When One Giant Payload Must Serve Many Small Consumers: Designing a Scalable Fanout Service
This mismatch between large producers and small consumers is where systems fracture. The fix isn’t constraining producers or overloading consumers — it’s a fanout layer.
Join the DZone community and get the full member experience.
Join For FreeIn distributed systems, size is rarely just a number. A producer may generate a rich, hierarchical product object containing items, SKUs, GTINs, variants, attributes, and region-specific metadata. That object makes sense at the domain boundary. It represents a complete truth.
But downstream systems often don’t want the truth in its entirety. They want a slice of it — one SKU at a time, one variant per region, one entity per resource tier.
This mismatch between large upstream payloads and small downstream consumers is where systems either fracture or mature. The architectural response is not to constrain the producer or overload the consumers. It is to introduce a dedicated fanout layer.
The Shape of the Problem
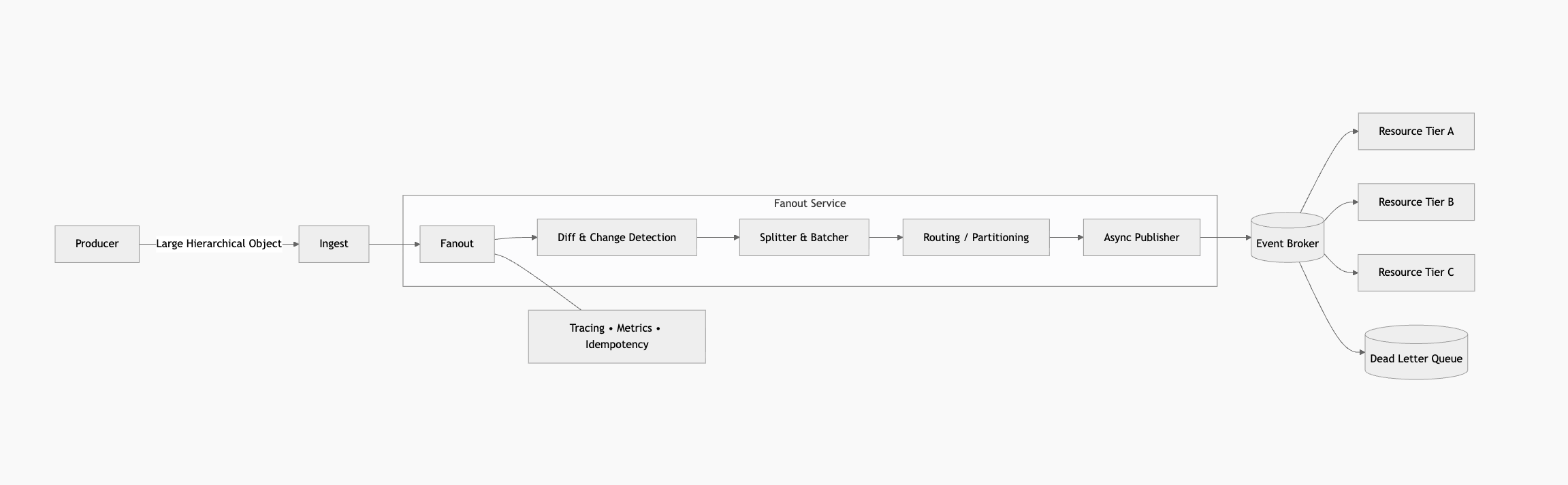
Imagine a producer emitting a deeply nested product object. Each update might include hundreds or thousands of sub-entities. Consumers, however, operate within bounded resource tiers. Some are optimized for small payloads. Others require strict ordering. Some scale horizontally; others are rate-limited by design. Sending the entire object downstream is inefficient and often dangerous. Large payloads increase broker pressure, amplify retries, and create cascading failure patterns when a single message becomes too heavy to process. The real requirement is more nuanced. Only meaningful changes should propagate. Only relevant sub-entities should be emitted. And the resulting messages must be small, predictable, and replay safe.This is precisely what a fanout service is built to do.
Introducing the Fanout Layer
The fanout service sits between producers and the event broker. It consumes the large hierarchical object, evaluates what has changed, decomposes it into smaller bounded units, and publishes those units to appropriate outbound topics or queues. Its responsibility is not transformation alone. It is normalization and protection. The first responsibility of this service is change detection. Rather than blindly re-emitting every sub-entity, it compares the previous state to the new state. Attribute changes, SKU additions, variant removals, region-level adjustments — these become the triggers for emission. Everything else remains silent.
This diff-first approach dramatically reduces unnecessary downstream load and prevents systems from reacting to noise.
Controlled Decomposition
Once changes are identified, the object must be split into safe, bounded messages. A common mistake is to flatten everything into a large batch and publish it as-is. That simply relocates the size problem.
Instead, the fanout service applies size constraints deliberately. It emits one SKU, one GTIN, or one variant per event — or groups them within defined batch limits. Payload size caps and entity count thresholds prevent accidental broker rejections and protect downstream services from unbounded memory consumption.
Importantly, splitting should happen before routing. Filtering early avoids Cartesian explosions where combinations multiply unnecessarily.
Decoupling With an Internal Queue
A resilient fanout service does not publish directly from the ingestion thread. Instead, it introduces an internal work queue. Once the object is split into discrete outbound tasks, those tasks are pushed into a durable queue processed by worker pools.
This design provides several benefits. It separates ingestion latency from publishing latency. It enables batching windows for throughput efficiency. It introduces natural backpressure controls. And it allows tier-specific rate limiting without impacting upstream producers.
In high-throughput environments, this internal queue becomes the stability buffer that prevents spikes from overwhelming the system.
Routing Across Resource Tiers
Not all consumers are equal. Some resource tiers require guaranteed ordering per SKU. Others prioritize throughput. Some need enriched payloads; others require minimal deltas.
The fanout service acts as a router. It may publish to a single topic with partitioning keys, allowing consumer groups to subscribe independently. Or it may publish to multiple outbound topics, one per resource tier, enabling isolated scaling and failure domains.
The choice depends on SLA boundaries and operational complexity, but the principle remains the same: routing is intentional, not accidental.
Idempotency and Safe Retries
Fanout multiplies messages. Multiplication increases retry risk.
Every outbound event should carry a deterministic idempotency key derived from stable identifiers and version metadata. This allows safe replay, protects downstream consumers from duplicate side effects, and ensures that retries during broker failures do not corrupt state.
Retries should use exponential backoff. Persistent failures should land in a dead letter queue with full context for replay and diagnosis.
Without idempotency, a fanout service becomes a duplication engine during outages.
Observability at Scale
One input object might generate thousands of outbound messages. If observability is weak, tracing that expansion becomes nearly impossible.
The fanout service must emit metrics for messages split per input, publish latency per tier, queue depth, error rates, and DLQ volumes. Distributed tracing should connect ingestion to every outbound publish so a single product update can be followed end-to-end.
Fanout systems are traffic multipliers. Observability must scale accordingly.
Architectural Value
A well-designed fanout service becomes more than a splitter. It becomes a boundary of control between domains.
Producers remain free to model rich hierarchical objects without worrying about downstream size constraints. Resource tiers remain stable and predictable, consuming only the units they can handle. Scaling becomes intentional rather than reactive.
Instead of forcing uniformity across services, the fanout layer embraces heterogeneity and manages it safely.
Final Thoughts
Distributed systems fail not only because of complexity but because of mismatch. A giant hierarchical payload and a small resource tier speak different dialects of scale.
The fanout service acts as the interpreter.
By detecting meaningful change, splitting responsibly, routing deliberately, and publishing safely, it turns a potentially fragile integration into a scalable pattern.
When one large truth must be shared across many small consumers, fanout is not an optimization. It is architecture.
Opinions expressed by DZone contributors are their own.
Comments