Elasticsearch Query and Indexing Architecture
This article breaks down Elasticsearch's core architecture by explaining how search queries and indexing requests flow through the system.
Join the DZone community and get the full member experience.
Join For FreeWhat Is Elasticsearch?
Elasticsearch is a distributed, open-source search and analytics engine built atop the Apache Lucene library. Elasticsearch also offers vector search and retrieval augmented generation (RAG), supporting modern AI applications seamlessly. Applications can store structured and unstructured data in Elasticsearch, with or without a defined schema, by sending JSON payloads to an Elasticsearch cluster.
Elasticsearch Architecture
From the ground up, the main components of an Elasticsearch cluster are:
Document
A document is the smallest record of information stored by Elasticsearch and is represented as JSON. A document consists of multiple fields (key-value pairs) of different types and can have a predefined schema or be schema-less, inferring the data types of any new fields that are indexed.
Index
An index is a logical collection of documents with the same schema, identified by an index name.
Shard
Elasticsearch indexes are split into manageable units called shards, which are a collection of documents. Shards are the basic unit of search and are replicated across multiple nodes for redundancy and fault tolerance.
Node
A node is an independent instance of Elasticsearch and manages a collection of shards that belong to one or more indices. Nodes can have different roles like data node, master node, and ingest node.
Cluster
An Elasticsearch cluster is a collection of interconnected nodes. All nodes in a cluster can handle requests from clients, and communicate with each other. Each node in a cluster owns a subset of the shards that belong to an index.
Query Architecture
The following architecture diagram outlines the flow of a search request:
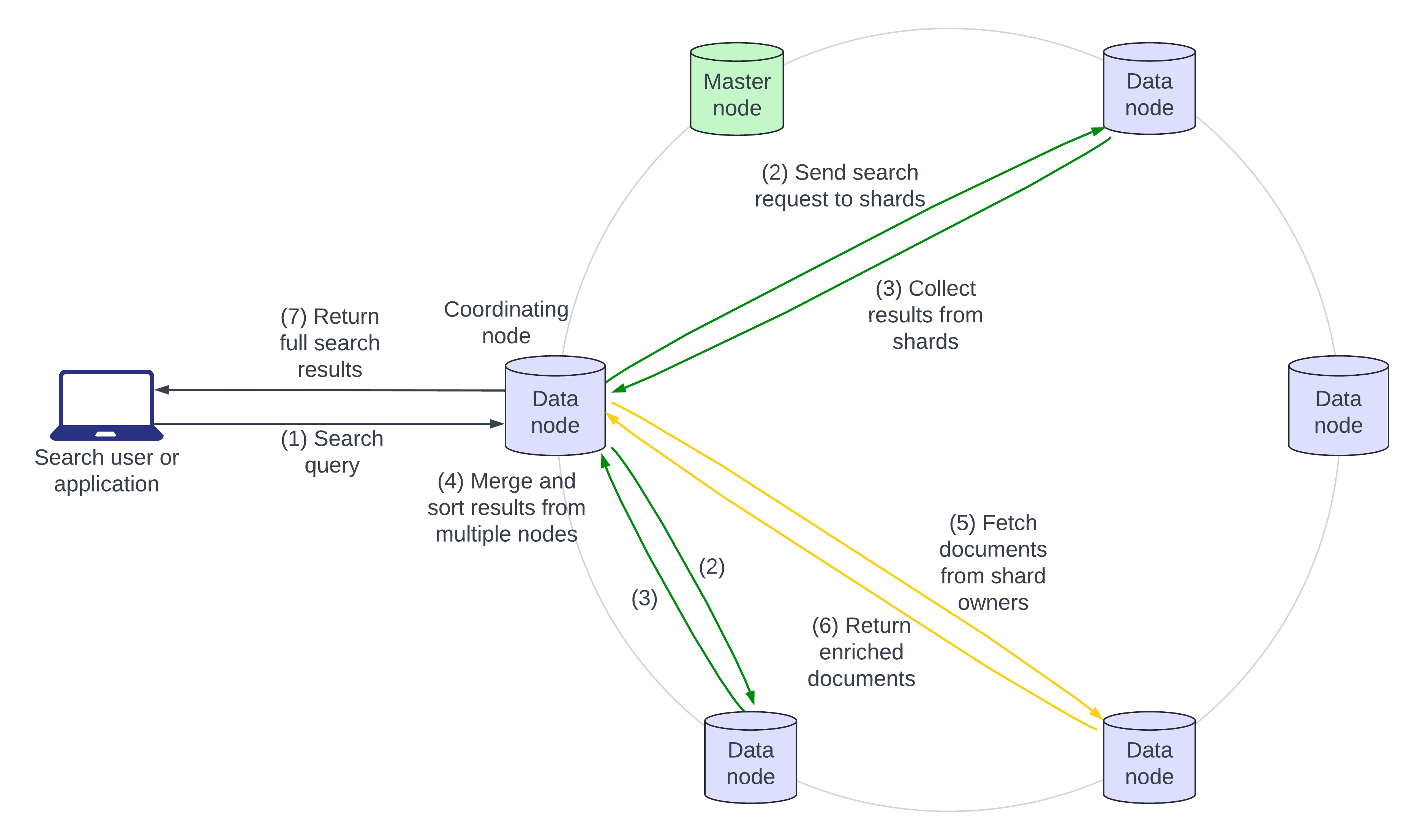
- The user or application makes a search query. The query can be handled by any node in the cluster. The node that handles the request is the “coordinating” node.
- The coordinating node broadcasts the query to all involved shards and their replicas.
- Each shard executes the query locally and returns a lightweight set of results to the coordinating node.
- The coordinating node merges the results it receives. This is the end of the “query” phase. The query phase identifies the bare-bones documents that form the search result, but the full document still needs to be retrieved.
- The coordinating node sends fetch requests to the owning shards, which enrich the documents in the result set.
- The enriched documents are returned to the coordinating node.
- The full set of search results, ranked and enriched, are returned to the caller.
Indexing Architecture
The following architecture diagram outlines the flow of an indexing request:

- The user sends a JSON document for Elasticsearch to index. If the document already exists, new fields are added, and existing fields are overwritten. The node that first receives the request is the “coordinating” node.
- The coordinate node identifies the primary shard of the incoming document, usually based on the document ID, and forwards the request to the data node which owns the primary shard.
- The primary shard validates the operation and executes it locally.
- The primary shard then forwards the operation to all its replicas in parallel.
- The replica shards apply the operation locally on their nodes.
- Steps 6, 7, and 8 show the acknowledgment of the write bubbling up from the replica shard to the primary shard, to the coordinating node, and to the caller.
Conclusion
This article describes the different components of an Elasticsearch cluster: documents, indexes, shards, and nodes. It also outlines the lifetime of a search request and an indexing request. Its flexible architecture makes it easy to add and remove nodes as the cluster scales. Combined with features like schema-less indexing and support for AI search features, this makes Elasticsearch the de-facto standard for organizations needing to efficiently store, search, and analyze large volumes of data in real time.
Opinions expressed by DZone contributors are their own.
Comments