Demystifying Generative Text AI
An easy introduction to generative text ai with animated images, covering artificial neural networks, word representation, generative text AI and ChatGPT specifics.
Join the DZone community and get the full member experience.
Join For FreeWhen I first planned to start this blog, I had in mind to talk about my personal views on generative language technology. However, after sending my first draft to friends, family, and colleagues, it soon became clear that some background information about generative text AI itself was needed first.
So, my first challenge is to offer an introduction and simple explanation about generative text AI.
This is for all the folks who are flabbergasted by the wonder of generative text AI and wonder how and where the magic happens. Warning: if you’re not genuinely interested in it, this will be boring.
Xavier, let's go.
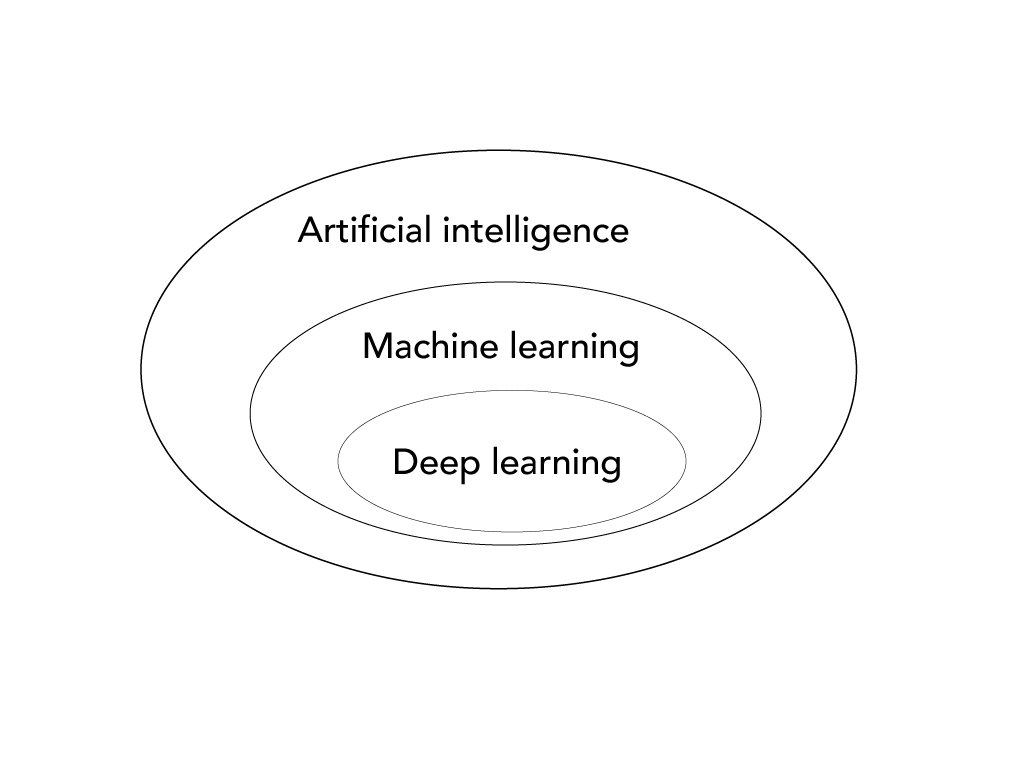
What Is Artificial Intelligence, What Is Machine Learning, and What Is Deep Learning?
Artificial intelligence is the broader concept of machines being able to perform tasks that would require human intelligence. It’s just a computer program doing something intelligent. A system that uses if-then-else rules in order to make a decision is also artificial intelligence. If you build a loan expert system consisting of thousands of rules like “if spends more on coffee than on groceries, less chance to get a loan” or “if hides his/her online shopping from his/her significant other, less chance for the loan” to decide whether you get a loan, that system belongs to the artificial intelligence domain. These programs (although with slightly better rules) have already been around for 50+ years. Artificial intelligence is not something new.
Machine learning is the subset of AI that involves the use of algorithms and statistics to enable systems to learn from and make predictions by themselves. Simply put, it is a way for computers to learn how to do things by themselves without being specifically programmed to do so. Without a human expert specifying all the domain knowledge like “if borrows money from parents to pay for Netflix subscription, less chance for a loan.” The system figures out what to do based on examples. Again, these — and even popular current approaches like neural networks — have already been around for 50+ years, although largely in academic settings.
Deep learning is the subset of machine learning that is usually associated with the use of (deep) artificial neural networks — the most popular approach to machine learning. We’ll explain artificial neural networks in the next section, but for now, think of them as computer system that tries to work like our brains. Just like our brains have lots of little cells called neurons that work together to help us think and learn, an artificial neural network has lots of nodes that work together to solve problems. The term “deep” refers to the depth of these networks — the reason why they appear more and more in the media, and real use cases are that to make them work well, they need a lot of nodes and layers (hence, the term “deep”), which in turn requires a lot of data and computational power. What ended the previous AI winter (=a period without major breakthroughs in AI) is mostly the fact that we have more data and computational power now. Some recent important algorithmic advances enhanced a new spring in the AI seasons, though with the data and computational power of 20 years ago, (almost) no impressive machine learning system would be used in a real product today. These neural networks can figure out things like “if a person has a pet rock, wears a tutu to work, speaks only in rhymes, is allergic to money, has a fear of banks, but has initial influencer success, get more chance for a loan” but then even a thousand or million-fold more complex and without the possibility of the deep net explaining itself in a way that’s interpretable by us humans.
Xavier, next time I’ll leave it up to you to make the text more interesting to read.
The link between AI, ML, and DL is represented like this in a Venn diagram:
What Are Artificial Neural Networks?
