Modern ETL Architecture: dbt on Snowflake With Airflow
Build a scalable ETL pipeline with dbt, Snowflake, and Airflow, and address data engineering challenges with modular architecture, CI/CD, and best practices.
Join the DZone community and get the full member experience.
Join For FreeThe modern discipline of data engineering considers ETL (extract, transform, load) one of the processes that must be done to manage and transform data effectively. This article explains how to create an ETL pipeline that can scale and uses dbt (Data Build Tool) for transformation, Snowflake as a data warehouse, and Apache Airflow for orchestration.
The article will propose the architecture of the pipeline, provide the folder structure, and describe the deployment strategy that will help optimize data flows. In the end, you will have a clear roadmap on how to implement a scalable ETL solution with these powerful tools.
Current Challenges in Data Engineering
Data engineering groups frequently encounter many problems that influence the smoothness and trustworthiness of their work processes. Some of the usual hurdles are:
- Absence of data lineage – Hardship in monitoring the migration and changes of data throughout the pipeline.
- Bad quality data – Irregular, false, or lacking data harming decision-making.
- Limited documentation – When documentation is missing or not up to date, it becomes difficult for teams to grasp and maintain the pipelines.
- Absence of a unit testing framework – There is no proper mechanism to verify transformations and catch mistakes early on.
- Redundant SQL code – Same logic exists in many scripts. This situation creates an overhead for maintenance and inefficiency.
The solution to these issues is a contemporary, organized technique toward ETL development — one that we can realize with dbt, Snowflake, and Airflow. dbt is one of the major solutions for the above issues as it provides code modularization to reduce redundant code, an inbuilt unit testing framework, and inbuilt data lineage and documentation features.
Modern ETL Pipeline Data Architecture
In the architecture below, two Git repos are used. The first will consist of dbt code and Airflow DAGs, and the second repo will consist of infrastructure code (Terraform). Once any changes are made by the developer and the code is pushed to the dbt repo, the GitHub hook will sync the dbt get repo to the S3 bucket. The same S3 bucket will be used in Airflow, and any DAGs in the dbt repo should be visible in Airflow UI due to the S3 sync.

Once the S3 sync is completed, at schedule time, the DAG will be invoked and run dbt code. dbt commands such as dbt run, dbt run –tag: [tag_name], etc., can be used.
With the run of dbt code, dbt will read the data from source tables in Snowflake source schemas and, after transformation, write to the target table in Snowflake. Once the target table is populated, Tableau reports can be generated on top of the aggregated target table data.
dbt Project Folder Structure

staging/
sources/→ Defines raw data sources (e.g., Snowflake tables, external APIs).base/→ Standardizes column names, data types, and basic transformationstransformations/→ Applies early-stage transformations, such as filtering or joins.
intermediate/
-
Houses tables that are between staging and marts, helping with complex logic breakdown.
marts/
- Divided into business areas (f
inance/,marketing/,operations/). - Contains final models for analytics and reporting.
Deployment Strategy
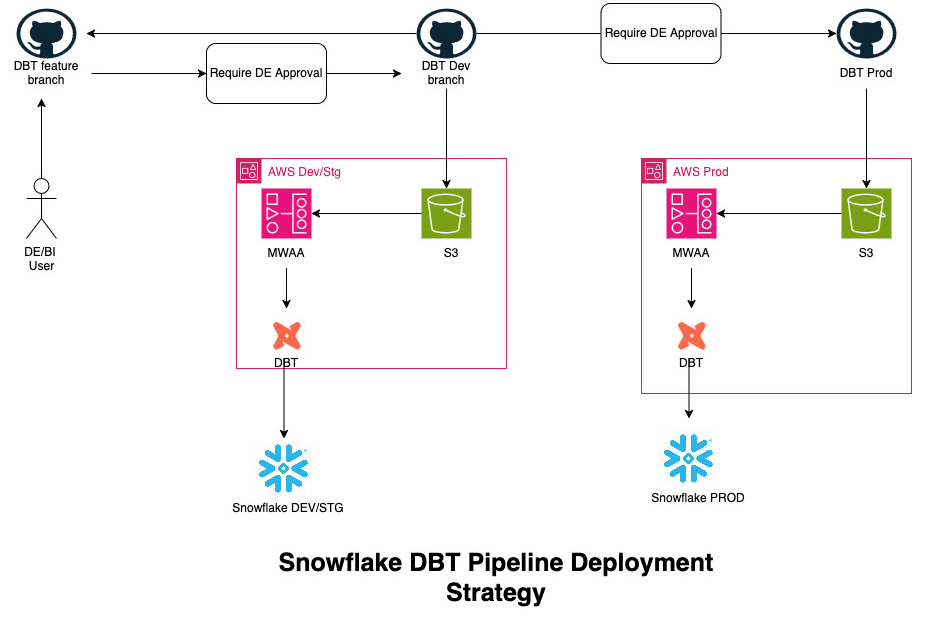
- The dbt repository will have two primary branches: main and dev. These branches are always kept in sync.
- Developers will create a feature branch from dev for their work.
- The feature branch must always be rebased with dev to ensure it is up-to-date.
- Once development is completed on the feature branch:
- A pull request (PR) will be raised to merge the feature branch into dev.
- This PR will require approval from the Data Engineering (DE) team.
- After the changes are merged into the dev branch:
- Github hooks will automatically sync the AWS-dev/stg AWS account's S3 bucket with the latest changes from the Git repository.
- Developers can then run and test jobs in the dev environment.
- After testing is complete:
- A new PR will be raised to merge changes from dev into main.
- This PR will also require approval from the DE team.
- Once approved and merged into main, the changes will automatically sync to the S3 bucket in the prod AWS account.
Conclusion
Together, dbt, Snowflake, and Airflow build a scalable, automated, and reliable ETL pipeline that addresses the major challenges of data quality, lineage, and testing. Furthermore, it allows integration with CI/CD to enable versioning, automated testing, and deployment without pain, leading to a strong and repeatable data workflow. That makes this architecture easy to operate while reducing manual work and improving data reliability all around.
Opinions expressed by DZone contributors are their own.
Comments