Docker Model Runner: Running AI Models Locally Made Simple
Docker Model Runner: run AI models locally with zero setup. Pull from Docker Hub, chat via CLI or API. OpenAI-compatible. Beta.
Join the DZone community and get the full member experience.
Join For FreeDocker has released an exciting new beta feature that's set to revolutionize how developers work with generative AI. Docker Model Runner enables you to download, run, and manage AI models directly on your local machine without the complexity of setting up elaborate infrastructure.
What Is Docker Model Runner and Why Should You Care?
Docker Model Runner is a feature that dramatically simplifies AI model management for local development. Currently in beta testing, it's available in Docker Desktop version 4.40 and above across multiple platforms:
- macOS: Full support on Apple Silicon processors
- Windows: Supported with NVIDIA GPU acceleration available
- Linux: Available as a separate package for Docker Engine installations
Key Capabilities
The plugin empowers developers to:
- Download models directly from Docker Hub (specifically from the ai namespace, which hosts all available models)
- Execute AI models straight from the command line
- Manage local models with full CRUD operations (add, view, remove)
- Interact with models through single prompts or interactive chat sessions
Smart Resource Management
One of Docker Model Runner's standout features is its intelligent resource optimization. Models are pulled from Docker Hub only on first use and cached locally thereafter. They're loaded into memory exclusively during query execution and automatically unloaded when idle. While initial downloads can be time-consuming due to modern AI models' substantial size, subsequent access is lightning-fast thanks to local caching.
Another compelling advantage is the built-in OpenAI-compatible API support, making integration with existing applications seamless.
Essential Commands and Usage
Checking Service Status
$ docker model status
Docker Model Runner is runningViewing Available Commands
$ docker model help
Usage: docker model COMMAND
Docker Model Runner
Commands:
inspect Display detailed information on one model
list List the available models that can be run with the Docker Model Runner
pull Download a model
rm Remove a model downloaded from Docker Hub
run Run a model with the Docker Model Runner
status Check if the Docker Model Runner is running
version Show the Docker Model Runner version
Run 'docker model COMMAND --help' for more information on a command.Model Management Operations
Downloading a Model
$ docker model pull ai/smollm2
Downloaded: 0.00 MB
Model ai/smollm2 pulled successfullyNote: The download progress display currently shows 0.00 MB after completion — this is a known beta issue.
Listing Local Models
$ docker model list
MODEL PARAMETERS QUANTIZATION ARCHITECTURE MODEL ID CREATED SIZE
ai/smollm2 361.82 M IQ2_XXS/Q4_K_M llama 354bf30d0aa3 2 weeks ago 256.35 MiBRunning Models
Single prompt execution:
$ docker model run ai/smollm2 "Hello, how are you?"
Hello! I'm doing well, thank you for asking.Interactive chat mode:
$ docker model run ai/smollm2
Interactive chat mode started. Type '/bye' to exit.
> Hello there!
Hello! How can I help you today?
> /bye
Chat session ended.Removing Models
$ docker model rm ai/smollm2
Model ai/smollm2 removed successfullyViewing Logs for Troubleshooting
$ docker model logs
# Or through Docker Desktop GUI: Models → Logs tabApplication Integration Through OpenAI-Compatible APIs
Docker Model Runner exposes OpenAI-compatible API endpoints with multiple access methods. Here are examples for different scenarios:
From within a container:
#!/bin/sh
curl http://model-runner.docker.internal/engines/llama.cpp/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "ai/smollm2",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Write a brief explanation of containerization benefits."
}
]
}'From the host via TCP (requires enabling TCP support):
# First enable TCP support
$ docker desktop enable model-runner --tcp 12434
# Then make API calls
#!/bin/sh
curl http://localhost:12434/engines/llama.cpp/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "ai/smollm2",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Explain microservices architecture in simple terms."
}
]
}'From the host via Unix socket:
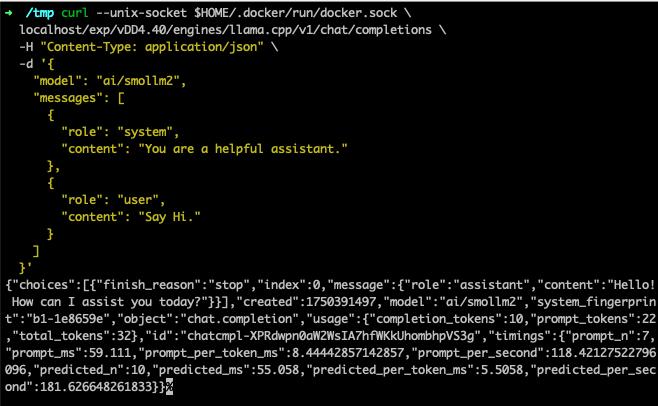
#!/bin/sh
curl --unix-socket $HOME/.docker/run/docker.sock \
localhost/exp/vDD4.40/engines/llama.cpp/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "ai/smollm2",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Explain microservices architecture in simple terms."
}
]
}'
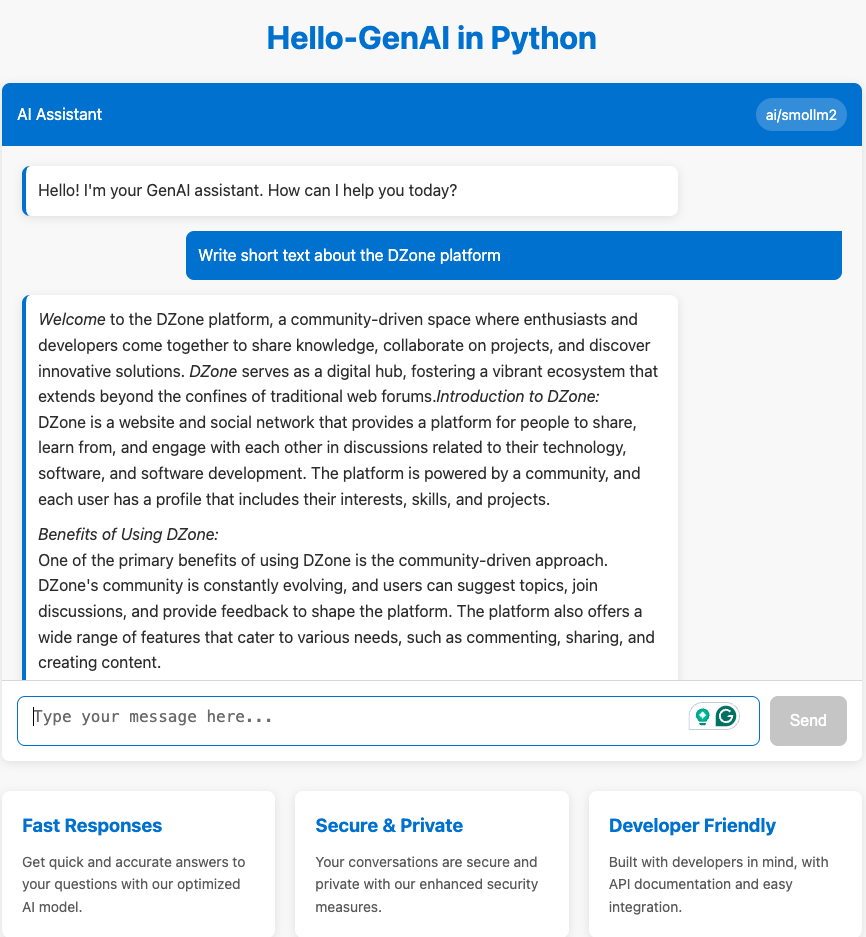
Quick Start With Sample GenAI Application
To immediately experience Docker Model Runner with a complete generative AI application:
- Clone the sample repository:
$ git clone https://github.com/docker/hello-genai.git - Navigate to the project directory:
$ cd hello-genai - Execute the run script to download the selected model and launch the application:
$ ./run.sh - Open the application in your browser using the URL specified in the repository README.
Available API Endpoints
Once Docker Model Runner is active, the following APIs become available:
Container-Internal Endpoints
http://model-runner.docker.internal/
# Model Management
POST /models/create
GET /models
GET /models/{namespace}/{name}
DELETE /models/{namespace}/{name}
# OpenAI-Compatible Endpoints
GET /engines/llama.cpp/v1/models
GET /engines/llama.cpp/v1/models/{namespace}/{name}
POST /engines/llama.cpp/v1/chat/completions
POST /engines/llama.cpp/v1/completions
POST /engines/llama.cpp/v1/embeddingsHost Access Options
TCP Access (when enabled):
http://localhost:12434/Host Gateway Access from containers:
http://172.17.0.1:12434/Unix socket access: The same endpoints are available on /var/run/docker.sock with the beta prefix /exp/vDD4.40
Note: The llama.cpp component can be omitted. For example: POST /engines/v1/chat/completions
Docker Compose Integration
For Docker Compose projects, you may need to add an extra_hosts directive to access the model runner:
extra_hosts:
- "model-runner.docker.internal:host-gateway"Known Issues and Troubleshooting
Command Recognition Problems
If you encounter:
docker: 'model' is not a docker commandThis indicates Docker cannot locate the plugin. Resolution:
$ ln -s /Applications/Docker.app/Contents/Resources/cli-plugins/docker-model ~/.docker/cli-plugins/docker-modelResource Management Limitations
Docker Model Runner currently lacks safeguards against loading models that exceed available system resources. Attempting to run oversized models may cause significant system slowdowns or temporary unresponsiveness. This is particularly problematic when running LLMs without sufficient GPU memory or system RAM.
Docker Model CLI Digest Support
The Docker Model CLI currently lacks consistent support for specifying models by image digest. As a workaround, refer to models by name instead of digest.
Download Failure Handling
When model downloads fail, docker model run may still initiate the chat interface despite the model being unavailable. In such cases, manually retry the docker model pull command.
Configuration Management
Docker Desktop Setup
Docker Model Runner is enabled by default in Docker Desktop. To modify this setting:
- Open Docker Desktop settings.
- Navigate to Beta under Features in development (for versions 4.42+) or Experimental features (for versions 4.41 and earlier).
- Toggle the Enable Docker Model Runner checkbox.
- On Windows with a supported NVIDIA GPU, also enable Enable GPU-backed inference
- Click Apply & restart.
Docker Engine Installation (Linux)
For Docker Engine on Linux, install the Docker Model Runner package:
Ubuntu/Debian
$ sudo apt-get update
$ sudo apt-get install docker-model-pluginRHEL/Fedora
$ sudo dnf update
$ sudo dnf install docker-model-pluginTest the installation:
$ docker model version
$ docker model run ai/smollm2Framework Integration
Docker Model Runner now supports integration with popular development frameworks:
- Testcontainers (Java and Go)
- Docker Compose (with proper host configuration)
Conclusion
Docker Model Runner makes running AI models locally much easier than before. You don't need to set up complex systems or pay for cloud APIs anymore - everything runs on your own computer.
Since it's still in beta, there are some bugs and missing features. But Docker is working to fix these issues and wants to hear what users think. You can share feedback using the "Give feedback" link next to the Docker Model Runner settings.
If you're building AI apps or just want to try out AI models without the hassle, Docker Model Runner is a great tool to have. As Docker keeps improving it, this will likely become a must-have tool for anyone building AI applications.
Have you tried Docker Model Runner in your projects? Share your experiences and use cases in the comments.
Opinions expressed by DZone contributors are their own.
Comments