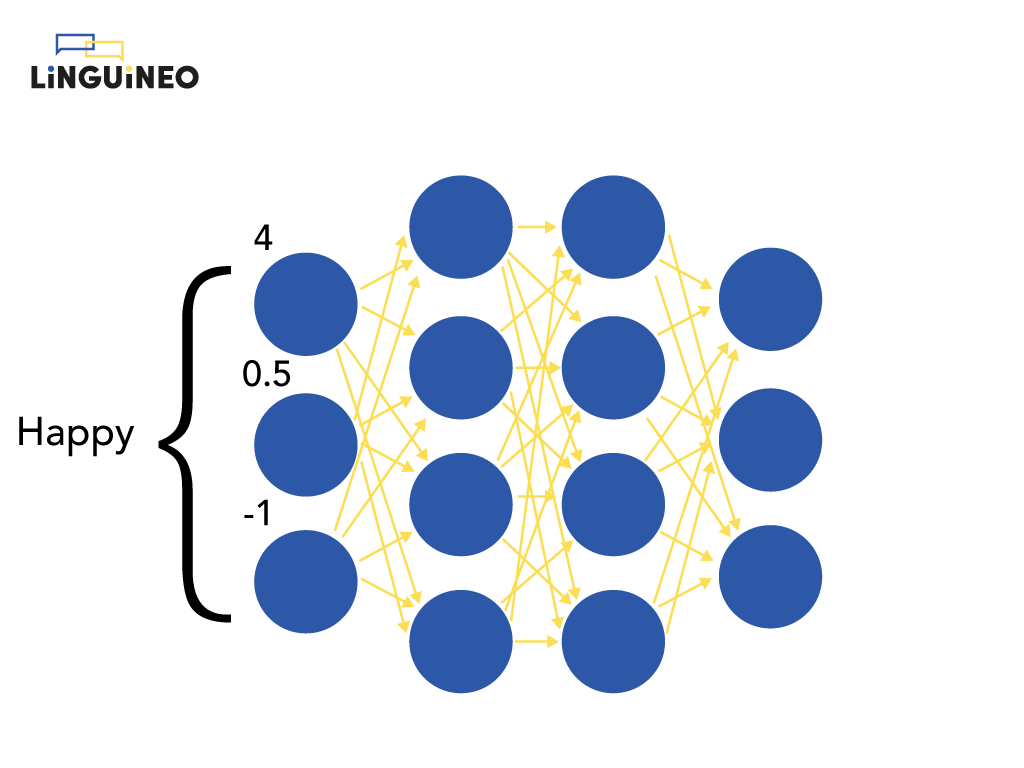
In this blog, we will often talk about generative text AI. Since each performant generative text, AI belongs to the deep learning domain; this means we need to talk about artificial neural networks. Artificial neural networks (ANNs) are a type of machine learning model that are inspired by the human brain. They consist of layers of interconnected nodes or “neurons”:
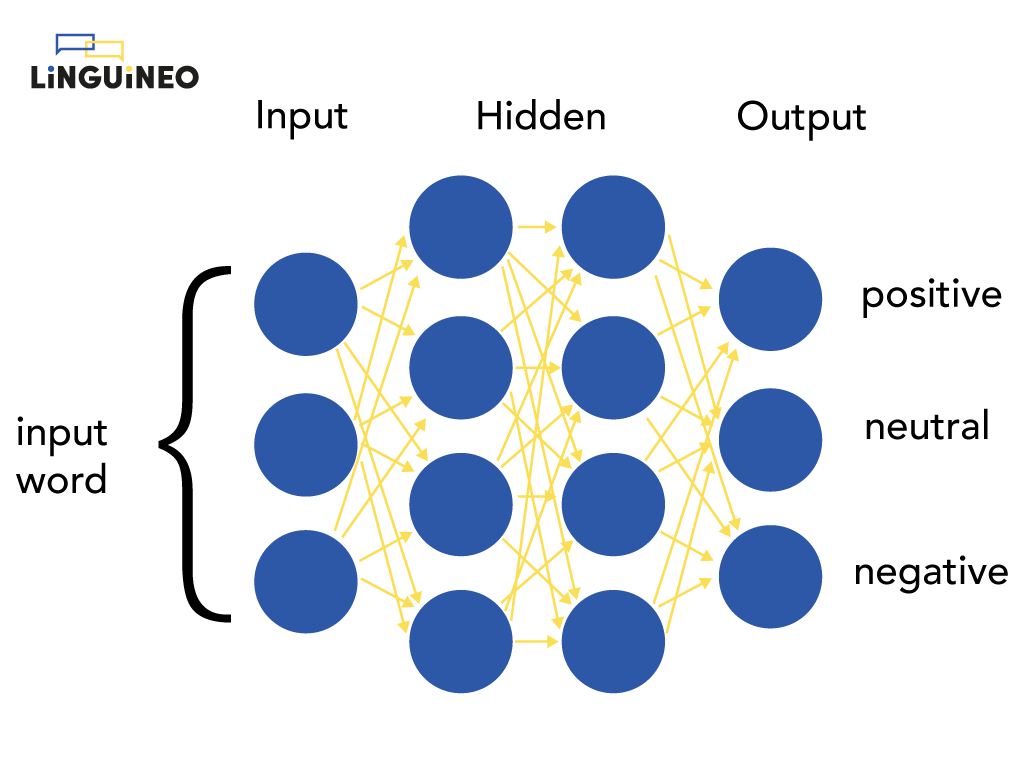
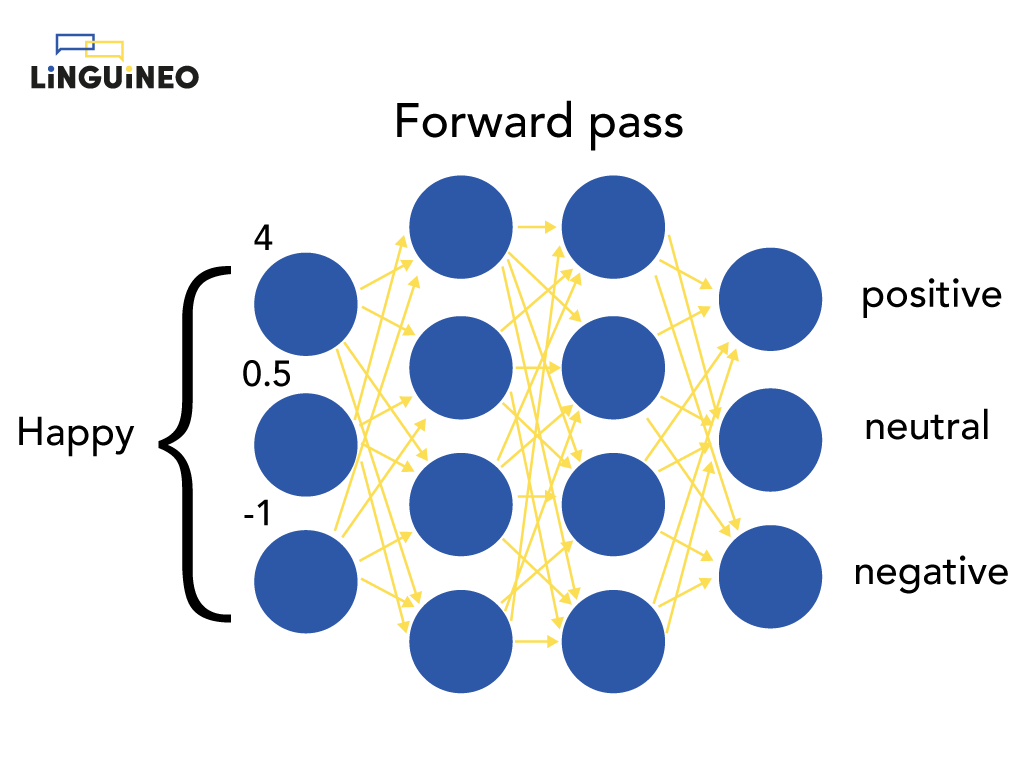
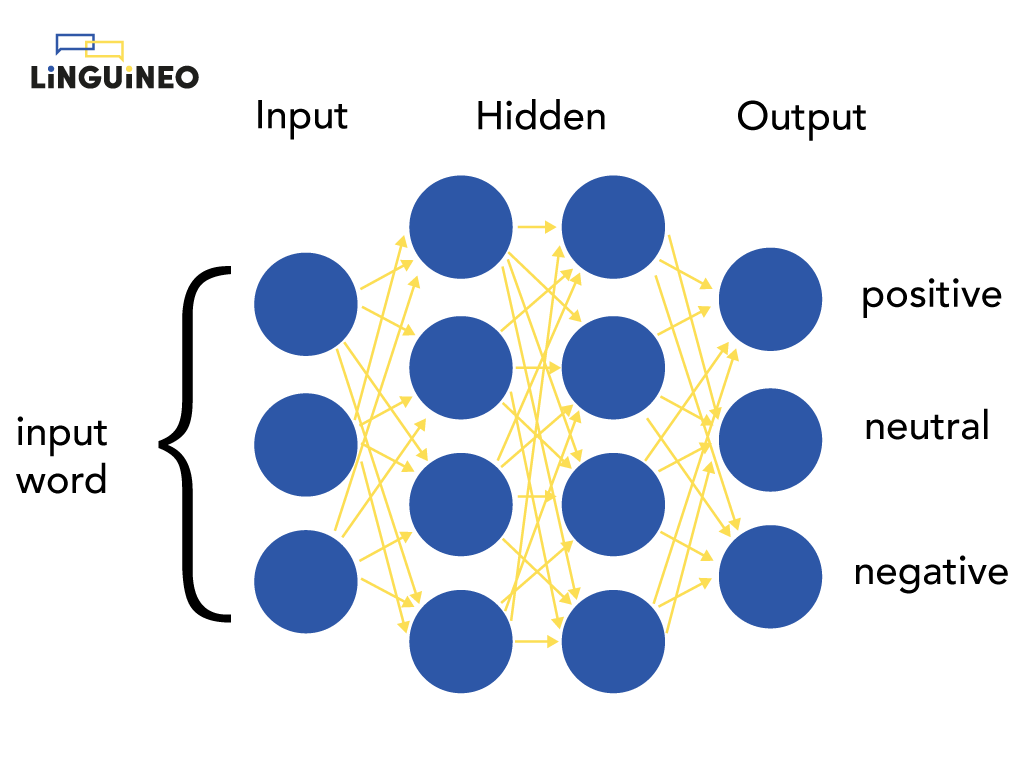
The neural network on the picture determines for a word whether it has a positive, neutral, or negative connotation. It has 1 input layer (that accepts the input word), 2 hidden layers (=the layers in the middle), and 1 output layer (that returns the output).
A neural network makes predictions by processing and transmitting numbers to each next layer. The input word is transmitted to the nodes of the first hidden layer, where some new numbers are calculated that are passed to the next layer. To calculate these numbers, the weights of each connection are multiplied with the input values of each connection, after which another function (like sigmoid in the example) is applied to keep the passed numbers in a specific range. It is these weights that steer the calculations. Finally, the numbers calculated by the last hidden layer are transmitted to the output layer and determine what the output is. For our example, the end result is 0.81 for positive, 0.02 for negative, and 0.19 for neutral, indicating that the neural network predicts this word should be classified as positive (since 0.81 is the highest):
Technical Notes for Xavier
In the above animation, we do not explain why we represent the word “happy” with the numbers [4, 0.5, -1] in the input layer. We just ignore how to represent a word to the network for now — the important thing to get is the word is represented to the network as numbers. We will cover later how we represent a word as numbers.
Also, the ANN above returns a probability distribution. ANNs almost always work like this. They never say, “This is the exact output”; it is almost always a probability over all (or a lot of) the different options.
Training a Neural Network
How does the neural network know which calculations to perform in order to achieve a correct prediction? We can’t easily make up any rules or do calculations in some traditional way to end up with a correct probability distribution (when working with unstructured data such as a piece of text, an audio fragment, or an image).
Well, the weights of the first version of a neural network are actually entirely wrong. They are initialized randomly. But by processing example after example and using an algorithm called backpropagation, it knows how to adjust its weights to get closer and closer to an accurate solution.
This process is also called the training of the neural network. In order for this to work, the network needs to know the correct output value for each training example. Without it, it couldn’t calculate its error and never adapt its weights towards the correct solution. So, for our example above, we need (word -> classification) pairs as training data, like (happy: positive = 1; neutral = 0, negative = 0), to feed to the network during training. For other ANNS, this will be something different. For speech recognition, for example, this would be (speech fragment -> correctly transcribed text) pairs.
If you need to have this training data anyway, why do you still need the neural network? Can’t you just do a lookup on the training data? For the examples you have, you can do such a lookup, but for most problems for which ANNs are used, no example is ever unique, and it is not feasible to collect the training data for all possible inputs. The point is that it learns to model the problem in its neurons, and it learns to generalize, so it can deal with inputs it didn’t see at training time too.
Small, Big, or Huge AI Models
You will hear people talk about small, big, or huge AI models.
This size of an AI model refers to the number of parameters an artificial neural network has. A parameter is really just one of the weights you saw before (note for the purists: we are omitting the bias parameters here, and we are also not covering the hyperparameters of the network, which is something entirely different). Small ANN student assignments involve neural networks with only a few parameters. Many production language-related ANNs have about 100M parameters. The OpenAI GPT3 model reportedly has 175 billion parameters.
The number of parameters is directly linked to the computational power you need and what the ANN can learn. The more parameters, the more computation power you need, and the more different things your ANN can learn. Especially the GPT3-model’s size spans the crown: to store the parameters alone, you need 350 GB! To store all the textual data of Wikipedia, you only need 50GB. This gives a sense of its ability to store detailed data, but it also gives an impression of how much computational power it needs compared to other models.
Transfer Learning
A popular thing to do — in the AI community (haha, Xavier, I preempted you there!) — is to use transfer learning:
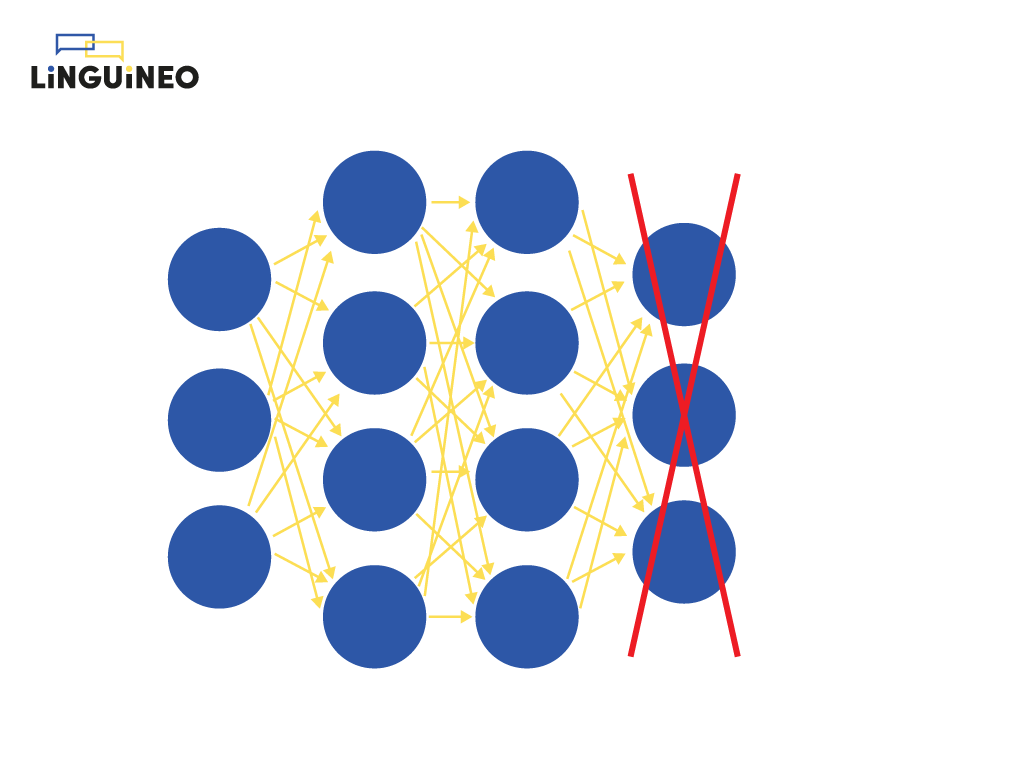
To understand how transfer learning works, you can think of the first hidden layers of an ANN as containing more general info for solving your problems. For language models, the first layers could represent more coarse features, such as individual words and syntax, while later layers learn higher-level features like semantic meaning, contextual information, and relationships between words. By only removing the last layers of the network, you can use the same network for different tasks without having to retrain the entire network.
This means that larger models can be retrained for a particular task or domain by only retraining only the last layers, which is much less computationally expensive and requires, in general, much less training data (often, a few thousand training samples are enough as opposed to millions). This makes it possible for smaller companies or research teams with less budget to do stuff with large models and democratizes AI models to a wider public (since the base models are usually extremely expensive to train).
How Are Words Represented in Generative Text AI?
In the article about artificial neural networks, we gave some high-level representation of what such a neural network is. The deeper you dig into these neural networks, the more details you encounter, like why it often makes sense to prune nodes or that there are several kinds of neurons, some of which keep different “states.” Or that there are even very different kinds of neural network layers and complex architectures consisting of multiple neural networks communicating with each other. But we will just focus on one question now, specifically for language-related ANNs.
Let’s get back to the neural network we talked about before:
In the example with the calculations, we presented the input word “happy” as [4, 0.5, -1] to demonstrate how a neural network works. Of course, this representation of the word happy was entirely made up and wouldn’t work in a real setting. So then, how do we represent a word?
1. Naive Approach: Take No Semantic Information Into Account
A natural reflex would be: what kind of question is that? By its letters, of course. You represent the word “word” with “word.” Simple! Well, it’s not. A machine only understands numbers, so we need to convert words into numbers. So, what is a good way to do this?
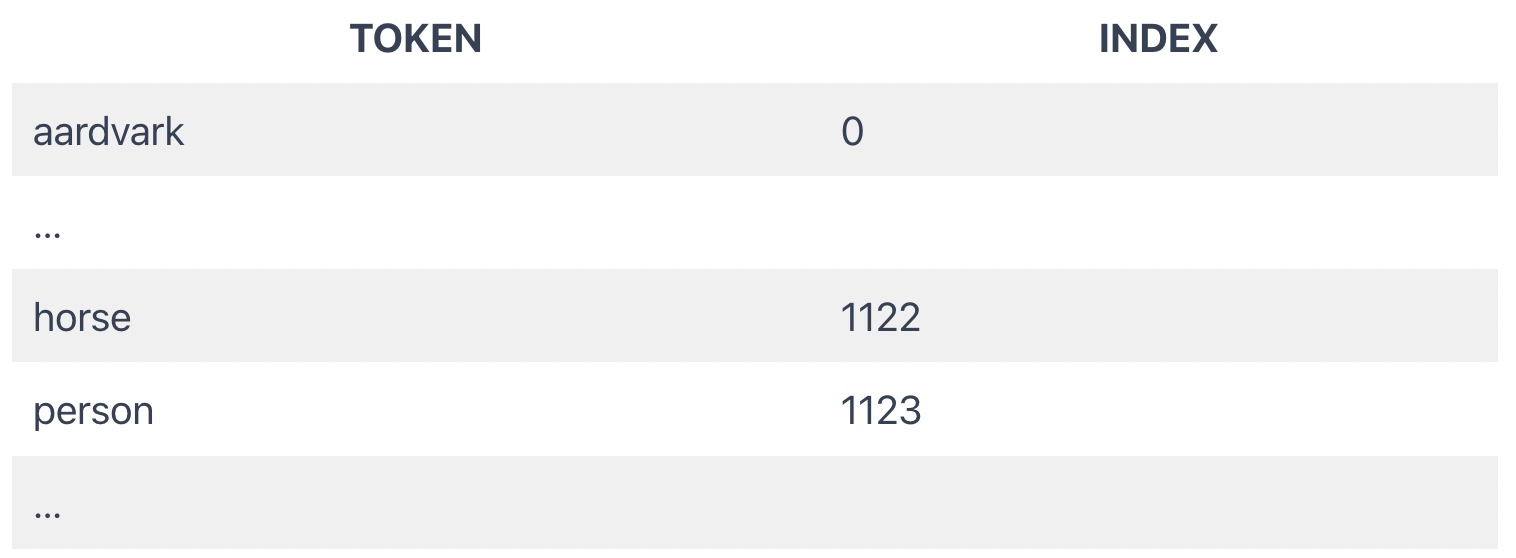
To convert a word to numbers, a naive approach is to create a dictionary with each known word (or word part) and give each word a unique number. The word “horse” could be number 1122, and the word “person” could be number 1123.
Technical Note for Xavier
I’m taking a shortcut here: you actually need to convert the actual numbers to their one hot vector encodings first in order for this approach to work. Otherwise, a relationship between words or letters is created that is just not there, e.g., “person” almost being the same as “horse” because their numbers are almost the same.
For many problems, such as predicting the next word or translating the next word in a sentence, it turns out the above approach does not work well. The important piece of the puzzle here is that this approach fundamentally lacks the ability to relate words to each other in a semantic way.
2. Better Approach: Take Static Semantic Information Into Account
Let’s consider the words “queen” and “king.” These words are very similar semantically — they basically mean the same thing except for gender. But in our approach above, the words would be entirely unrelated to each other. This means that whatever our neural network learns for the word “queen,” it will need to learn again for the word “king.”
But we know words share many characteristics with other words — it doesn’t make sense to treat them as entirely separate entities. They might be synonyms or opposites, belong to the same semantic domain, and have the same grammatical category… Seeing each word as a standalone unit, or even just as the combination of its letters, is not the way to go — it certainly isn’t how a human would approach it. What we need is a numeric semantic representation that takes all these relations into account.
How Do We Get Such Semantic Word Representations?
The answer is: with an algorithm that’s based on which words appear together in a huge set of sentences. The details of it don’t matter. If you want to know more, read about Word2Vec and GloVe, and word embeddings. Using this approach, we get semantic representations of a word that capture its (static) meaning.
The simplified representations could be:
Queen: [-0.43 0.57 0.12 0.48 0.63 0.93 0.01 … 0.44]
King: [-0.43 0.57 0.12 0.48 -0.57 -0.91 0.01 … 0.44]
As you may notice, this representation of both words is the same (they share the same numbers), except for the fifth and sixth values, which might be linked to the different gender of the words.
