Database Release and End-to-End Testing
A tech company that uses ClickHouse database cloning with JuiceFS for efficient end-to-end testing, improving data quality and consistency.
Join the DZone community and get the full member experience.
Join For FreeIn the world of software development, rigorous testing and controlled releases have been standard practice for decades. But what if we could apply these same principles to databases and data warehouses? Imagine being able to define a set of criteria with test cases for your data infrastructure, automatically applying them to every new "release" to ensure your customers always see accurate and consistent data.
The Challenge: Why End-to-End Testing Isn't Common in Data Management
While this idea seems intuitive, there's a reason why end-to-end testing isn't commonly practiced in data management: it requires a primitive clone or snapshot for databases or data warehouses, which most data systems don't provide.
Modern data warehouses are essentially organized mutable storage that changes over time as we operate on them through data pipelines. Data typically becomes visible to end customers as soon as it's generated, with no concept of a "release." Without this release concept, running end-to-end testing on a data warehouse makes little sense, as there's no way to ensure what your tests see is what your customers will see.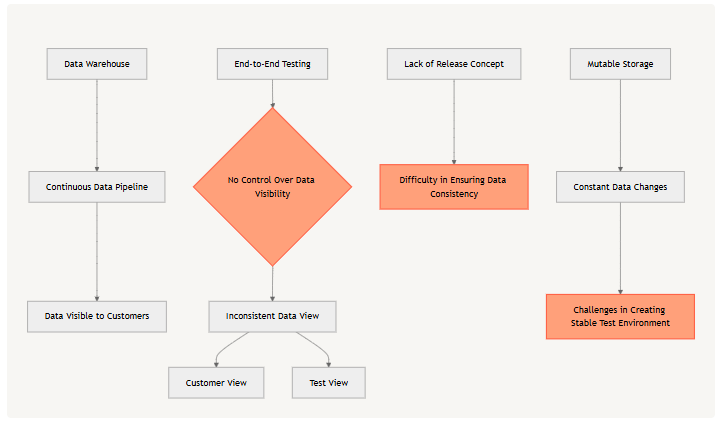
Existing Approaches and Their Limitations
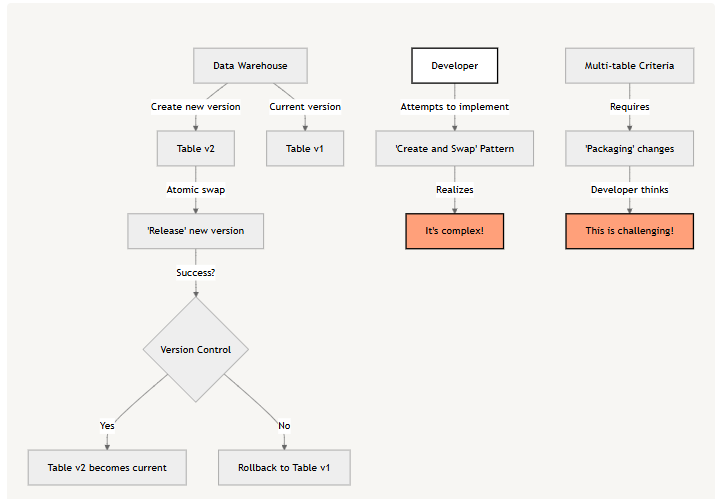
Some teams have developed version control systems on top of their data warehouses. Instead of directly modifying tables queried by end users, they create new versions of tables for changes and use an atomic swap operation to "release" the table. While this approach works to some extent, it comes with significant challenges:
- Implementing the "create and swap" pattern efficiently is complex.
- Ensuring criteria involving multiple tables (e.g., verifying that every row in an order table has a corresponding row in a price table) requires "packaging" changes to multiple tables in a "transaction," which is also challenging.
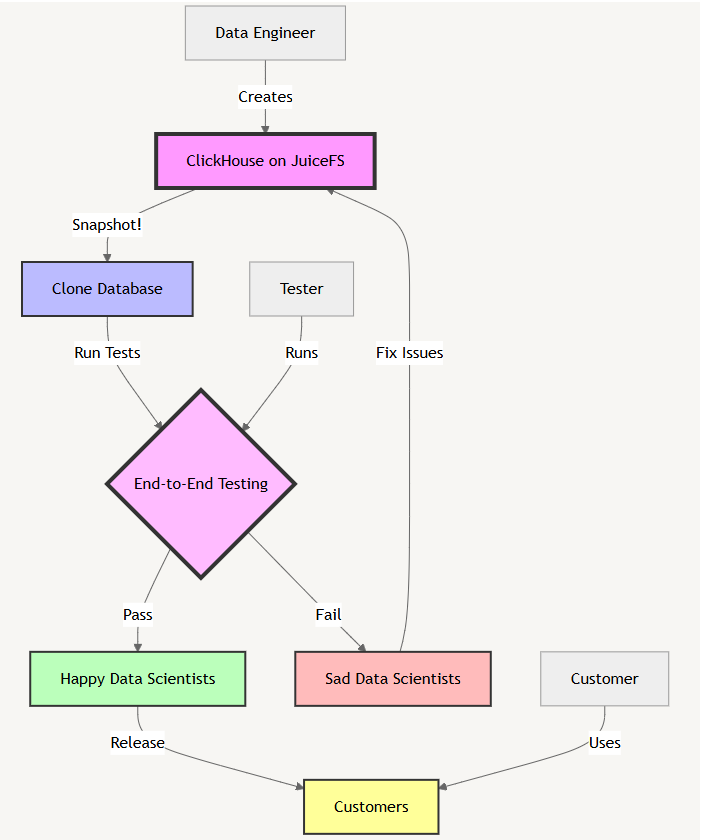
A Solution: ClickHouse Database Clone Powered by a Distributed File System
We've developed a system to "clone" ClickHouse databases as replicas, leveraging the power of JuiceFS. This approach, detailed in our earlier article, "Why and How We Built a Primary-Replica Architecture of ClickHouse," offers a promising solution.
Here's how it works:
- We run our ClickHouse database on JuiceFS, a POSIX-compatible shared file system backed by Object Storage Service (OSS).
- JuiceFS provides a "snapshot" feature that implements git branch semantics.
- Using a simple command like
juicefs snapshot src_dir des_dir, we can create a clone ofsrc_diras it exists at that moment.
This approach allows us to easily replicate/clone a ClickHouse instance from the running instance, creating a frozen snapshot that can be considered a "release artifact."
Implementing End-to-End Testing With Database Clones
With this mechanism in place, we can run end-to-end testing against the ClickHouse replica and control its visibility based on the test results. This replicates the release workflow that has been standard in software development for decades.
Data end-to-end tests can now be developed, organized, and iterated using common unit testing frameworks (we use pytest). This approach has empowered us to codify our infrastructure and business criteria for data availability and reliability into data tests.
A typical test is the table size test, which helps prevent data issues caused by accidental or temporary table damage. You can also define business criteria to safeguard your data reports and analytics from unintended changes in data pipelines that might result in incorrect data. For example, you can enforce uniqueness on a column or a group of columns to avoid duplication—a critical factor when calculating marketing costs.
Real-World Impact
At our company, this architecture has been instrumental in preventing almost all P0 data issues that might have otherwise been exposed to end customers in recent quarters. It's truly a game-changing initiative!
Beyond ClickHouse: Broader Applications
This approach isn't limited to ClickHouse. If you run any kind of data lake or lakehouse on top of JuiceFS, it could be even easier to replicate the release mechanism described in this article.
Conclusion
By bringing modern software development practices to the world of data management, we can significantly improve data quality, reliability, and consistency. The combination of database cloning and end-to-end testing offers a powerful toolset for ensuring that your customers always see the right data, just as they expect to see the right features in a well-tested software release.
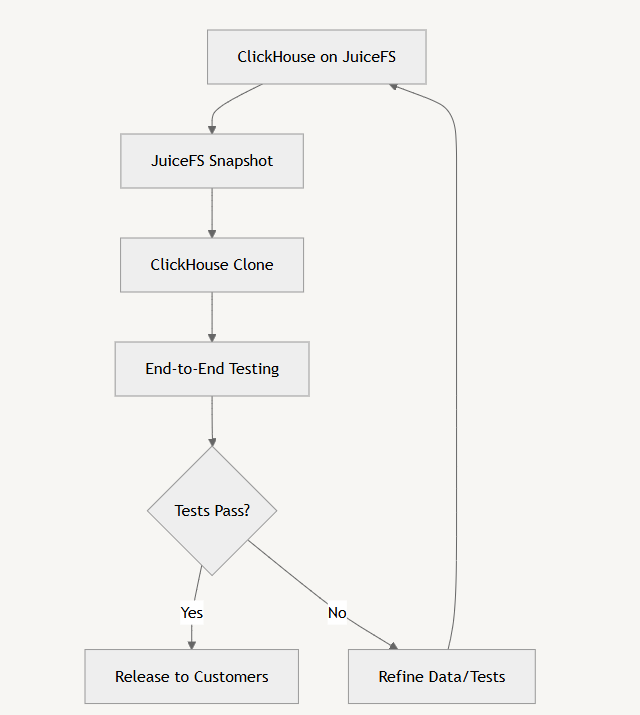
This diagram illustrates the workflow of our database release and end-to-end testing process, showcasing how we've brought software development best practices into the data world.
Published at DZone with permission of Tao Ma. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments