Don't Give Up Yet… Keep-Alive!
There is one source of performance problems I've been encountering for years and still see every time: Missing HTTP keep-alive. Find out why this is still a problem.
Join the DZone community and get the full member experience.
Join For FreeWe founded StormForger Load and Performance Testing SaaS in 2014 and while much has changed since then, one thing hasn't.
HTTP is with its 24 years a well-aged fellow among the web protocols.¹ Today we are mostly using HTTP/1.1² or HTTP/2 and if you have fully embraced the new HTTP/2 world in your entire system this article is mostly an anecdote of past issues. But HTTP/1.1 is still alive and kicking for many systems. And even given its age, people are still forgetting about a very important feature that previous versions did not provide: keep-alive.³
To clarify, I'm not talking about TCP keep-alive (which is disabled by default). Also I'm not talking about other kinds of keep-alive mechanisms for other protocols which are equally important to keep an eye on. Today, we will focus on HTTP keep-alive.
How Does HTTP Work?
HTTP (at least prior to HTTP/2) is a very simple protocol. In the following example it takes 224 milliseconds for a given request to fetch data from a server with the following steps happening (simplified):
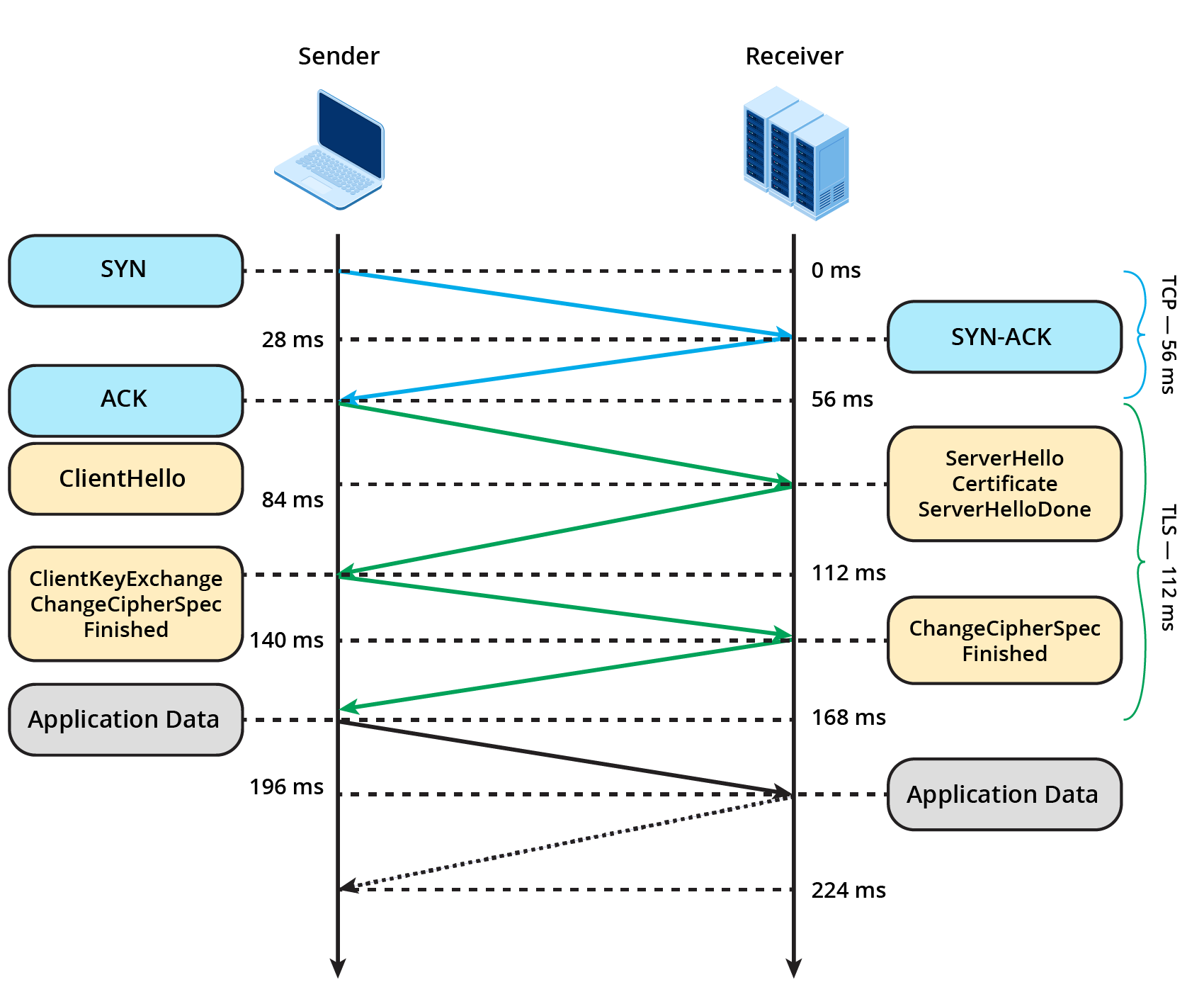
- DNS lookup is made (not in picture)
- a new TCP connection is established,
- the TLS handshake is performed,
- request headers and optional payload is sent,
- the response is read and
- the connection is closed.
The last point is the topic of this article: Don't close the connection! The example shows that it takes 168 ms just to activate the connection – that’s 75% of the entire process.
HTTP 1.1 learned to re-use an existing connection: If the response was read entirely, a new request could be sent using the existing connection. This happens automatically if both parties understand it. Unless the client sets the Connection: close request header or the server actively closes the connection it will be reused for subsequent requests. Sounds like a no-brainer, right?
