updates to cope with an ever-changing economic climate.
CRISP-DM is the leading industry methodology for a data mining process model. It consists of six major interconnected phases: (1) business understanding, (2) data understanding, (3) data preparation, (4) modelling, (5) evaluation, and (6) deployment.

Figure 1: CRISP-DM (data mining framework)
The ultimate aim of a predictive model is to satisfy specific business needs with respect to improving the performance of a business and business processes. Business and data understanding are both crucial stages of the CRISP-DM. The outcomes of these two phases should be a sound theoretical framework and model design.
Theoretical Framework and Model Design
A theoretical framework is a building-block foundation that helps identify the important factors and their relationships in a (hypothesized) predictive model, such as a credit risk model. The objective is to formulate a series of hypotheses and decide on a modeling approach (such as logistic regression) for testing those hypotheses. More important, however, is to establish methods to replicate/validate the findings to gain stronger confidence in the rigor of the model.
Key elements of this framework are:
The dependent variable (criterion) for example, "Credit Status"
Independent variables or predictors, such as age, residential and employment status, income, bank accounts details, payment history, or bad-debt history
Testable hypotheses, for example "homeowners are less likely to default"
The model design should follow the accepted principles of research design methodology that is the blueprint for data collection, measurement, and data analysis so the model can be tested for reliability and validity. The former tests the degree to which the model produces stable and consistent results, the latter tests if the model truly represents the phenomenon we are trying to predict, that is, "Did we build the right thing?"
A good model design should document the following:
- The unit of analysis (such as customer- or product-level).
- Population frame (for example, through-the-door loan applicants) and sample size.
- Operational definitions (such as the definition of "bad") and modeling assumptions (for example, excluding fraudulent customers).
- Time horizon of observation (such as, customers' payment history over the last two years) and performance windows, that is the timeframe for which the "bad" definition applies.
- Data sources and data collection methods.
 Figure 2: Utilizing historical data to predict future outcomes
Figure 2: Utilizing historical data to predict future outcomes
The length of the observation and performance windows will depend on the industry sector for which the model is being designed. For example, in the banking sector, both windows are typically longer, compared to the telecom sector where frequent changes in products require shorter observation and performance windows.
Application scorecards are typically applied to new customers and have no observation window because customers are scored using information known at the time of application. External data such as bureau data dominate over internal data for this type of scorecard. Behavioural scorecards have an observation window that utilizes internal data and tends to have better predictive power than application scorecards.
Different scorecards can be applied throughout the entire customer journey starting from acquisition campaigns to predict the likelihood of a customer responding to a marketing campaign. During the application stage, customers can be scored against multiple predictive models, such as their likelihood to default on a credit obligation or predicting fraudulent customers. A range of behavioral scorecard models would be applied to existing customers to predict probability of default in order to set credit limits and interest rates or to plan upsell and cross-sell campaigns; probability to churn for retention campaigns or to predict the likelihood of payback of the debt amount or probability to "self-cure" for collections purposes.
Credit Scorecard Model Development Steps
Once the theoretical framework and model design are specified, we are ready for the next steps within the CRISP-DM. With slight modifications from case to case, the typical steps of credit scorecard development process are outlined in the table below.
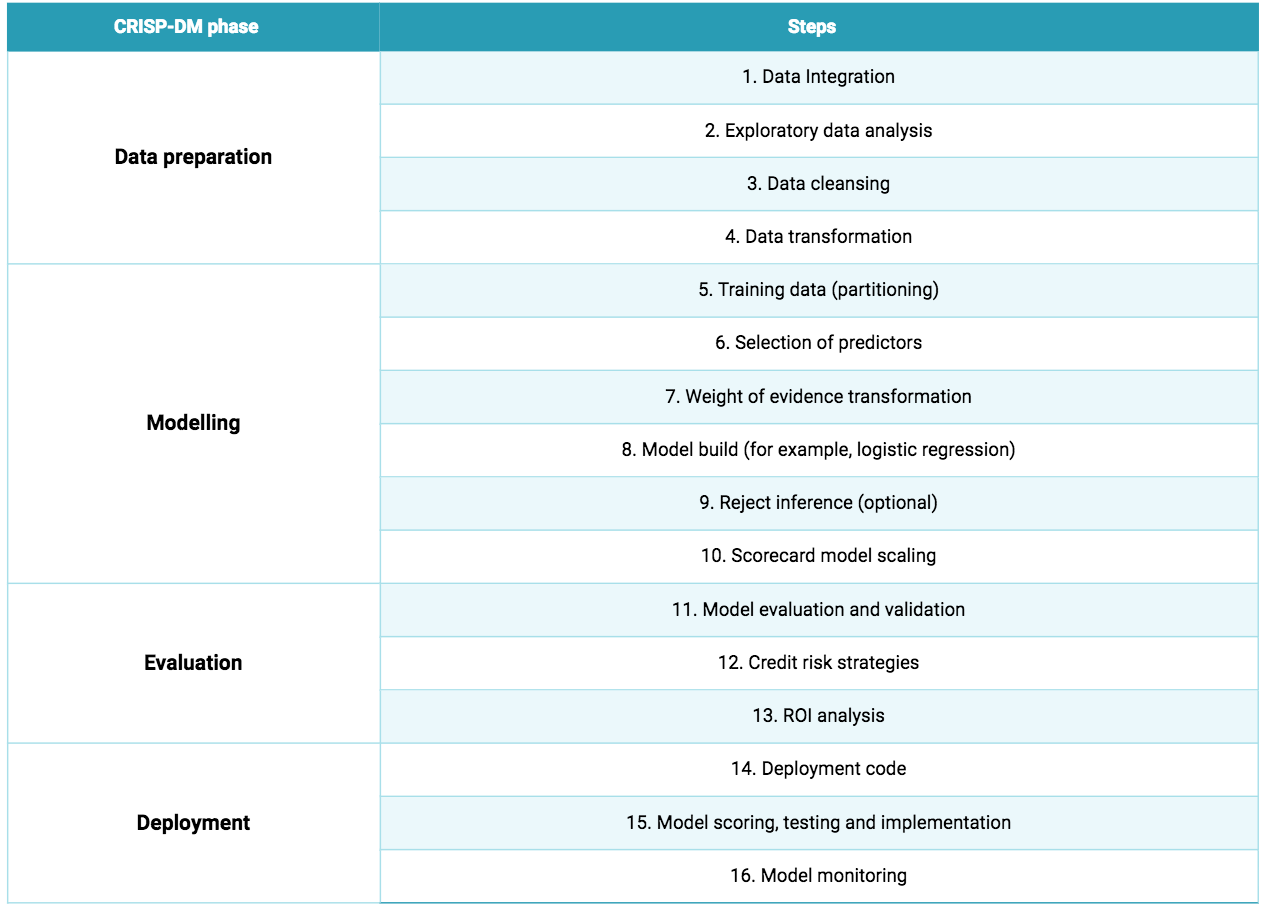
Table 1: Typical steps in building a standard credit risk scorecard model
To be continued...
Published at DZone with permission of Natasha Mashanovich. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments