Designing Resilient Systems: What Every Engineering Manager Should Know
In this article, you'll learn how to build resilient systems through well-configured retries, circuit breakers, and bulkheads.
Join the DZone community and get the full member experience.
Join For FreeIntroduction: Why Resiliency Matters
If you've ever launched a major feature, only to watch it spectacularly break under pressure, you know exactly why resiliency matters. As a Software Development Manager (SDM) at Amazon, I've been on the front lines of creating systems that handle real-world chaos gracefully.
Let's talk resiliency — focusing on critical architectural patterns in plain language: Retries, Circuit Breakers, and Bulkheads.
Resiliency Patterns Explained
1. Retry Logic: Giving Your Code a Second Chance
Think of retry logic as attempting to call your friend again if they don't answer the first time. It’s a straightforward, powerful way to handle temporary failures, like transient network hiccups or brief outages.
Key Points
- Exponential backoff: Increase wait times between retries to avoid overloading services.
- Limit retries: Cap your retry attempts (usually 3–5 attempts).
- Idempotency: Ensure operations can safely retry without side effects.
Illustrative Java Example:
(Disclaimer: This simplified snippet illustrates a general concept. Real-world implementations are significantly more intricate.)
public DeliveryPromise fetchDeliveryPromiseWithRetry(Cart cart, Address address) {
int maxRetries = 3;
int waitTimeMs = 1000;
for (int attempt = 1; attempt <= maxRetries; attempt++) {
try {
DeliveryPromise promise = deliveryService.getPromise(cart, address);
if (promise.isValid()) {
return promise;
}
Thread.sleep(waitTimeMs);
waitTimeMs *= 2; // Exponential backoff
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
break;
}
}
// Graceful fallback
return DeliveryPromise.unavailable("Cannot deliver to selected address.");
}
-2. Circuit Breakers: Knowing When to Stop Trying
Circuit breakers prevent systems from repeatedly trying — and failing — to call unresponsive services, much like the electrical breakers in your home that protect against overloads.
How they work:
- Monitor error rates.
- Temporarily halt calls when error thresholds are crossed.
- Gradually resume traffic after the system recovers.
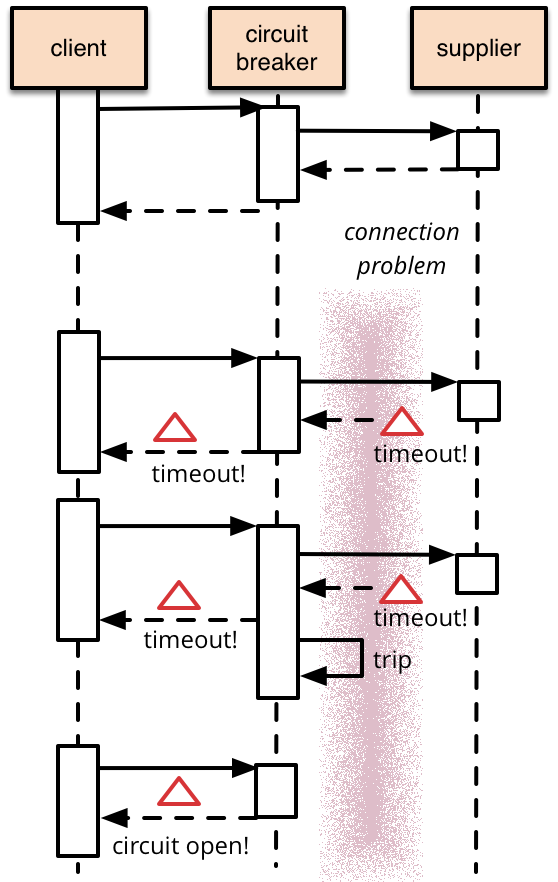
(Source: Martin Fowler)
3. Bulkheads: Containing the Damage
Bulkheads compartmentalize critical system parts. If one service crashes, bulkheads limit the impact, keeping your whole system afloat.
Best Practices
- Separate critical from non-critical paths.
- Provide dedicated resources and isolate failures.
Real-Life Story: A Minor Bug With Major Impact
Let me illustrate this with an actual scenario I encountered at Amazon. (Note: The following is an intentionally simplified and generalized example. Our actual scenario involved complex interactions across multiple services and teams.)
The Problem
An obscure, deprecated code path resurfaced after a routine platform migration. Customers browsing with a default delivery address would occasionally hit a rare but disastrous scenario:
- The customer selects products based on promises calculated for their default address.
- At checkout, they switch to a different delivery address.
- The delivery promise is no longer valid for the newly selected address.
- Instead of gracefully handling this edge case, our system spiraled into unnecessary retries, ending with a cryptic error message.
Imagine you're shopping for your friend's birthday gift. You trust the promise, proceed confidently, but at the last moment, you hit a confusing, looping error. Even if just 1% of shoppers experience this, the cumulative impact — especially on a scale of thousands of daily orders — is enormous. This seemingly small oversight was costing potential sales and damaging customer trust.
Technical Culprit: Misconfigured Retry Logic (Illustration)
Faulty Java Code Example (Highly Simplified):
int retries = 5;
while (retries-- > 0) {
DeliveryPromise promise = legacyService.getPromise(cart, address);
if (promise.isValid()) return promise;
// No backoff, no break, repetitive calls
}
// Cryptic error message after long delay
throw new DeliveryException("Delivery unavailable");This loop would repeatedly attempt the same call without meaningful delays or graceful exits, causing prolonged confusion.
Rapid Resolution: Graceful Fallbacks and Circuit Breakers
We quickly fixed the issue by introducing proper retry logic and graceful fallbacks, supported by circuit breakers:
Updated Java Example (Simplified for Illustration):
public DeliveryPromise safeFetchPromise(Cart cart, Address address) {
int retries = 3;
int waitMs = 500;
while (retries-- > 0) {
DeliveryPromise promise = deliveryService.getPromise(cart, address);
if (promise.isValid()) return promise;
try {
Thread.sleep(waitMs);
waitMs *= 2; // Exponential backoff
} catch (InterruptedException ie) {
Thread.currentThread().interrupt();
break;
}
}
// Immediate and clear user feedback
return DeliveryPromise.unavailable("Sorry, this item can't be delivered to the selected address.");
}Circuit Breaker Integration (Conceptual Example):
Circuit breakers helped detect failing downstream services instantly and reduced wasted retries:
if (circuitBreaker.isOpen()) {
return DeliveryPromise.unavailable("Delivery estimates temporarily unavailable.");
}Core Architectural Patterns Summarized:
- Retries: A simple way to handle temporary failures; use with caution and proper configuration.
- Circuit breakers: Fail-fast mechanism preventing cascading failures.
- Bulkheads: Compartmentalize your architecture to limit failure scope.
Key Takeaways for Every SDM
- Expect failure: It's inevitable; build resilience in.
- Judiciously implement retries: Useful, but avoid overwhelming your systems.
- Implement circuit breakers early: Essential in distributed systems to maintain stability.
- Design with bulkheads: Prevent total system failure by isolating critical services.
- Always prioritize user experience: Clearly inform users about system issues and failures.
Conclusion: Resiliency Is More Than Just Good Design
Building resilient systems means proactively protecting your customers' experience and your team's sanity. Resiliency isn’t just technical — it's empathetic leadership, critical foresight, and practical risk management.
Disclaimer on Illustrative Examples
All code examples provided here are significantly simplified for illustrative purposes. The actual scenario encountered at Amazon involved deeply intertwined services across multiple code packages and teams. I cannot disclose the exact implementation or proprietary details, but the lessons presented here are generic enough that many will recognize and relate to these patterns and solutions.
References and Further Reading
Have you faced similar resilience challenges? I'd love to hear your stories and solutions.
Opinions expressed by DZone contributors are their own.
Comments