Technical Note for Xavier
Again we are simplifying — in reality, the embeddings of 2 such related words are very similar but never identical since the training of an AI system never produces perfect results. The values are also never humanly readable; you can think of each number representing something like gender, word type, or domain,…but when they are trained by a machine, it is much more likely the machine comes up with characteristics that are not humanly readable, or that a human-readable one is spread over multiple values.
It turns out that for tasks in which semantic meaning is important (such as predicting or translating the next word), capturing such semantic relationships between words is of vital importance. It is an essential ingredient to make tasks like “next word prediction” and “masked language modeling” work well.
Although there are many more semantic tasks, I’m mentioning “next-word prediction” and “masked language modeling” here because they are the primary tasks most generative text ai models are trained for.
“Next word prediction” is the task of predicting the most likely word after a given phrase. For example, for the given phrase “I am writing a blog,” such a system would output a probability distribution over all possible next word (parts) in which “article,” “about,” or “.” are probably all very probable.
“Masked language modelling” is a similar task, but instead of predicting the next word, the most likely word in the middle of a sentence is predicted. For a phrase like “I am writing an <MASK> article.” it would return a probability distribution over all possible words at the <MASK> position.
Technical Note for Xavier
These word embeddings are a great starting point to get your hands dirty with language-related machine learning. Training them is easy — you don’t need tons of computational power or a lot of annotated data.
They are also relatively special in the sense that when training them, the actual output that is used is the weights, not the output of the trained network itself. This helps to get some deeper intuition on what ANN weights and their activations are.
They also have many practical and fun applications. You can use them to query for synonyms for another word or for a list of words for a particular domain. By training them yourself on extra texts, you can control which words are known within the embeddings and, for example, add low frequent or local words (very similar words have very similar embeddings). They can also be asked questions like “man is to computer programmer what woman is to …” Unfortunately, their answer, in this case, is likely to be something like “housewife.” So, they usually contain a lot of bias. But it can be shown you can actually remove that bias once it is found, despite word embeddings being unreadable by themselves.
3. Best Approach: Take Contextual Semantic Information Into Account
However, this is not the end of it. We need to take the representation one step further. These static semantic embeddings we now have for each word are great, but we are still missing something essential: each word actually means something slightly different in each sentence.
A clear example of this is the sentences “The rabbit knew it had to flee from the fox” and “The fox knew it could attack the rabbit.” The same word “it” refers to 2 completely different things: one time the fox, one time the rabbit, and it’s, in both cases, essential info.
Although “it” is an easy-to-understand example, the same is true for each word in a sentence, which is a bit more difficult to understand. It turns out that modeling the relationship of each word with all the other words in a sentence gives much better results. And our semantic embeddings do not model relationships like that – they don’t “look around” to the other words.
So, we do not only need to capture the “always true” relationships between words, such as that king is the male version of the queen, but also the relationships between words in the exact sentences we use them in. The first way to capture such relationships was to use a special kind of neural network — recurrent neural networks — but the current state-of-the-art approach to this is using a transformer, which has an encoder that gives us contextual embeddings (that are based on the static ones) as opposed to the non-contextual ones we discussed in the previous section.
This approach — first described in the well-referenced paper “Attention is all you need” — was probably the most important breakthrough for GPT3, ChatGPT, and GPT4 to work as well as they do today.
Moving from a static semantic word representation to a contextual semantic word representation was the last remaining part of the puzzle when it comes down to representing a word to the machine.
What Is Generative Text AI?
Generative text AI is AI — an ANN, either a recurrent neural network or a transformer – that produces continuous text. Usually, the general base task on which these systems are trained is “next word prediction,” but it can be anything. Translating a text, paraphrasing a text, correcting a text, making a text easier to read, predicting what came before instead of after…
Oversimplified, generative text AI is next-word prediction. When you enter a prompt in ChatGPT or GPT4, like “Write me a story about generative text AI.” it generates the requested story by predicting word after word.
Technical Note for Xavier
To make generative AI work well, <START> and <END> tokens are usually added to the training data to teach them to determine the beginning and ends of something. Recent models also incorporate human feedback on top to be more truthful and possibly less harmful. And on top of next-word prediction, in-between word prediction or previous-word prediction can also be trained. But disregarding the bit more complex architectures and other options, these systems are always just predicting word after word without any added reasoning on top whatsoever.
The basic idea behind generative text AI is to train the model on a large dataset of text, such as books, articles, or websites, to make it predict the next word. We don’t need labeled data for this since the “next word” is always available in the sentences of the texts themselves. When we don’t need human-labeled data, we talk about “unsupervised learning.” This has a huge advantage. Since there exist trillions of sentences available for training, access to “big data” is easy.
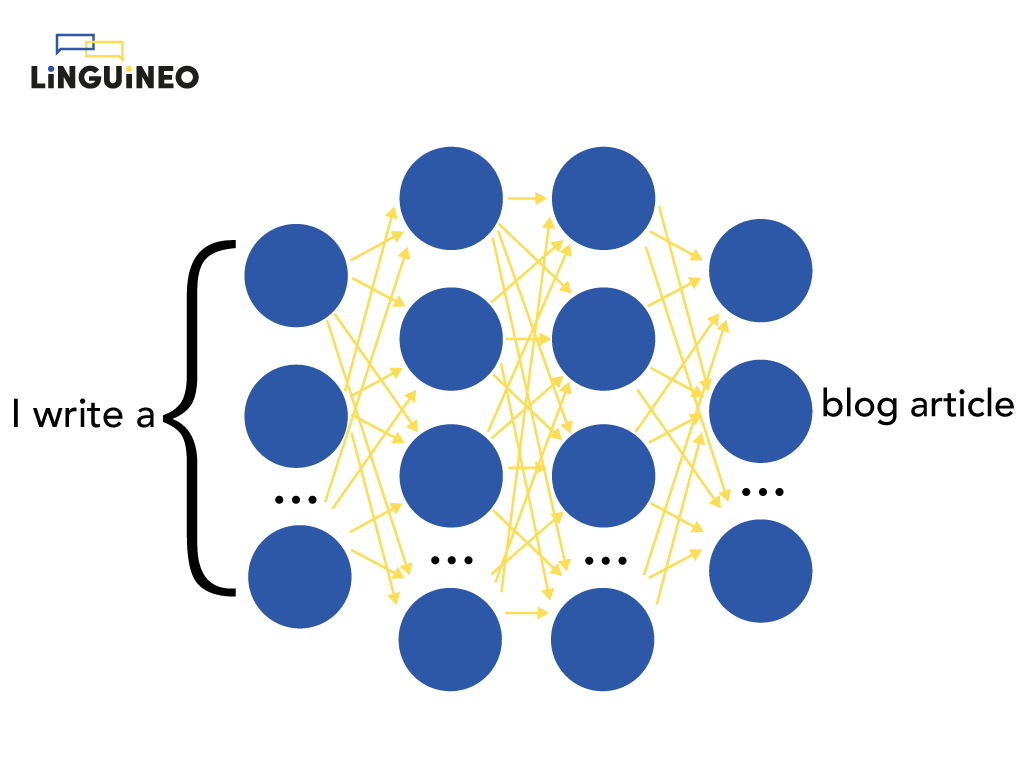
If we want to visualize such an ANN on a high level, it looks something like this:
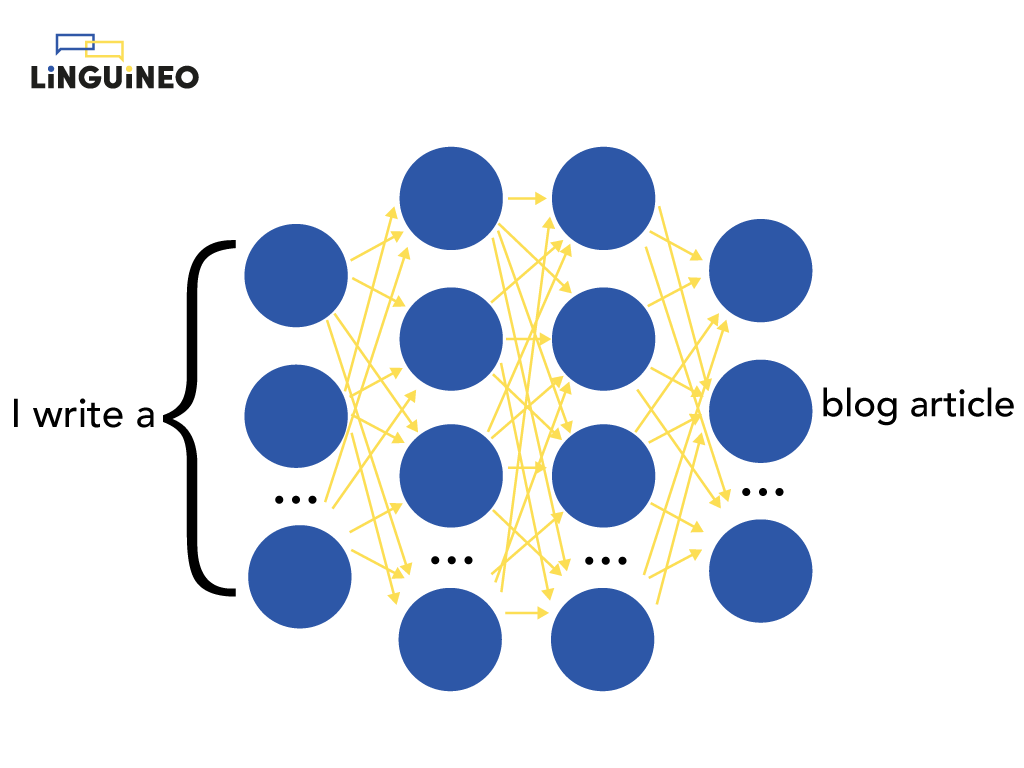
This is only a high-level representation. In reality, the most state-of-the-art architecture of these systems — the transformer — is quite complex. We already mentioned transformers in the previous section when we were talking about the encoder that produces the contextual embeddings. As we showed there, it is able to process text in a way that is much more complex and sophisticated than previous language models.
The intuition about it is that:
- By considering the surrounding words and sentences of a word, it is much better to understand the intended meaning
- It works in a “bidirectional” manner — it can understand how the words in a sentence relate to each other both forwards and backward, which can help it to better understand the overall meaning of a piece of text.
Technical Note for Xavier
This transformer architecture actually consists of both an encoder (e.g., “from static word embeddings to contextual embeddings”) and a decoder (e.g., “from contextual embeddings of the encoder and its own contextual embeddings to target task output”). The encoder is bidirectional, and the decoder is unidirectional (only looking at works that come after, not before). The explanation of this system is quite complex, and there are many variants that all use the concept of contextual semantic embeddings/self-attention. The GPT models are actually called "decoder-only" since they are only using the decoder part of a typical transformer, although "modified encoder only" would be a more suitable name imho. This video is a good explanation of Transformers — it’s one of the clearest videos explaining the current generative text AI breakthroughs. Following up on that, the blog article “The Illustrated Transformer” explains the transformer even more in-depth. And if you want to dig even deeper, this video explains how a transformer works at both training and inference times. Some more technical background is required for these, though.
The task a system like this learns is “next word prediction,” not “next entire phrase prediction.” It can only predict one word at a time. So, the ANN is run in different time steps, predicting the first next word first, then the second, and so on.
As we mentioned before, the output for each run is again a probability distribution. So, for instance, if you feed the ANN the sentence “I am working,” the next word with the highest probability could be “in,” but it could be closely followed by “at” or “on.” One option is selected, then.
Technical Notes for Xavier
This doesn’t really need to be the word with the highest probability — all implementations allow a configuration option to pick either the word with the highest probability or allow some freedom in this. Once the word is picked, the algorithm continues with predicting the next word. It goes on like this until a certain condition is met, like maximum tokens reached or something like a <STOP> token is encountered (which is a “word” the model learned at training time to know when to stop).
An important thing here to realize is the simplicity of the algorithm. The only thing it is really doing — albeit with “smart, meaningful word and in-sentence relationship representations” the transformer is providing — is predicting the next word given some input text (“the prompt”) based on a lot of statistics.
1 cool thing about this generative text AI is that it doesn’t necessarily need to predict the next word. You can just as easily train it for “previous word prediction” or “in-between word prediction” — something that would be much more difficult for humans. You could pass it “Hi, here is the final chapter of my book. Can you give me what comes before.” — it would work just as well as the other way around.

Is ChatGPT Just Using Next Word Prediction?
In the previous article, we explained how GPT itself (like GPT3 and GPT3.5) works, not ChatGPT (or GPT4). So, what’s the difference?
Base models for generative text AI are always trained on tasks like “next word prediction” (or “masked language modelling”). This is because the data to learn this task is abundant: namely, all the sentences we produce on a daily basis are accessible in Internet databases, documents, and webpages,.. they are everywhere. No labeling is necessary. This is of vital importance. There is no feasible way to get a training set of trillions of manually labeled examples.
But a task like “next word prediction” creates a capability vs. alignment problem. We literally train our model to predict the next word. Is this what we actually want or expect as a human? Most definitely not.
Let’s consider some examples.
What would be the next word for the prompt “What is the gender of a manager?” Since the base model was trained on different texts, many of which are decades old, we know for a fact that the training data contained a lot of bias relating to this question. Because of this, statistically, the output “male” will be much more probable than “female.”
Or let’s ask it for the next word for “The United States went to war with Liechtenstein.” Statistically, the most likely outputs after this “in” is year numbers, not “an” (as you would need to reach “an alternate universe”) or any other word. But since the task it got was to actually predict the statistically most likely word given the expectations of the data it was trained with, it’s doing an awesome job here if it outputs some year, no? 100% correct, 100% capable.
The problem is that we don’t really want it to predict the next most likely word. We want it to give a proper answer based on our human preferences. There is a clear divergence here between the way the model was trained and the way we want to use it. It’s inherently misaligned. Predicting the next word is not the same task as giving a truthful, harmless, helpful answer.
This is exactly what ChatGPT tries to fix, and it tries to do so by learning to mimic human preference.
In case you expect a big revelation now, like the thing learning to reason, or it somehow at least learning to reason about itself, you’re in for a disappointment: it’s actually just more of the same ANN stuff, but a little different.
Very briefly, an approach using transfer learning (see before) was developed in which the GPT3.5 model was finetuned to “learn which responses humans like based on human feedback.” As we said before, transfer learning means freezing the first layers of the neural network (in the case of GPT-3, this is almost the entire model since even finetuning the last 10B parameters is prohibitively expensive).
The first step was to create a finetuned model using standard transfer learning based on labeled data. A dataset of about 15 000 <prompt, ideal human response> pairs was created for this. This finetuned “model can already start outputting responses that are more favored by humans (more truthful, helpful, with the risk of being harmful) than the base model. Creating the dataset for this model, however, was already a huge task — for each prompt, a human needed to do some intellectual work to make sure the response could be considered an “ideal human response” or at least be close enough. The problem with this approach is that it doesn’t scale.
The second step then was to learn a reward model.
As we saw before, trained generative text AI outputs a probability distribution. So instead of asking it for the most probable next word, you can also ask it for the second most probable next word, or for the 10 most probable next words, or for 100 words that are probably enough given some threshold. You can sample it for as many responses to a prompt as you want.
To get a dataset to train this reward model, 4 to 9 possible responses to each prompt were sampled, and for each prompt, humans ordered these responses from least favorable to most favorable. This approach scales much better than humans writing ideal responses to prompts manually. The fact that they needed to order the responses might make the reward model a bit unclear, but the reward model is as you would expect: it just outputs a score on a “human preference scale” for each text: the higher, the more preferable. The reason why they asked people to order the responses instead of just assigning a score is that different humans always give different scores on such “free text,” and using ordering + something like an ELO system (e.g., a standardized ranking system) works much better to calculate a consistent score for a response than manually assigning a number when multiple humans are involved in the scoring.
In the third step, another fine-tuned model (finetuned from the model that was created in the first step) is created by using the reward model that is even better at outputting human-preferred responses.
Step 1 is only done once; steps 2 and 3 can be repeated iteratively to keep improving the model.
Using this transfer learning approach, we end up with a system — ChatGPT — that’s actually much better than the base model at creating responses preferred by humans that are indeed more truthful and less biased.
If you don’t get how this can work, the answer is in the embeddings again. This model has some kind of deep knowledge about concepts. So if we rank responses that contain a male/female bias consistently worse than ones without such bias, the model will actually see that pattern and apply it quite generally, and this bias will get quite successfully removed (except for cases where the output is entirely different, like, as part of a computer program).
Published at DZone with permission of Steffen Luypaert. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments