CRUD Operations on Deeply Nested Comments: Scalable Spring Boot and Spring Data approach
In this post, I present CRUD operations on deeply nested comments, stored in a relational database via Spring Boot and Spring Data. The approach is scalable but uses only JPQL and very few pessimistic locks.
Join the DZone community and get the full member experience.
Join For FreeThis post continues my previous post on the subject. In that post I describe the data structures, schema, data transfer object, indexing algorithm, filtering algorithms; also in that post, I review the literature and analyze complexity. Here, I show the actual CRUD operations. The approach is scalable, JPQL-only, and uses very few pessimistic locks. Spring Initializr code can be found here. Let's recall the requirements for this task.
The Requirements
We build a CRM system for a mid-size online education center. The system is implemented with Spring Boot 2, H2(development), and (for now) Ms-SQL(production) technology. Among many functionalities, the system must be able to create, read, update, and delete nested comments from/to a relational database. The functional requirements for the comment functionality are:
- The most common operations are to find all descendants of a particular comment and to find all root comments,
- All new and edited comments are moderated before being published and saved into the database,
- If a comment is deleted, all its child comments are deleted as well,
- The system should support full-text search over comments' content.
We assume the following about the comments:
- The comments are text strings no more than a certain length (no pictures or video fragments for now),
- Every comment has 0 or 1 parent,
- Most of the comments are questions/answers/hints on assignments and classes, so there going to be a lot more reads than writes,
- Ones saved, the comments are rarely updated and even more rarely, if ever, deleted,
- The older the comment gets, the lesser it is commented; the total number of child comments of a particular comment rarely exceeds a certain (large) number; the number depends on the depth of the comment.
- For every root comment, there are a lot more sub root comments. This can be achieved, for example, if only users of a certain role or reputation can create root comments.
- The majority of the comments are just few levels deep. Much deeper comments are rare.
The following are the implementation details for the comment functionality:
- the functionalities need to be implemented with JPQL only and no native queries,
- there should be as few pessimistic locks as possible.
These requirements are not easy to satisfy simultaneously.
The Challenges
To implement these requirements, we face the following challenges:
- The data structures must be compatible with the relational database (rows and columns), yet implement a deeply nested tree (this challenge is addressed in Part 1).
- There should be efficient indexes to quickly find all children of a particular comment, yet no dialect-specific database features should be used (this challenge is addressed in Part 1).
- If all comments are stored in a single table, all root comments can not be found quickly without advanced dialect-specific database features. Yet, if all root comments are stored in a separate table, we have to use transactions (and pessimistic locks).
Notice, that if we use a JPQL-only approach, then transactions are inevitable since we have to process at least some data on the server side. To make as few transactions as possible, we need to separate methods, where transactions are absolutely necessary, from methods that can work without transactions. Let's see how to use our requirements, data structures, and algorithms to achieve this.
The Solution
The CRUD operations are Create, Read, Update, Delete. Let's start with Create.
Create
We create root and sub root comments separately in a @SessionScope service. This scope means that a new session instance is created for every user session. We need a separate service instance to avoid data procession bottlenecks of singleton (default) scoped services.
xxxxxxxxxx
public class CommentCRUDServiceImpl implements CommentCRUDService{
...
public void saveComment(Comment comment, String parentPathString) {
comment.setPathString(parentPathString);
comment = indexService.setPathRnd(comment);
comment = indexService.setDepthOutOfPath(comment);
comment = indexService.computeIndex(comment);
comRepo.saveAndFlush(comment);
}
public void saveRoot(Comment comment) {
comment = comRepo.save(comment);
comment = indexService.setPathRnd(comment);
comment = indexService.setDepthOutOfPath(comment);
comment = indexService.computeIndex(comment);
}
...
}
For the sub root comment, we first concatenate a random number with the parent path string, then compute the depth, then compute index, then, finally save and flush the new comment. The database auto generates an id for the comment.
For the root comment, the procedure is different. First, we need to get an id for a new root comment (line 14). Then, we assign the path string and compute the index. Finally, the modified root comment is saved and flushed automatically, since it is within a transaction (as explained here). Also, let's keep in mind that the saveRoot method needs to be called from outside the service. According to our assumption 6, root comments are not created often and so this transaction doesn't happen often.
Read
We read all root comments and all descendants of a comment in separate operations. See the code for details.
xxxxxxxxxx
public class CommentCRUDServiceImpl implements CommentCRUDService{
...
public CommentDto findCommentDto(Comment parent){
Collection<Comment> comments = findCommentsByPathWithParent(parent.getPathString());
return filterService.filterComments(comments,parent);
}
(value = "rootComments", key = "#id")
public Collection<Comment> findAllRootComments(){
return comRepo.findAllRootComments();
}
...
}
To find all descendants of a comment, we first read all the comments in the index interval of the parent.getPathString(). Of course, we certainly get the parent itself and are likely to get the comment's ancestors and neighbors. So, the method filterService.filterComments(comments,parent) filters the contaminants. See Part 1 for details on how this algorithm works.
To find all root comments, we read all the elements of depth=1:
xxxxxxxxxx
public interface CommentRepository extends JpaRepository<Comment, Long> {
...
( "SELECT c FROM Comment c WHERE c.depth=1" )
Collection<Comment> findAllRootComments();
...
}
Notice, that the transaction wrap doesn't allow a root comment to be saved with its pathString=null . We have to scan through the whole table to find all root elements! This is a very long operation, so we need to cache the result. The key="#id" annotation tells Spring to retrieve the root comments from the cache by the id field.
Update
This is the easiest operation to program:
xxxxxxxxxx
public class CommentCRUDServiceImpl implements CommentCRUDService {
...
public Comment updateSubRoot(Comment c) {
return comRepo.saveAndFlush(c);
}
(value = "rootComments", key = "#c.id")
public Comment updateRoot(Comment c) {
return comRepo.saveAndFlush(c);
}
...
}
The comment c with updated content is saved and flushed into the repository. Notice that we update the rootComments cache with @CachePut(value = "rootComments", key = "#c.id") as the updated comment is saved and flushed.
Delete
This operation takes even more time to complete than to read all descendants of a comment. However, according to assumption 4 and our moderation policy, it rarely, if ever, happens. So, the code is:
xxxxxxxxxx
public class CommentCRUDServiceImpl implements CommentCRUDService{
...
public void deleteComment(Comment parent){
Collection<Comment> comments = findCommentsByPathWithParent(parent.getPathString());
comments = filterService.filterCommentsForDelete(comments,parent);
comRepo.deleteAll(comments);
}
...
}
Here, we first find all the "contaminated" descendants of the element. Then filter the result. Finally, we delete the result collection from the database. See the code for details. The filterCommentsForDelete method works the same as filterComments, but returns a collection rather than a CommentDto with nested children. Let's take a deeper look at how these operations are implemented.
Implementation Details
We already pointed out on the @SessionScope of the services. Also, we have a number of sharable constants in this project; the constants are the scale, the index and database epsilons, and others. How to make sure we don't mess them in different methods? We assemble most of them in a separate config service:
xxxxxxxxxx
public class ComputationConfigServiceImpl implements ComputationConfigService{ ("${comment.crud.scale}")
private int SCALE;
public BigDecimal giveOne() {
BigDecimal one = new BigDecimal(1);
one = one.setScale(SCALE, RoundingMode.HALF_UP);
return one;
}
...
}
This service is injected into the index computation service this way:
xxxxxxxxxx
public class CommentIndexServiceImpl implements CommentIndexService {
...
private static MathContext mc;
private static BigDecimal eps;
private static BigDecimal one;
private static BigDecimal half;
public CommentIndexServiceImpl(ComputationConfigService ccs){
this.mc = ccs.giveMathContext();
this.one = ccs.giveOne();
this.half = ccs.giveHalf();
this.eps = ccs.giveIndexEps();
}
...
}
The scale is located in the application.properties:
comment.crud.scale = 64
Such architecture makes our code robust against inconsistent constants over different services. So, what comes out of all this?
The Results
The CRUD operations are tested on the following test set (Fig 1):
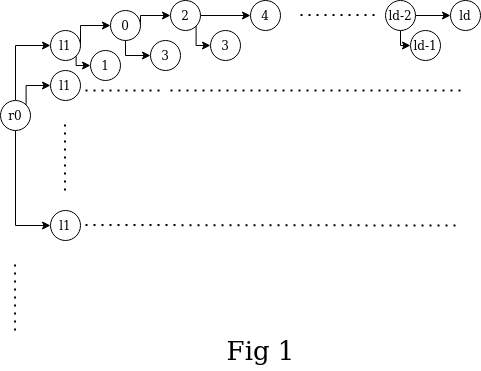
Every root element has 500 children. Every level 1 comment has a "pin tree" of descendants; the tree is of depth d. All the children of a particular level are marked as li, where i is the level's depth (up to d). We experimented with d from 100 to 500.
To test the read and create operations for the Continous Fraction index algorithm, we call findCommentDto for all 500 "pin trees" of r1 for 10 times and for different comment depths, where 100 is the total depth. Surprisingly, even after 5000 runs, there are large error bars! The error bars are estimated after a few runs of this procedure. Also, we run this procedure for the naive 'LIKE path%' approach. The results are as follows (Table 1):
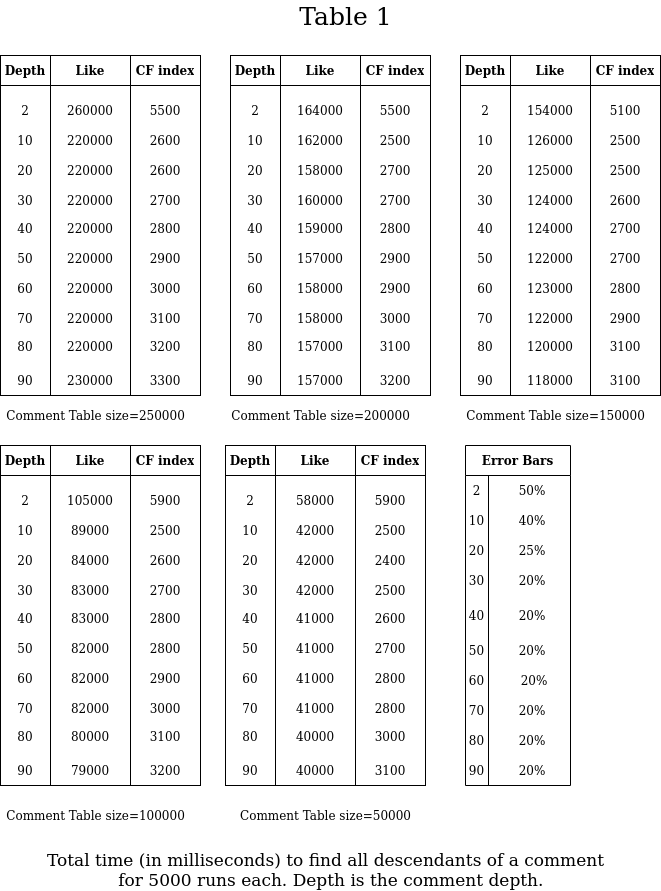
The data is easy to interpret even without plots:
- The time of the CFi read operation depends very little on the total table size, while the 'LIKE' read operation increases linearly with the total table size,
- The CFi read times don't change after around
depth=10. This means that after that depth, the total number of "contaminated" reads doesn't change much since the index already reached the database precision of 28 digits. - It takes of order 0.005 milliseconds to retrieve a single child per 1 CPU core. A close value is obtained from a single fresh run, so the value doesn't come from the cache.
- Obviously, the time it takes to filter the descendants is much less than the time to retrieve them. As it is pointed in Part 1, we can filter contaminants on the browser side.
To verify the second statement, let's investigate how CFi read times depend on the total "pin tree" depth. The results for a single root comment with 500 level 1 children are as follows:

Clearly, the CFi read time depends linearly on the total number of "contaminated" reads. So, we proved that the CFi algorithm depends very little on the total table size and depends linearly on the index "density". The delete and update operations were tested on this test set and on the test set from Part 1. For the delete operation, we made sure the parent is also deleted. See the code for details. These are all the interesting results we got so far.
The Conclusions
In this post, I presented a Spring Boot implementation of CRUD operations on deeply nested comments, located in a relational database. The implementation is well-scalable, JPQL-only, and uses very few transactions. The only downside is extra comments to retrieve and filter. With present day bandwidth and client side processing power, this downside is easily tolerable since text comments and their hierarchy information have a very little footprint.
Acknowledgments
I would like to thank my mentor Sergey Suchok for his help in this project.
Opinions expressed by DZone contributors are their own.
Comments