Deep Learning Fraud Detection With AWS SageMaker and Glue
Utilizing AWS SageMaker and Glue to create a fraud detection system using ETL, deep learning, and XGBoost for scalable, efficient, and accurate results.
Join the DZone community and get the full member experience.
Join For FreeFraud detection has become a top priority for businesses across industries. With fraudulent activities growing more sophisticated, traditional rule-based approaches often fall short in addressing the constantly evolving threats. Detecting and preventing fraud — be it financial scams, identity theft, or insurance fraud — is crucial, especially when global fraud losses run into billions of dollars annually.
This guide discusses how deep learning can improve fraud detection with AWS SageMaker and AWS Glue. Deep learning, a branch of machine learning, excels at uncovering complex patterns in large datasets and adapting to emerging fraud techniques. AWS SageMaker, a comprehensive machine learning platform, equips businesses with the tools to build, train, and deploy advanced deep learning models, while AWS Glue streamlines data preparation and integration with its fully managed ETL capabilities.
Together, these AWS services enable organizations to create end-to-end fraud detection pipelines that are robust, scalable, and seamlessly fit within existing data ecosystems. In this document, I'll walk you through the process of developing a powerful fraud detection system using deep learning on AWS. We'll cover best practices, common challenges, and real-world applications to help you build an efficient and future-ready solution.
AWS SageMaker for Deep Learning With XGBoost
AWS SageMaker offers a powerful platform for developing machine learning models, and when it comes to fraud detection, XGBoost (Extreme Gradient Boosting) stands out as a particularly effective algorithm. Let's dive into how SageMaker and XGBoost work together to create robust fraud detection systems.
XGBoost on AWS SageMaker is a popular machine learning algorithm known for its speed and performance, especially in fraud detection scenarios. SageMaker provides a built-in XGBoost algorithm optimized for the AWS ecosystem.
- High accuracy. XGBoost often outperforms other algorithms in binary classification tasks like fraud detection.
- Handles imbalanced data. Fraud cases are typically rare, and XGBoost can handle this imbalance effectively.
- Feature importance. XGBoost provides insights into which features are most crucial for detecting fraud.
- Scalability. SageMaker's implementation can handle large datasets efficiently.
Architecture
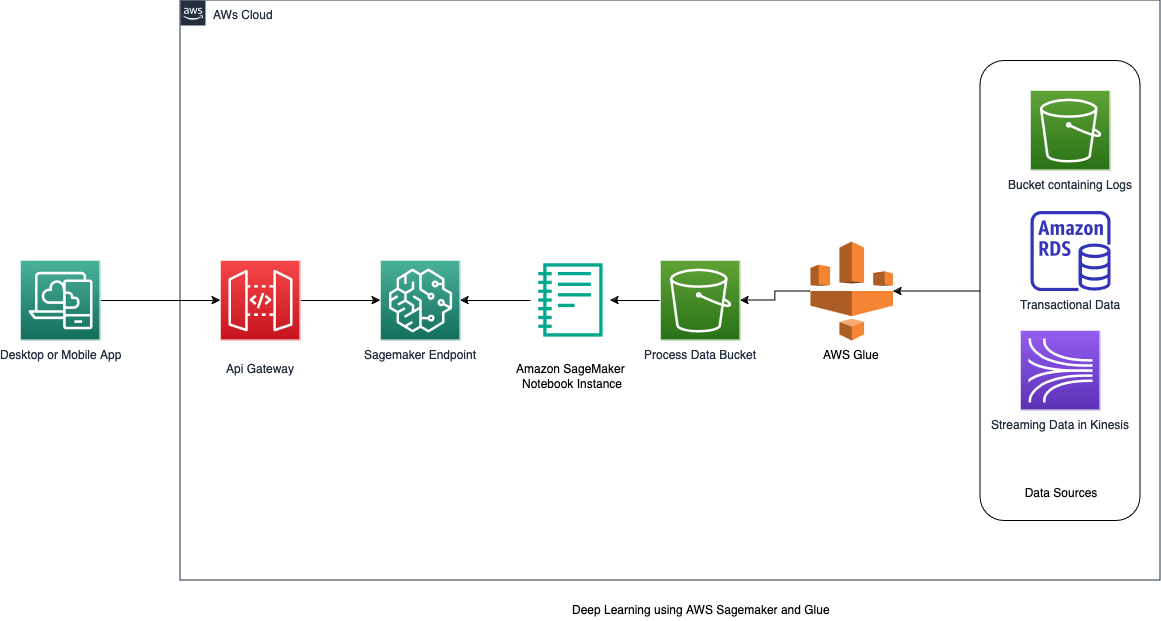
- Data sources – Various input streams, including transactional databases, log files, and real-time data feeds that provide raw information for fraud detection.
- AWS Glue – A fully managed ETL (Extract, Transform, Load) service that catalogs your data, cleans it, enriches it, and moves it reliably between various data stores and data streams.
- Amazon S3 (processed data) – Highly scalable object storage service that stores both the processed data from Glue and the model artifacts from SageMaker.
- AWS SageMaker (XGBoost Model) – A fully managed machine learning platform that will be leveraged to build, train, and deploy the XGBoost machine learning model.
- Sagemaker endpoints – A scalable compute environment for deploying the model for real-time fraud detection.
- API Gateway – Acts as a protection layer in front of the model deployed in the SageMaker endpoint. It helps secure calls, track requests, and manage model deployments with minimal impact on the consuming application.
- Fraud detection application – A custom application or serverless function that integrates the deployed model into the business workflow, making fraud predictions on new transactions.
Implementation
Here is the small snippet of the data that I am considering for training the ML model in CSV format. The data has the following columns
transaction_id– Unique identifier for each transactioncustomer_id– Identifier for the customer making the transactionmerchant_id– Identifier for the merchant receiving the paymentcard_type– Type of card used (credit or debit)amount– Transaction amounttransaction_date– Date and time of the transactionis_fraud– Binary indicator of whether the transaction is fraudulent (1) or not (0)
| transaction_id | customer_id | merchant_id | card_type | amount | transaction_date | is_fraud |
|---|---|---|---|---|---|---|
| 1001 | C5678 | M345 | credit | 123.45 | 2023-04-15 09:30:15 |
0 |
| 1002 | C8901 | M567 | debit | 45.67 | 2023-04-15 10:15:22 |
0 |
| 1003 | C2345 | M789 | credit | 789.01 | 2023-04-15 11:45:30 |
1 |
| 1004 | C6789 | M123 | credit | 56.78 | 2023-04-15 13:20:45 |
0 |
| 1005 | C3456 | M234 | debit | 234.56 | 2023-04-15 14:55:10 |
0 |
| 1006 | C9012 | M456 | credit | 1234.56 | 2023-04-15 16:30:05 |
1 |
| 1007 | C4567 | M678 | debit | 23.45 | 2023-04-15 17:45:30 |
0 |
| 1008 | C7890 | M890 | credit | 345.67 | 2023-04-15 19:10:20 |
0 |
| 1009 | C1234 | M012 | credit | 567.89 | 2023-04-15 20:25:15 |
0 |
| 1010 | C5678 | M345 | debit | 12.34 | 2023-04-15 21:40:55 |
0 |
The Glue ETL script in Pyspark below demonstrates how I processed and prepared data for fraud detection using XGBoost in SageMaker. I am using transactional data and performing some basic data cleaning and feature engineering.
Remember to replace the bucket name in the code snippet below. Also, the source database and table names are as configured in the Glue Crawler:
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from pyspark.sql.functions import col, when, to_timestamp, hour, dayofweek
# Initialize the Glue context
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
# Read input data
datasource0 = glueContext.create_dynamic_frame.from_catalog(
database = "fraud_detection_db", # Database name configured in the glue crawler
table_name = "raw_transactions" # Table name configured in the glue crawler
)
# Convert to DataFrame for easier manipulation
df = datasource0.toDF()
# Data cleaning
df = df.dropDuplicates().na.drop()
# Feature engineering
df = df.withColumn("amount", col("amount").cast("double"))
df = df.withColumn("timestamp", to_timestamp(col("transaction_date"), "yyyy-MM-dd HH:mm:ss"))
df = df.withColumn("hour_of_day", hour(col("timestamp")))
df = df.withColumn("day_of_week", dayofweek(col("timestamp")))
# Encode categorical variables
df = df.withColumn("card_type_encoded", when(col("card_type") == "credit", 1).otherwise(0))
# Calculate statistical features
df = df.withColumn("amount_zscore",
(col("amount") - df.select(mean("amount")).collect()[0][0]) / df.select(stddev("amount")).collect()[0][0]
)
# Select final features for model training
final_df = df.select(
"transaction_id",
"amount",
"amount_zscore",
"hour_of_day",
"day_of_week",
"card_type_encoded",
"is_fraud" # this is my target variable
)
# Write the processed data back to S3
output_dir = "s3://<bucket_name>/processed_transactions/"
glueContext.write_dynamic_frame.from_options(
frame = DynamicFrame.fromDF(final_df, glueContext, "final_df"),
connection_type = "s3",
connection_options = {"path": output_dir},
format = "parquet"
)
job.commit()Now, once the processed data is stored in S3, the next step will be to use Sagemaker Jupyter Notebook to train the model. Again, remember to replace your bucket name in the code.
import boto3
import sagemaker
from sagemaker import get_execution_role
from sagemaker.amazon.amazon_estimator import get_image_uri
from sagemaker.session import Session
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# Set up the SageMaker session
role = get_execution_role()
session = sagemaker.Session()
bucket = session.default_bucket()
prefix = 'fraud-detection-xgboost'
# Specify the S3 location of your processed data
s3_data_path = 's3://<bucket_name> /processed_transactions/'
# Read the data from S3
df = pd.read_parquet(s3_data_path)
# Split features and target
X = df.drop('is_fraud', axis=1)
y = df['is_fraud']
# Split the data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Scale the features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Combine features and target for SageMaker
train_data = pd.concat([pd.DataFrame(X_train_scaled), y_train.reset_index(drop=True)], axis=1)
test_data = pd.concat([pd.DataFrame(X_test_scaled), y_test.reset_index(drop=True)], axis=1)
# Save the data to S3
train_path = session.upload_data(path=train_data.to_csv(index=False, header=False),
bucket=bucket,
key_prefix=f'{prefix}/train')
test_path = session.upload_data(path=test_data.to_csv(index=False, header=False),
bucket=bucket,
key_prefix=f'{prefix}/test')
# Set up the XGBoost estimator
container = get_image_uri(session.boto_region_name, 'xgboost', '1.0-1')
xgb = sagemaker.estimator.Estimator(container,
role,
instance_count=1,
instance_type='ml.m5.xlarge',
output_path=f's3://<bucket_name>}/{prefix}/output',
sagemaker_session=session)
# Set hyperparameters
xgb.set_hyperparameters(max_depth=5,
eta=0.2,
gamma=4,
min_child_weight=6,
subsample=0.8,
objective='binary:logistic',
num_round=100)
# Train the model
xgb.fit({'train': train_path, 'validation': test_path})
# Deploy the model
xgb_predictor = xgb.deploy(initial_instance_count=1, instance_type='ml.m4.xlarge')
# Test the deployed model
test_data_np = test_data.drop('is_fraud', axis=1).values.astype('float32')
predictions = xgb_predictor.predict(test_data_np)
# Evaluate the model
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
y_pred = [1 if p > 0.5 else 0 for p in predictions]
print(f"Accuracy: {accuracy_score(y_test, y_pred)}")
print(f"Precision: {precision_score(y_test, y_pred)}")
print(f"Recall: {recall_score(y_test, y_pred)}")
print(f"F1 Score: {f1_score(y_test, y_pred)}")
# Clean up
xgb_predictor.delete_endpoint()Result
Here is the output of the test run on the model.
Accuracy: 0.9982
Precision: 0.9573
Recall: 0.8692
F1 Score: 0.9112Let me break down what these metrics mean in the context of fraud detection:
- Accuracy: 0.9982 (99.82%) – This high accuracy might look impressive, but in fraud detection, it can be misleading due to class imbalance. Most transactions are not fraudulent, so even always predicting "not fraud" could give high accuracy.
- Precision: 0.9573 (95.73%) – This indicates that when the model predicts a transaction is fraudulent, it's correct 95.73% of the time. High precision is important to minimize false positives, which could lead to legitimate transactions being blocked.
- Recall: 0.8692 (86.92%) – This shows that the model correctly identifies 86.92% of all actual fraudulent transactions. While not as high as precision, it's still good. In fraud detection, we often prioritize recall to catch as many fraudulent transactions as possible.
- F1 Score: 0.9112 – This is the harmonic mean of precision and recall, providing a balanced measure of the model's performance. An F1 score of 0.9112 indicates a good balance between precision and recall.
These metrics suggest a well-performing model that's good at identifying fraudulent transactions while minimizing false alarms. However, there's always room for improvement, especially in recall.
In a real-world scenario, you might want to adjust the model's threshold to increase recall, potentially at the cost of some precision, depending on the specific business requirements and the cost associated with false positives versus false negatives.
Conclusion
The implementation of a deep learning-based fraud detection system using AWS SageMaker and Glue represents a significant leap forward in the fight against financial fraud. Using XGBoost algorithms and the scalability of cloud computing, businesses can now detect and prevent fraudulent activities with unprecedented accuracy and efficiency.
Throughout this document, we've explored the intricate process of building such a system, from data preparation with AWS Glue to model training and deployment with SageMaker. The architecture we've outlined has shown how the combination of AWS SageMaker, Glue, and XGBoost offers a formidable weapon in the arsenal against fraud.
Opinions expressed by DZone contributors are their own.
Comments