Microsoft Azure Data Lake
In this article, see how a team created a central controlled data repository with the MS Azure echo system.
Join the DZone community and get the full member experience.
Join For Free2020 is different in every way, but one thing is constant for the past many years i.e. data and its role in molding our current technology. Recently, I was part of the team to create a central controlled data repository containing clear, consistent, and clean data. While exploring the technologies we landed on MS Azure echo system.
MS Azure echo system for developing data lakes/data warehouse is becoming mature and providing good support when it comes to the enterprise-level solutions. Starting from Azure Data Factory, it gave a good ELT/ETL processing with code-free services. This is very helpful to create pipelines for data ingestion, control flow, and moving data from source to destination. These pipelines have the capability to run 24/7 and ingest petabytes of data. Without the support of a data factory data movement between different enterprise systems requires a lot of effort and at times will be very expensive to develop and maintain. Additionally, there are more than 90 built-in connectors in Azure Data Factory which will help to connect with most of the sources like S3, Redshift, BigQuery, HDFS, Salesforce, and enterprise data warehouse to name a few.
Next comes Azure Functions, which are serverless computing services in MS Azure and helps in running small pieces of code without worries about creating an underline infrastructure, this will tremendously help ease in software development. Azure functions are pay-per-use which is good for cost-effective and support multiple languages like C#, Javascript, Python, etc. These functions serve multiple use cases like creating APIs, webhooks, and micro-services. There are many built-in templates provided by Microsoft such as HTTP request/response, connecting to a Data lake (blob storage), event hub, and/or queue storage. These templates and easy to use and get someone starting within minutes.
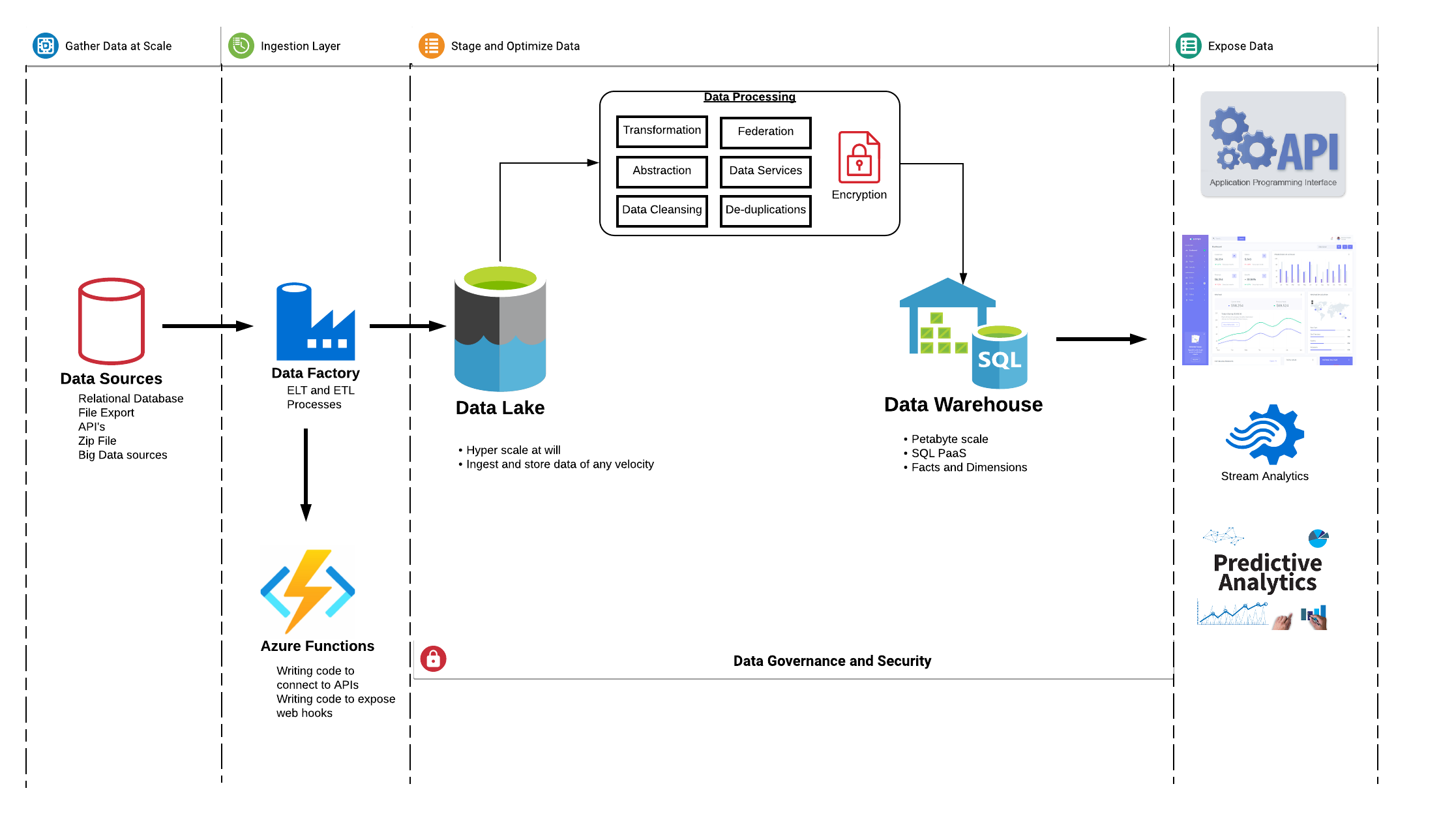
Following is the high-level flow that would be a good fit for most of the applications.
Data Flow:
Will discuss some more component of MS Azure in the next series, with some examples.
Opinions expressed by DZone contributors are their own.
Comments