Why Is This Important? Why Bother?
We seem to forget about the fact that there might be an issue with keep-alive. Almost everyone seems to be aware that this concept exists, but few are actively checking if everything is working as expected. You might be surprised how often keep-alive is not configured properly!
The other issue is: Developers and operations people heavily underestimate the impact of doing a DNS lookup, establishing a TCP connection, and making a TLS handshake. Over and over again. For every single HTTP request. Every. Single. Time.
From experience, we can tell that the overhead will add up very quickly. And it does not make a big difference in what kind of system you are building. Even for internal or even local systems, there is usually not really anything to gain from closing the connection. You don't have to take our word for it – there are many resources out there supporting this.
What we and our customers are observing when running tests with missing keep-alive is slower response times even for the moderate load. If more and more requests take longer to process, more connections stay active so more resources are consumed and blocked. In many cases systems under tests do not recover until traffic stops.
In the chart below you can see the results of an experiment I did a while back for a talk at the AWS User Group in Cologne. I excluded all other potentially influencing factors on latency and just focussed on keep-alive vs non-keep-alive and used a simple test case to give you an idea of how the TCP reconnects impacts latency (find the test definition at the end of this article).
Same target, same request, same response: Left is with keep-alive, right is without.
We see a clear bimodal distribution: One maximum where new connections need to be established and the other where an existing connection is being used. The difference is rather significant. The majority of requests done with keep-alive (left) have been executed within 20-30 ms, while most requests done without keep-alive took 110-120 ms. This is a ~75% performance improvement right there.
The difference comes from multiple factors:
- only spend DNS, TCP and TLS once per peer (multiple times if you are using a pool of connections)
- allocating a TCP socket is not for free, especially when the system is under load
- resources are finite and keeping sockets around can also quickly add up. Look out for sockets in the
TIME_WAITstate. - worst-case: You can run out of ephemeral ports, too.
If you want to learn more about TCP, sockets and TIME_WAIT and how to optimize your servers, check out this great article by Vincent Bernat: https://vincent.bernat.ch/en/blog/2014-tcp-time-wait-state-linux.
Keep-Alive and Current Architectural Approaches
The issue with keep-alive being overlooked is that the impact gets bigger considering some currently trending architectural approaches.
Take for example Server-less or Function-as-a-Service (FaaS)⁴. With FaaS you need to be stateless, but an application is usually not really fully stateless. Most of the time you solve this by externalizing state to other components and services. And how do you access the state again? Quite often it is done via HTTP. You should also check out Yan Cui's article on HTTP keep-alive as an optimization for AWS Lambda.
This especially affects Microservices: HTTP is often selected as the communication protocol of choice.
Again and again we are witnesses when our customers uncover these problems using performance tests and have rather quick wins in terms of latency, stability and general efficiency.
Conclusion
Use HTTP keep-alive. Always.
More importantly don't just assume it is used, check it. It can easily be tested with curl via curl -v http://example.com and looking for* Connection #0 to host example.com left intact at the end of the output. Testing it on a larger scale and especially revealing the impact is also done easily with a detailed performance test using specialized tools like StormForger. Catching a misconfiguration or an unintended configuration change using automated performance testing is even better because you minimize the risk of the potential havoc.
More Details
I've been using a simple test case to showcase the impact of HTTP keep-alive. We have two scenarios, each weighted 50%. One session does 25 HTTP requests with keep-alive (which is the default with StormForger) and the other one does 25 HTTP requests without keep-alive.
Note that our testapp does HTTP keep-alive by default:
xxxxxxxxxx
definition.session("keep-alive", function(session) {
// Every clients gets a new environment, so the first
// request cannot reuse an existing connection.
context.get("http://testapp.loadtest.party/", { tag: "no-keep-alive", });
// HTTP Keep-Alive is the default, so for all the following
// requests in this loop, we can reuse the connection.
session.times(26, function(context) {
context.get("http://testapp.loadtest.party/", { tag: "keep-alive" });
context.waitExp(0.5);
});
});
definition.session("no-keep-alive", function(session) {
// Setting the "Connection: close" header, we signal our
// client to close the connection when the transfer has
// finished, regardless if the server offers to keep the
// connection intact.
session.times(25, function(context) {
context.get("http://testapp.loadtest.party/", {
tag: "no-keep-alive",
headers: { Connection: "close", },
});
context.waitExp(0.5);
});
});
¹ Actually HTTP is even older, but I'm referring to RFC1945, or HTTP V1.0. HTTP V0.9 actually dates back almost 30 years.
² HTTP 1.1 is actually a collection of RFCs: RFC 7230, HTTP/1.1: Message Syntax and Routing, RFC 7231, HTTP/1.1: Semantics and Content, RFC 7232, HTTP/1.1: Conditional Requests, RFC 7233, HTTP/1.1: Range Requests, RFC 7234, HTTP/1.1: Caching, RFC 7235, HTTP/1.1: Authentication
³ Technically HTTP 1.0 could also support keep-alive but it was opt-in and not actually specified how this should work in detail. If the client wants a connection to be reused, one has to send Connection: keep-alive and check if the server responds with the same header. Only then (depending on the implementation) the connection was kept intact after a request.
⁴ Node.js's HTTP client or better HTTP Agent does not keep connections alive. You have to configure it explicitly, which is a bummer because Node.js is a pretty popular technology for FaaS and Server-less applications.
Published at DZone with permission of Sebastian Cohnen. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments