Docker Orchestration... What It Means and Why You Need It
Join the DZone community and get the full member experience.
Join For Free[This article was written by Yaron Parasol.]
Docker containers were created to help enable the fast, and reliable deployment of application components or tiers, by creating a container that holds a self-contained ready to deploy parts of applications, with the middleware and the app business logic needed to run them successfully. For example, a Spring application within a Tomcat container. By design, Docker is purposely an isolated self-contained part of the application, typically one tier or even one node in a tier.
However, an application is typically multi-tier in its architecture and that means you have tiers with dependencies between them, where the nature of the dependencies can be anything from network connections and remote API invocations, to exchange of messages between application tiers. And hence an app is a set of different containers with specific configurations. This is why you need a way to glue the pieces of your app together.
While, Docker has a basic solution for connecting containers using a Docker bridge, this solution is not always the preferred one, especially when deploying the container across different hosts and you need to take care of real network settings.
Docker orchestration with TOSCA + Cloudify. Check it out. Go
So, what role does the orchestrator play?
The orchestrator will take care of two things:
The timing of container creation - as containers need to be created by order of dependencies and
Container configuration in order to allow containers to communicate with one another - and for that the orchestrator needs to pass runtime properties between containers.
As a side note here: With Docker you need a special tweak here, as you typically don’t touch config files inside a container, you keep the container intact, so there is an interesting workaround for cases that this is required.
One method to do this is by using a YAML-based orchestration plan to orchestrate the deployment of apps and post-deployment automation processes, which is the approach Cloudify employs. Based on TOSCA (topology and orchestration standard of cloud apps), this orchestration plan describes the components and their lifecycle, and the relationships between components, especially when it comes to complex topologies. This includes, what’s connected to what, what’s hosted on what, and other such considerations. TOSCA is able to describe the infrastructure, as well as, the middleware tier, and app layers on top of these. Cloudify basically takes this TOSCA orchestration plan (dubbed blueprints in Cloudify speak) and materializes these using workflows that traverse the graph of components, or this plan of components and issues commands to agents. These then create the app components and glue them together.
The agents use extensions called plugins that are adaptors between the Cloudify configuration and the various infrastructure as a service (IaaS) and automation tools’ APIs.
In our case, we created a plugin to interface with the Docker API.
Introducing the Docker Cloudify Plugin
The Cloudify-Docker plugin is quite straightforward, it installs the Docker API endpoint/server on the machine and then uses the Docker-Py binding to create, configure, and remove containers. TOSCA lifecycle events are:
Create - installation of the app components
Configure - configuration of the component
Start - startup/running the component
There is also stop & delete - for shutdown and removal
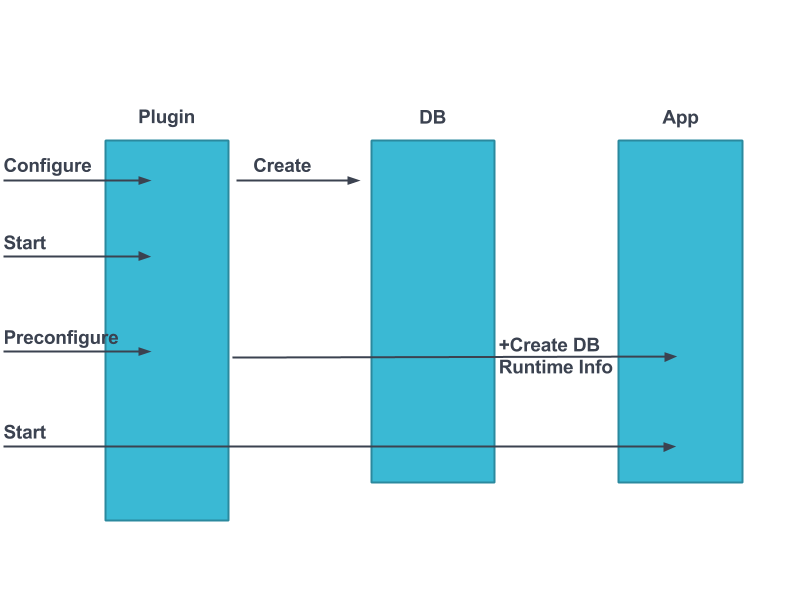
We started by using the create - to create the container, we did not implement configure at the beginning, and start to run the application. But then we realized that for containers with dependencies we need to have runtime properties, such as IP import of the counterpart container in order to create the container for example. When we create an app server container, we need the port and IP of the database container. So, we pushed the creation of the container to the configure event, and used a TOSCA relationship pre-configure hook, to get the dependent container’s info at runtime.
01.interfaces:
02. cloudify.interfaces.lifecycle:
03. configure:
04. implementation: docker.docker_plugin.tasks.configure
05. inputs:
06. container_config:
07. command: mongod--rest--httpinterface --smallfiles
08. image: dockerfile/mongodb
09. start:
10. implementation: docker.docker_plugin.tasks.run
11. inputs:
12. container_start:
13. port_bindings:
14. 27017: 27017
15. 28017: 28017
Nodecellar Example
I’d like to explain how this works by using our Nodecellar app as an example. The Nodecellar app is composed of two hosts that, in this case, Cloudify didn’t create but just SSHed into and then installed agents on. On one we have the MongoD container, with a MongoD process. On the other we have the Nodecellar container with NodeJS and the Nodecellar app within it. The Nodecellar container needs a connection to the MongoD container to run the app queries when the app starts.
Ultimately, an orchestrator should not be limited to software deployment, the whole idea behind Docker Is to allow for agility, so we’d also like to use Docker in situations of auto-scale out and auto-heal, CD. In our next post we’ll show exactly that - how Cloudify can be used with Docker for post-deployment scenarios.
Published at DZone with permission of Sharone Zitzman. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments