Docs to Codes Generation Using LLMs
Large Language Models (LLMs) significantly streamline the translation of detailed doctors' notes into precise medical codes, enhancing efficiency and accuracy.
Join the DZone community and get the full member experience.
Join For FreeGenerating code from doctors' notes can be a complex task as it requires a deep understanding of medical terminology and the ability to translate that information into the specific codes used in medical billing and reimbursement. The Large Language Models (LLMs) with the encoded world knowledge have a great potential to make this task more efficient and accurate.
Evolution of Machine Learning to LLMs
The field of machine learning has undergone a significant transformation in the past decade. Previously, generating codes from doctors' notes using machine learning was a slow, difficult, and imprecise process. It involved collecting and preprocessing relevant data, crafting features by hand, selecting the right model, tuning the model through adjusting hyperparameters, and creating the infrastructure to deploy the model. These tasks were tedious and expensive, but the end result was often a model with suboptimal performance.

Figure 1: Traditional machine learning process
However, with the advent of deep learning, the process became easier and more accurate. Deep networks were able to encode knowledge through their embeddings. The issue with deep models was their dependence on a significant amount of data required for training.
Now, the evolution of large language models like GPT has made language-related tasks, such as in the healthcare sector, much simpler. These models, with O(100B) parameters, encode a vast amount of knowledge from diverse domains and sources such as healthcare, software programming, books, blogs, scientific papers, and social media. Learning from a massive amount of data allows them to learn rich representations of language from data and generalize to new tasks. For a wide variety of simple tasks, the models can be used with zero or few shots learning, and for more complex tasks, these models can be fine-tuned with a small amount of data.
LLMs and Prompt Engineering
One aim in the field of machine learning has been to develop algorithms that can learn in a manner similar to humans. These algorithms should comprehend simple sets of tasks when given instructions and examples. In the realm of Large Language Models, these instructions and examples are called prompts.
Zero-Shot Learning
The prompts could be straightforward requests from the users, such as:
- Summarize the text
- Paraphrase the text
- Why is the sky blue?
- Write a code to check if the string is palindrome.
These models can answer these questions without the need for further examples, a process known as zero-shot learning.
Few Shots Learning and Chain-Of-Thought Prompting
Some tasks necessitate more detailed instructions, similar to those a human would receive. An illustration of this type of prompt would be:
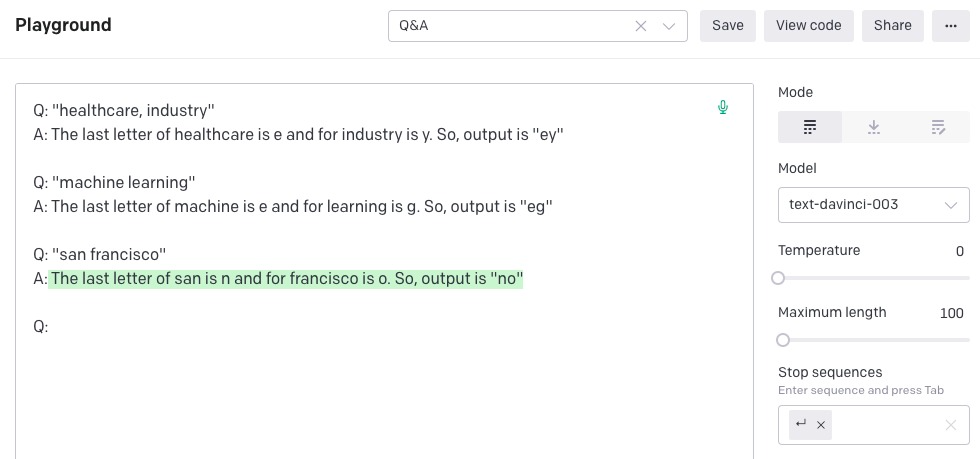
Task
```
Input: Healthcare Industry Output: ey
Input: Machine Learning Output: eg
Input: San Francisco Output:
```Here, the task is to figure out a pattern from the input-output pairs and predict that the output is “no.” The pattern is to return the last letter of each work.
Below is the output from ChatGPT where it got it wrong:

Giving more detailed instructions to the model generated the correct answer. This explanation given to the prompts to yield required answers is called chain-of-thought prompting.
This process of creating, designing, and fine-tuning prompts is called prompt engineering. The goal of prompt engineering is to provide input to the language model in a specific way so that it generates output that is relevant, coherent, and consistent with the intended meaning. This involves writing effective and clear prompts that can guide the language model to generate high-quality output that meets the needs of a particular use case, such as generating answers to questions, writing stories, composing poems, or translating text. The process of prompt engineering also involves testing and evaluating the performance of the language model with different prompts, making adjustments as necessary to improve its output.
In the context of generating codes from physician's notes, prompt engineering would involve addressing abbreviations and comprehending the differences and subtleties of diseases, symptoms, and medication prescriptions.
Development Steps
The process of utilizing large language models (LLMs) to produce medical codes from physicians' notes involves the following steps:
- Acquire the data: Obtain the data and perform manual pre-processing for initial experimentation.
- Establish the metrics: Determine the metrics for evaluating system performance, such as precision and recall of predicted responses and response time latency.
- Select LLM: Explore different LLMs and their APIs. Possible choices: GPT, BARD.
- Set up workspace: Setting up a workspace for prompt engineering.
- Prompt engineering: Engage in prompt engineering by experimenting with chain-of-thought prompting to find the optimal set of prompts.
- Establish the benchmark: Establish a benchmark for performance and comparing it to current processes and market solutions.
- Generate a dataset: Generate a dataset through LLM inference.
- Distillation: Train a student model through the distillation of the teacher model.
- Performance benchmark: Benchmark the performance of the student model and identify strengths and weaknesses.
- Serving infrastructure: Set up a serving infrastructure for the student model, including necessary adaptors and software systems for integration with existing systems.
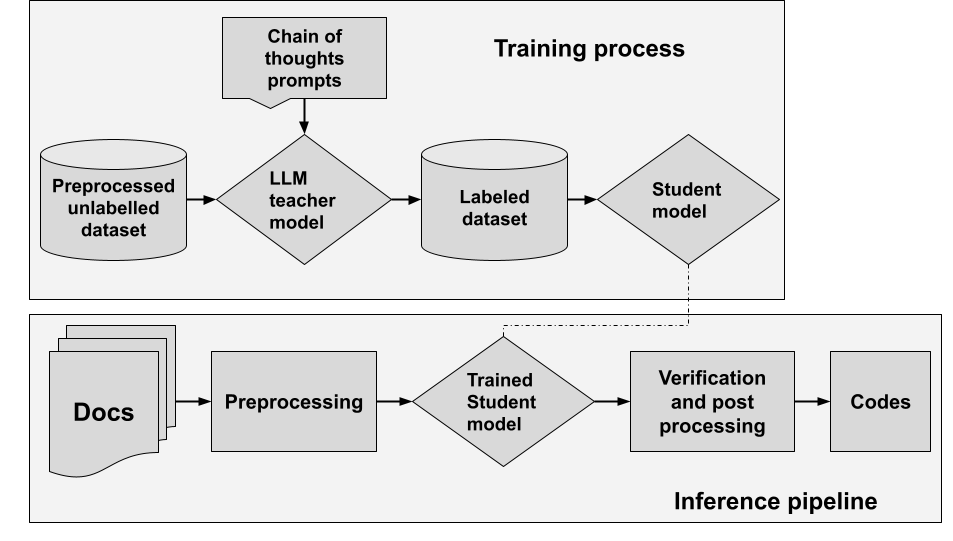
Figure 2: High-level training and infra pipeline
Opinions expressed by DZone contributors are their own.
Comments