Database Connection Pooling With Pgbouncer
Join the DZone community and get the full member experience.
Join For FreeIntroduction: The Postgres Connection Pool Problem
When Postgres was created nearly 25 years ago, the developers decided not to use threads for new requests; rather, they decided to create a new process for each request. Their reasoning was that processes were less likely to cause memory corruption, and in the end weren’t all that expensive to create on the targeted platform (Unix). Since then, that decision has sparked a lot of conversation. But the developers have stood by their decision and have been resistant to a re-architecture.
At the time, the decision to use processes was fine. But modern apps (microservices, for example) tend to require a lot of connections and use and release those connections very quickly. So while the “no threads” decision was tenable ten years ago, today the inability for Postgres to scale is a serious issue. Luckily, this is a well-known issue that developers have been facing and solving for years.
So what is the answer? Connection pools.
In this article, we’re going to look at connection pooling and options for connection pools on Postgres. Then, we’ll implement a PgBouncer connection pool on an app.
What Are Connection Pools?
Connection pools are a cache of open database connections that can be reused by clients. Using a pool mitigates strain on the database by reducing requests for new connections. Pools also increase the performance of individual database calls, since no time is spent requesting and opening the connection).
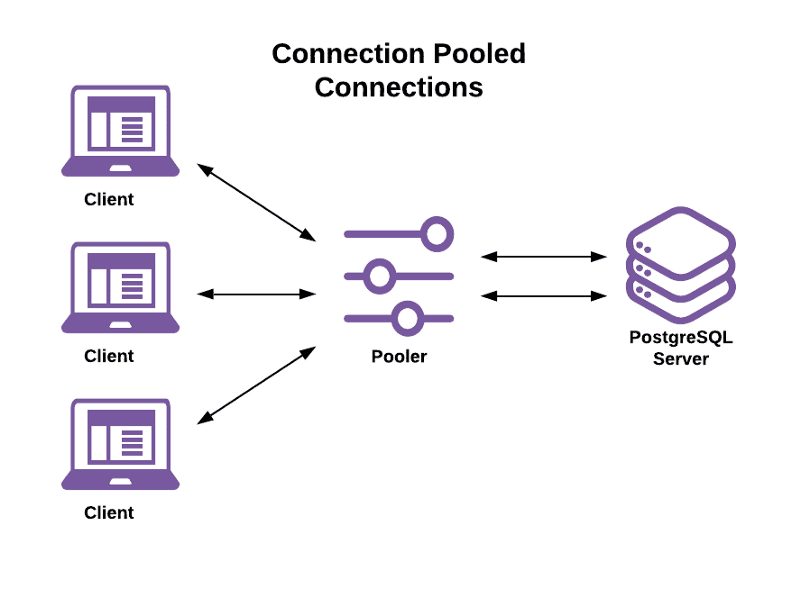
From a high level, a connection pool works like this:
- The user requests a database connection.
- The pool checks for an existing and available cached connection.
- If a cached connection is found, it’s returned to the user.
- If a cached connection is not found, a new connection is created — as long as the pool adheres to the connection pool settings, such as the max pool size, max connections allowed to the database, max connections allowed per user, and so on.
- If creating a new connection violates any of those settings, the request is queued until a connection is available or a new one can be created.
Where to Create a Connection Pool
Here are some pros and cons to help you decide:
Pros:
- Low latency since the pool is on the same box as the requester
- Better security since the connections are constrained to one client
- No need to learn a new tool
- Difficult to monitor and control connections to the database since you can end up with multiple pools from multiple clients
- Optimized for your language, not necessarily for Postgres
Your pool is separate from your code but runs on the same machine as your client app.
- Low latency and better security, similar to language level
- Optimized for Postgres, not for your language
- Again, similar to language level, it can be difficult to monitor and control connections
Your pool runs between the client and database, either on a stand-alone server, or on the same machine as your database.
- Flexible — database can be swapped out
- Optimized for Postgres, not for your language
- Centralized control of connections, which make it easier to monitor and control connections
Cons:
- You’ve introduced a new layer, so also new latency
- Single point of failure for database calls across all clients
- Potential security issues since you’re sharing connections between layers
- Yet another layer to maintain
Postgres Middleware Connection Pool Options
- Basic connection pooling
- Also offers load balancing, replication, and other advanced features
- Basic connection pooling. That’s it.
- Lightweight and better performance
This is usually a pretty easy decision. Both options are established solutions, work well, and have a solid user base. The deciding factor is if you need just connection pooling or more. Pgpool-II is a little slower and heavier but has advanced features, such as load balancing.
Implementing a Middleware Connection Pool With PgBouncer
So let’s run through a sample deployment of PgBouncer on an existing app to see how it works. For this setup, I’m going to use Heroku so we can quickly get something deployed and working with minimal hassle. The process will be simple since Heroku is a PaaS provider and handles most of the DevOps steps for us. Other IaaS and PaaS providers most likely offer something similar, and even if you prefer to work at a low level, implementing PgBouncer is not too difficult.
I’m going to base my example off this guide to PgBouncer and this guide on Postgres connection pooling from Heroku.
Before we deploy or write any actual code, we have a few architectural decisions to make. The first is to pick a server-side or client-side implementation. You find an in-depth discussion on this topic here. But since we’ve already decided on middleware for this example, that’s what we’re going to stick with.
Since the server-side implementation on Heroku is still in beta, we’re somewhat restricted on our other configuration options. If you need more advanced configuration options, you’ll need to use the client-side installation. But typically, in addition to server versus client deployment, you would also consider the following:
There are three different connection pooling modes available in PgBouncer. These modes determine exactly when a connection is returned to the connection pool. The modes are:
- Statement — the connection is returned to the pool as soon as the statement is executed (auto-commit is always on)
- Transaction — the connection is returned to the pool as soon as the transaction is complete (a commit or rollback is executed)
- Session — the connection is returned to the pool as soon as the user session is closed
Typically, you’ll want to use transaction mode, as most apps need a database connection only when inside a transaction. Between transactions most apps are waiting for the user, executing logic, and so on, and don’t need a database connection. However, it’s worth reading through the typical use cases for each mode to ensure you’re using the best one.
There are quite a few pool settings for PgBouncer. For example, here are five common settings:
- pool_size — just like it sounds, the size of the pool. The default is 20. For Heroku server-side plans, the default is your plan’s connection limit times 0.5.
- reserve_pool_size — a reserve pool used in times of usage bursts
- max_db_connections — the max number of connections allowed to the database. For Heroku server-side plans, the default is your plan’s connection limit times 0.75.
- max_user_connections — the max number of connections allowed per user
- max_client_conn — the max number of incoming client connections allowed (among all users). For Heroku server-side plans, the default is 1000.
That’s a lot to configure and optimize, and there are still yet more settings . You can read about those settings and what they do here.
For our example, we’ll use transaction mode and the default pool settings as configured by Heroku on installation.
Deploying Our Example
I wanted to start with a deployment that is already using Postgres, and then convert it to a connection pool. So I’m going to use this project as my base deployment (and again, this guide on Postgres connection pooling). This project deploys a Node.js app connected to a Postgres database (without connection pooling). It takes about 10 minutes to get it up and running so it’ll be perfect for our quick example.
If you haven’t used Heroku before but still want to follow along, don’t worry — the guide walks you through step-by-step. The only change you’ll need to make is in provisioning the database near the end of the setup. Since you can’t use the hobby edition for connection pooling, you’ll need to use a standard plan (the lowest-paid monthly plan) database instead. Use this line in the Heroku CLI to provision the database:
$ heroku addons:create heroku-postgresql:standard-0
Once you’re done with the setup and your app is up and running, you can open your app (with "/db" at the end of the URL) and see this page:
Great! If you followed that guide, you’re all set with a Node.js app connected to Postgres with a test table. Now let’s see how easy it is to start using a connection pool with PgBouncer. It’s just a few simple steps using the Heroku CLI:
1. Enable pooling. The below command creates both the pool and a connection pool URL (using the current database URL).
$ heroku pg:connection-pooling:attach DATABASE_URL — as DATABASE_CONNECTION_POOL
2. Change your configuration to use the pool URL instead of the database URL.
 3. Commit your changes and restart.
3. Commit your changes and restart.

With this code deployed, I hit the /db URL twice. Let’s look at the stats after each run to see what happened. To see the stats, first use the commend heroku config to find your database connection pool URL. Then issue the command:
$ psql postgres://username:password@ec2–192–168–1–1.compute-1.amazonaws.com:5433/pgbouncer
using your database connection pool URL and replacing the final component of the path with ‘pgbouncer’.
Now you can try different options, such as show stats or show pools.
Here’s what we see with show stats_totals after the two runs. There are lots of queries running at the db level:
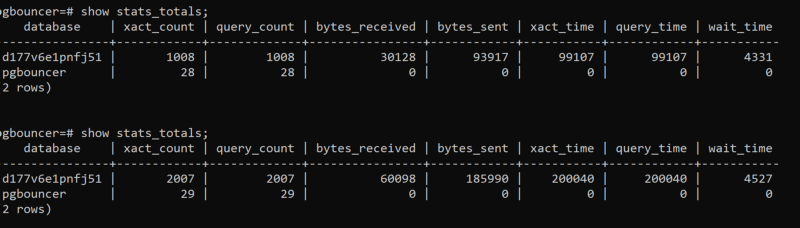
And now
show pools while the queries are running. There’s just one “active” connection being reused for all those queries:

What’s Next?
There are a several ‘gotchas’ to watch out for with PgBouncer and other connection pools. Here are some items to be aware of and resources to help you dig further.
Monitoring
While you can use show stats as in my example, these are pretty basic metrics. When you use a connection pool, you’ll want to use a more robust monitoring solution. Check out this article on using both the USE and RED frameworks when monitoring connection pools.
Client vs. Server
The choice of deploying the pool to the client or server can be a tough one. For more info, check out the PgBouncer FAQ, which discusses latency versus control.
Prepared Statements
Since prepared statements, by nature, are created before the database connection is opened, they typically cause issues with connection pools. Again, I recommend the PgBouncer FAQ as a place to start on this topic.
Conclusion
Hopefully you now have an idea of why you need connection pooling with Postgres, what your implementation options are, and how a typical PgBouncer implementation looks.
Opinions expressed by DZone contributors are their own.
Comments