Efficient Error Handling With Anypoint MQ
In this article, take a look at efficient error handling with AnypointMQ and see the concept of DLQ and BLQ, learn about circuit breakers, and more.
Join the DZone community and get the full member experience.
Join For FreeWhat Are Queues?
Queue is a system where messages are pushed and are consumed by applications following a First In First Out (FIFO) rule.
Mulesoft Anypoint platform provides AnypointMQ service that is used by APIs. AnypointMQ can be configured in mule API during development. Messages can be sent and received from this queue asynchronously.
The Concept of DLQ and BLQ
Error handling is an essential part of any application and Queues can play an important role. Error handling can be done for 2 broad scenarios: Business logic errors (ex: HTTP:Bad Requests) and Server errors (ex: HTTP:Internal Server Error)
DLQ: Dead Letter Queue
When an error occurs due to server issues, we can send the original payload to a queue. This queue acts as DLQ. Pushing the payload to DLQ ensures zero loss of data. Whenever the server is up and running again, the queued messages can be reprocessed.
BLQ: Business Logic Error Queue
When an error occurs due to business logic compliance or any other code level issues (ex: null pointers), we can send the original payload to BLQ. Like DLQ, sending messages to BLQ ensures zero data loss. In case of data issues, these messages can be retrieved from BLQ and sent for reprocessing after rectifying the data gaps.
Why do we need DLQ and BLQ
The reason for having separate queues for business and server errors is that it becomes very easy to differentiate between 1) payloads that could not get processed at all due to server issues and can be retried for processing directly (DLQ), and 2) payloads that have a possible data issue and need to be scanned before they can be reprocessed(BLQ).
The Concept of Nack and Ack
Ack stands for ‘Acknowledgement’. Nack on contrary to Ack stands for ‘No Acknowledgment’.
When an incoming payload from a queue is Acknowledged, it gets deleted from the queue. On similar lines, if it is Not Acknowledged, the message persists in the queue.
In case of server errors, you may want to retry processing for a certain number of times before sending the message to DLQ. However, in case of data issues, retrying makes no sense and these faulty messages can be sent to BLQ right away. This can be achieved through Nack and Ack.
Assume you decide to reattempt processing a message 5 times for a server unavailable error. For the first 4 times you will need to Nack the message during error handling which ensures that the message is available in the queue for reprocessing. The 5th time you can Ack it and send it to DLQ.
In case of bad requests or business logic errors you can Ack the message and send it to BLQ on first error occurance.
The Concept of Circuit Breaker
Circuit breaker is an inherent part of reprocessing strategy in error handling. Whenever the error occurrences cross a certain threshold, circuit breaker stops all processing for a certain cooling period.
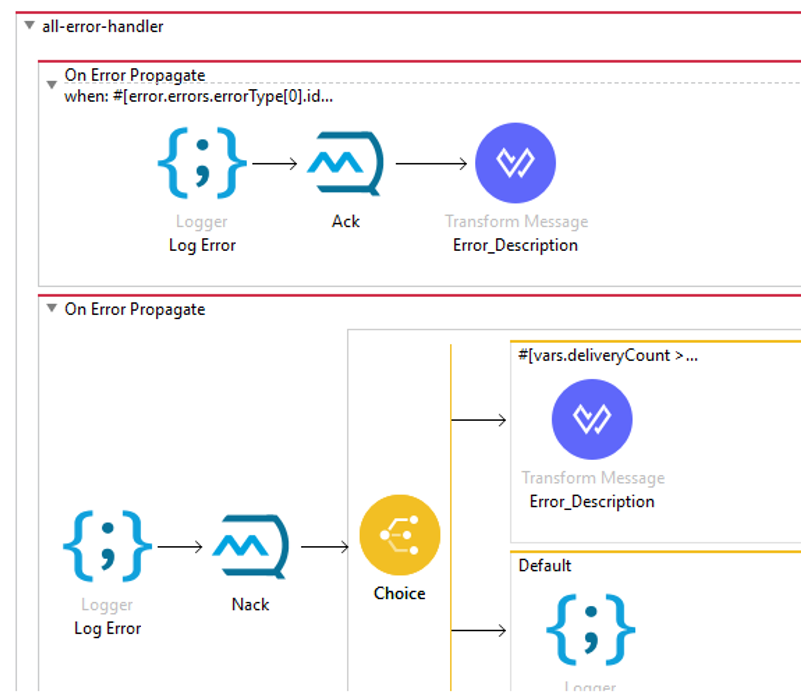
Following is a high level model of error handling logic that implements BLQ and DLQ with separation of server and data issues.
The when condition for business logic errors can cover the following. Hence, the left out would be server errors that will automatically get redirected to second route.
#[error.errors.errorType[0].identifier == "BAD_REQUEST" or error.errors.errorType[0].identifier == "EXPRESSION" or error.errorType.identifier== "SCHEMA_NOT_HONOURED" or error.errorType.identifier == "BAD_REQUEST" or error.errorType.identifier == "EXPRESSION" or error.errorType.identifier == "NOT_FOUND" or error.errors.errorType[0].identifier == "NOT_FOUND"]
You can maintain the max number of retries in a variable (vars.deliveryCount in example below) and test if the application has exhausted max retries.
Please note: if max number of retries is same as default in Anypoint MQ (i.e 10), you don’t need to explicitly Ack the message. It will automatically get acknowledged after 10 retries. However, if the number is lesser than 10, you need to add an Ack component in the second flow before Error_Description dataweave.
Opinions expressed by DZone contributors are their own.
Comments