The Cross-Lingual RAG Problem Nobody Is Talking About
RAG works beautifully in English. For the other 6.5 billion people, it is quietly failing — and the AI community has barely noticed.
Join the DZone community and get the full member experience.
Join For FreeThe Benchmark Trap
The retrieval-augmented generation (RAG) ecosystem has matured remarkably fast. Vector databases are production-grade, embedding models are cheaper than ever, and retrieval pipelines are being deployed across healthcare, finance, legal, and education systems worldwide. Every major benchmark shows impressive numbers.
Almost every major benchmark is in English.
This is not a minor oversight. It is a structural blind spot that has allowed a critical class of failures to accumulate in production systems largely undetected. When your evaluation dataset is monolingual and your deployment is multilingual, you are not measuring what you think you are measuring. The gap between benchmark performance and real-world performance for non-English users is not a rounding error — it is, in documented cases, up to 29% accuracy degradation for non-English queries compared to equivalent English ones.
That number comes from Oracle AI researchers who studied RAG consistency across languages in enterprise deployments. Twenty-nine percent. In a medical context, that is not a metric. That is a patient safety issue.
Where Exactly Does Cross-Lingual RAG Break?
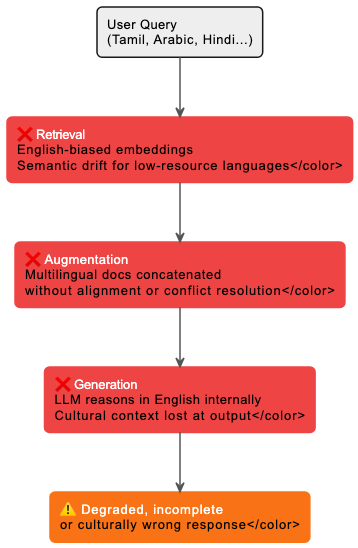
The failure is not in one place. It cascades across all three stages of the RAG pipeline, which makes it particularly difficult to diagnose and fix.
At Retrieval
Most embedding models used in production RAG systems are trained predominantly on English corpora. When a Tamil or Arabic query is embedded, it enters a vector space whose geometry was shaped by English semantics. The nearest neighbors retrieved may appear topically related but carry subtle semantic misalignments that compound downstream.
Amazon AGI's XRAG benchmark, published in 2026, was one of the first systematic evaluations of this failure mode. Their findings were stark: in monolingual retrieval settings, where an English knowledge base serves non-English queries, all evaluated models struggled with response language correctness. The system retrieved the right document. It still got the answer wrong.
At Augmentation
The naive fix — retrieve documents in the user's language alongside English documents and concatenate them into the context — introduces a different problem. A French document and a Hindi document about the same topic may express subtly different facts, use different cultural reference points, or carry implicit contradictions that the model has no mechanism to resolve. Concatenation without alignment is not multilingual RAG. It is multilingual noise.
At Generation
This is the most insidious failure mode. Research has consistently shown that large language models tend to reason internally in English even when processing non-English inputs. The model receives a Tamil query, retrieves relevant context, and then effectively thinks in English before generating a Tamil response. Cultural grounding, local conventions, and contextual meaning are lost at the final and most consequential step.
The result is a response that may be grammatically correct in Tamil but conceptually rooted in English assumptions — wrong units of measurement, unfamiliar care protocols, culturally inappropriate framing.
The Research Is There. The Attention Is Not.
A small but growing body of research is directly addressing this problem. It deserves far more attention than it is currently receiving in mainstream AI engineering conversations.
XRAG (Amazon AGI, 2026) introduced one of the first dedicated benchmarks for cross-lingual RAG evaluation, covering monolingual and multilingual retrieval scenarios with relevancy annotations per retrieved document. Their finding that cross-lingual reasoning — not just language generation — is the core challenge reframes the problem in an important way. This is not a translation problem. It is a reasoning problem.
CroSearch-R1 (Beijing Jiaotong University/Université de Montréal, SIGIR 2026) proposed using reinforcement learning, specifically Group Relative Policy Optimization (GRPO), to dynamically align multilingual knowledge during retrieval. Rather than treating documents in different languages as competing contexts, their framework integrates them as complementary evidence. Results showed measurable improvements in cross-lingual RAG effectiveness across multiple language pairs.
CrossRAG (University of Edinburgh, EACL 2026) took a different approach — translating retrieved documents into a common language before generation rather than translating the query before retrieval. Their experiments showed that this document-side translation strategy significantly outperforms query-side translation, particularly for low-resource languages, because it preserves the semantic richness of retrieval while giving the generation model a consistent linguistic context to reason over.
BordIRLines (ACL 2025) introduced a dataset of territorial disputes across 49 languages to study cross-lingual RAG robustness in culturally sensitive scenarios. Their finding that retrieving multilingual documents actually improves response consistency over monolingual retrieval — when done correctly — is an important signal that the solution lies in better multilingual architecture, not in defaulting to English-only retrieval.
Together, these papers paint a clear picture: the problem is real, measurable, and solvable. What is missing is the engineering community treating it as a first-class concern.
Who Is Actually Affected
The framing of this as a technical NLP problem undersells its human stakes. Consider the populations for whom English-centric RAG is not an inconvenience but a genuine barrier:
A patient in rural Tamil Nadu queries a hospital AI system about post-surgery medication. A student in rural Nigeria is trying to use an AI tutoring system to access global research in Yoruba. A refugee querying a legal AI system about asylum rights in their native Dari. A farmer in rural India is asking an agricultural advisory AI about crop disease treatment in Marathi.
In every one of these cases, a RAG system that was benchmarked at 90%+ accuracy in English may be operating at 60-70% accuracy in the language that actually matters to the user. The people least able to absorb the consequences of AI errors are the ones most exposed to them.
This is not an edge-case population. Over 6.5 billion people speak a language other than English as their primary language. The majority of the world is the edge case in most RAG deployments.
What Good Cross-Lingual RAG Looks Like
The research points toward a few clear architectural principles for building RAG systems that work equitably across languages.
Shared semantic embedding spaces over language-specific ones. Models like mE5, LaBSE, and multilingual-E5-large represent meaningful progress here — they map semantically equivalent content across languages into nearby regions of vector space, reducing the retrieval gap for non-English queries without requiring query translation.
Explicit cross-lingual knowledge alignment rather than naive concatenation. The CroSearch-R1 approach of using RL to integrate multilingual evidence as complementary knowledge is a significant step forward. The goal is a retrieval-augmented context that is linguistically unified before the generation model ever sees it.
Document-side translation over query-side translation when translation is necessary at all. CrossRAG's findings suggest that translating retrieved documents into a common language preserves more semantic fidelity than translating the user's query into English. This is counterintuitive but empirically supported.
Culture-aware generation as a design goal, not an afterthought. Language and culture are not separable. A RAG system that generates linguistically correct but culturally inappropriate responses has not solved the problem — it has reframed it.
A Proposal Worth Exploring
The building blocks for genuinely equitable cross-lingual RAG exist today. What does not yet exist is an intentional, end-to-end architecture that assembles them with language equity as a first-class design principle rather than a post-hoc consideration.
We call this architectural vision PolyRAG — a framework that coordinates multilingual semantic retrieval, reinforcement learning-based cross-lingual knowledge fusion, and culture-aware generation into a unified pipeline. The goal is not to make RAG work slightly better in non-English languages. It is to eliminate the architecture-level reasons why it fails in the first place. Each of the three components draws from independently validated research. What remains is the engineering work of intentionally combining them, rigorously benchmarking them across low- and high-resource language pairs, and releasing the results openly so the broader community can build on them.
The Conversation We Should Be Having
The RAG community has done extraordinary work optimizing retrieval latency, chunk strategies, reranking approaches, and hallucination reduction. Almost all of it assumes English. The question worth asking in 2026 is simple: what would RAG look like if we designed it for everyone from the start?
Opinions expressed by DZone contributors are their own.
Comments