Enable Distributed Data Processing for Cassandra With Spark
Learn how to take advantage of the distributed nature in Cassandra and apply any data processing logic parallelly on each data partitions.
Join the DZone community and get the full member experience.
Join For FreeCassandra is a distributed database system that offers linear scale performance with high availability over a cluster of commodity servers. A distributed data model or data partitioning is the primary technique in Cassandra as many others distributed storage systems to achieve scalable performance and fault tolerance. In Hadoop, the distributed data model of HDFS brings another value: MapReduce, a distributed programming model, which allows parallel data processing on its data partitions (data blocks). In Hadoop ecosystem, it's commonly known as, "bring computation closer to data."
Is it possible a similar data processing model with Cassandra? That is, take the advantage of distributed nature in Cassandra and apply any data processing logic parallelly on each data partitions? Yes, that's possible with Datastax Spark-Cassandra Connector, which provides the RDD abstraction for data collections in Cassandra.
Spark-Cassandra Connector
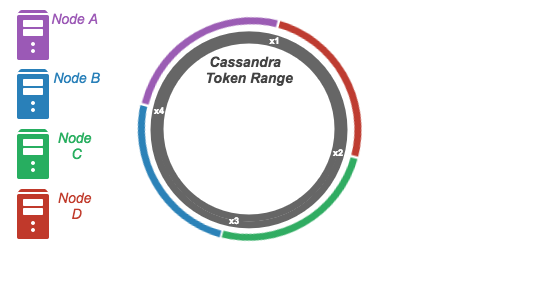
Cassandra uses a consistent hashing mechanism to distribute its data across a cluster of computer nodes. That is, for any given key in a Cassandra table is mapped to a unique value (token) in a token range. The token range is divided into partitions in a way so that each node in the cluster is responsible for a range of tokens, which can be presented as a ring as the following diagram.
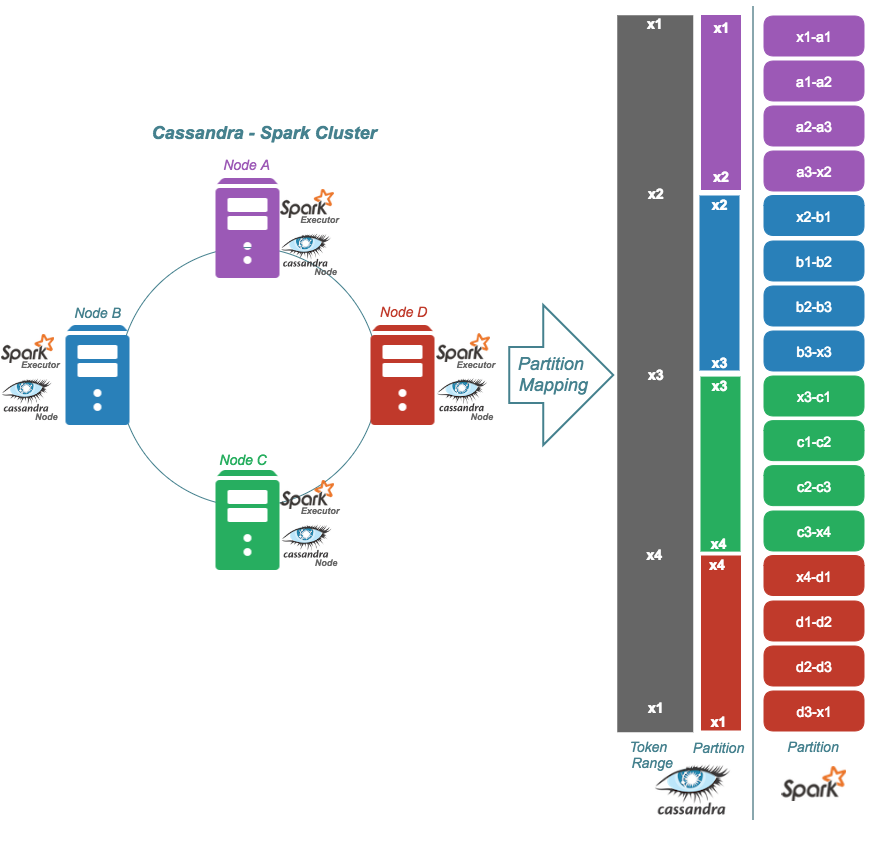
Datastax's Spark-Cassandra connector provides the RDD implementation for Cassandra data. The Spark-Cassandra connector further breaks Cassandra data partitions into multiple partitions on which Spark executors perform data processing in parallel. The following figure depicts the partitions mapping of Cassandra and Spark (for more detail, see the presentation slides by Russel Spitzer).
Evaluate Spark-Cassandra Connector
Let's evaluate the advantage of Spark-Cassandra connector with a simple example. Consider the following Cassandra table, order_items, which was designed with a query requirement: Get items by order id.
create table order_items ( id uuid, itemid uuid, amount int, primary key ((id), itemid) );And we are supposed to calculate the total item's amount per order and save into the table, order_item_summary.
create table order_item_summary ( id uuid, totamount int, primary key (id) );Data Processing With Standalone Java Applications (Single JVM)
A naive approach for achieving above task is to read data from the order_items table, aggregate data, and write the result back to the tableorder_items_summary. The following is how we normally read with Cassandra client and aggregate the result;
ResultSet result = session.execute(new SimpleStatement("select * from order_items"));
Map<String, Integer> orderItemSummary = result.all() .stream()
.collect(Collectors.groupingBy(row -> row.getString("orderid"),
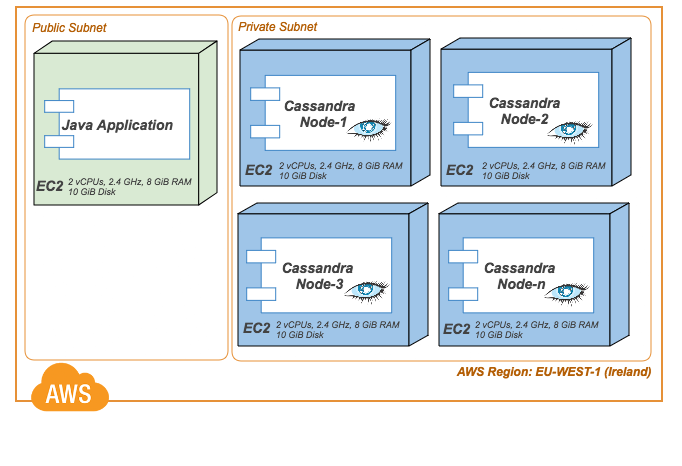
Collectors.reducing(0, row -> row.getInt("amount"), Integer::sum)));The above code snippet was executed in a simple java application (with -Xmx 1024m ) over a Cassandra Cluster of four nodes. The Cassandra Cluster was set up on AWS EC2 instances as in the below figure.
The elapsed time for the data processing task (i.e. reading data from order_items table, aggregate and write the result back to order_items_summary table) was measured for large data collections (1 million - 3 million records) in the tableorder_items. The following was the result.

As it depicts in the graph, increasing data size affects the data processing time but does not scale very well. It stopped the execution with an exception from Cassandra client at the data size of three million rows. The reason was ResultSet.all() tries to fetch all rows into a single JVM. We can avoid the memory issue with Spliterator interface in Java, which divides work into smaller pieces.
ResultSet result = session.execute( new SimpleStatement("select * from order_items"));
Map<String, Integer> orderItemSummary = StreamSupport.stream(result.spliterator(), true)
.collect(Collectors.groupingBy(row -> row.getString("orderid"),
Collectors.reducing(0, row -> row.getInt("amount"), Integer::sum)));The result for application with above code changed shows some improvement compared to the previous method.

With Spliterator, it handles growing dataset up to four million records but crashed with OutOfMemory at five million data rows. We can achieve a better result with the same Java application by increasing more memory in JVM (Horizontal scaling) but there is always a maximum resource limit for a single node. A distributed system approach is required for processing intensive data collections in Cassandra.
Data Processing With Apache Spark (Spark-Cassandra Connector)
The main motivation behind using Apache Spark for data processing is to take the advantage of data partitions of the underlying distributed storage system. The Spark-Cassandra connector provides the RDD implementation for Cassandra data collections. With Spark DataFrame API, we can write data processing tasks to be executed parallelly on each data partitions in multiple nodes (separate JVMs with Spark Executors). The following is the code snippet for achieving the same task in Spark.
Map<String, String> optSummaryItems = new HashMap<String, String>();
optSummaryItems.put("keyspace", "items_ks");
optSummaryItems.put("table", "summary_items");
Dataset<Row> df = sparkSession.read()
.format("org.apache.spark.sql.cassandra")
.options(optSummaryItems).load();
Dataset<Row> summaryDf = df.groupBy("id").sum("amount");
Map<String, String> optSummaryItemsSum= new HashMap<>();
optSummaryItemsSum.put("keyspace", "items_ks");
optSummaryItemsSum.put("table", "summary_items_sum");
summaryDf.write().format("org.apache.spark.sql.cassandra")
.options(optSummaryItemsSum)
.save();The above code was executed in a Spark application (with Spark executers of 1024mb) with the following cluster setup.

The elapsed time was measured for same five million data records in the order_items table but with different Spark cluster size (changing the number of slaves nodes in Spark cluster).

The result shows a more scalable solution for processing Cassandra data collections with Spark. There is always a maximum processing limit a single JVM can handle. With Spark, a data processing logic can be distributed across many JVMs (Spark executors) that will be executed parallelly on multiple data partitions and achieve better performance with scalability.
Opinions expressed by DZone contributors are their own.
Comments