Engineering Agentic AI for Production: A Distributed Systems Perspective
Production agentic AI fails above the model layer - not because of the weights, but because of everything built around them.
Join the DZone community and get the full member experience.
Join For FreeAgentic AI demos are everywhere. Production agentic AI is rare. The gap between the two is not a model problem; it is an engineering problem, and it is one that distributed systems engineers are uniquely positioned to solve.
The instinct in most teams is to treat the LLM as the hard part. Fine-tune it, prompt it carefully, pick the right model size, and ship. But once an agent is running in a loop (planning, calling tools, observing results, replanning), the model becomes the least of your problems. What breaks production agentic systems is everything around the model: how context is managed across turns, how failures propagate through multi-step plans, how you observe what went wrong three tool calls deep, and how you prevent a single bad plan from doing irreversible damage. These are distributed systems problems wearing an AI costume.
This article is a practitioner's guide to the two layers most teams skip: context engineering and harness engineering. Together, they are the difference between a system that works in a demo and one that works at 3 AM on a Tuesday.
The Stack
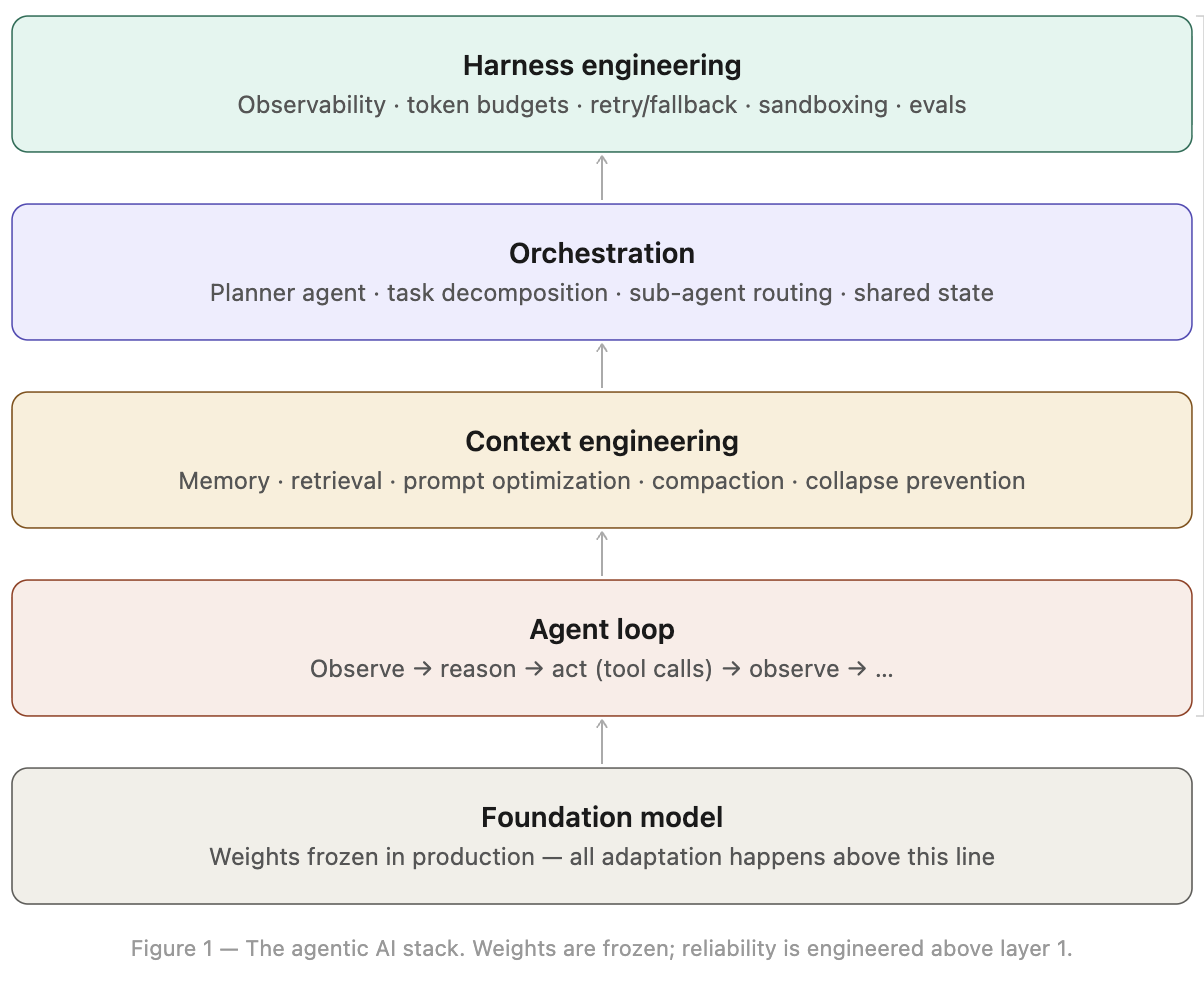
Before going further, it helps to be precise about what we mean by an agentic system. There are five logical layers:
- Foundation model: The LLM. Weights are frozen in production. All adaptation happens above this line.
- Agent loop: The plan-observe-act cycle. The model reasons about a goal, selects a tool call, observes the result, and iterates. This is the ReAct pattern at its core.
- Context engineering: What goes into each LLM call. Instructions, memory, retrieved documents, tool outputs, and conversation history. This is the inner loop problem.
- Orchestration: How multiple agents coordinate. Planner agents decompose tasks, sub-agents execute them, state is shared across boundaries.
- Harness engineering: The outer loop. Observability, cost controls, retry logic, guardrails, evals. This is where production reliability is actually won or lost.
Most teams invest heavily in layers 1 and 2, underinvest in layer 3, and largely ignore layers 4 and 5 until something breaks badly enough to force attention. This article focuses on layers 3 through 5.
Context Engineering: The Inner Loop
Every time the agent loop makes an LLM call, it assembles a context window, a snapshot of everything the model needs to reason about the next step. In a short task, this is manageable. In a long-horizon task, it becomes the central engineering challenge.
The naive approach is to append everything: the original system prompt, the full conversation history, every tool output from every prior step. Context windows are large now (128K, 200K tokens), so why not? The problem is threefold. Cost and latency grow with context size. Signal degrades as the window fills with stale, irrelevant state. And most critically, the model's behavior changes in ways that are hard to predict when it is processing a context full of old decisions and superseded plans.
The research literature names two specific failure modes here. Brevity bias occurs when automated prompt optimization discards detailed domain knowledge in favor of concise generic instructions; the context gets shorter and cleaner but loses the specificity that made it useful. Context collapse is more severe: when a system iteratively rewrites its accumulated context into a single compressed summary, it gradually erases details, the way overwriting a document erases prior versions. A customer support agent that collapses its context mid-conversation may lose awareness of commitments made three turns earlier.
The practical implication is that context is not a string; it is a data structure with explicit lifecycle semantics. What gets retained, what gets summarized, what gets evicted, and when, are engineering decisions, not defaults. The ACE framework from Stanford and SambaNova formalizes this with an "evolving playbook" model: rather than rewriting the full context, it applies incremental, itemized updates through a generate-reflect-curate loop. The result is a context that accumulates knowledge without collapsing under its own weight, showing +10.6% improvement on agent benchmarks over baseline approaches.
Actionable Principles
- Treat context as a tiered store. Hot context (current plan, immediate tool outputs) stays verbatim. Warm context (recent history, relevant facts) gets summarized. Cold context (early turns, superseded state) gets evicted or archived.
- Never let the context window be an unbounded append log. Define explicit compaction triggers: token thresholds, step counts, and plan transitions.
- Separate durable state from per-call views. The agent's full memory lives in storage; what gets assembled into each LLM call is a compiled view over that state, optimized for the current step.
Beyond these principles, there are several concrete techniques worth adopting.
Sliding window with selective retention. The simplest compaction strategy is a sliding window that keeps the last N turns and drops the rest. This works for short tasks but fails for long-horizon ones where an early decision still matters 40 steps later. The improvement is selective retention: rather than dropping old turns wholesale, score each entry by relevance to the current plan step and retain high-signal items regardless of age. Relevance can be as simple as keyword overlap with the current goal, or as sophisticated as embedding similarity against a query derived from the active task.
Hierarchical summarization. Rather than compressing the entire context into one summary (which is exactly how context collapse happens), apply summarization hierarchically. Summarize completed sub-tasks independently and store those summaries as discrete, labeled entries. The current task's detail stays intact; finished work gets compressed. When a prior sub-task becomes relevant again, its summary is retrievable without dragging in everything else. Think of it as the difference between a changelog entry per commit versus rewriting the whole codebase history into a single paragraph.
Tool output truncation and normalization. Tool outputs are often the biggest contributor to runaway context growth. A database query that returns 500 rows, an API response with deeply nested JSON, a web scrape with navigation markup intact: none of this belongs verbatim in the context window. The harness should post-process tool outputs before they enter the context: truncate to a token budget, extract the fields the agent declared it needs, strip boilerplate. This is analogous to response filtering in an API gateway and belongs at the same layer.
Explicit memory slots. Rather than relying on the model to extract relevant facts from a long history, define structured memory slots that the agent writes to explicitly: goal, constraints, decisions made, open questions, and current plan step. These slots live at the top of the context, always present, always compact. The rolling history follows. This gives the model a reliable anchor and reduces the risk of it fixating on stale detail buried in the middle of a long window.
Context invalidation on plan revision. When the agent revises its plan mid-task, a significant portion of the accumulated context is now stale. Prior tool outputs gathered under the old plan may be irrelevant or actively misleading under the new one. The harness should treat a plan revision as a context checkpoint: archive the pre-revision history, reset the active context to goal plus constraints plus the new plan, and let the agent rebuild from there. This is the agentic equivalent of cache invalidation on a schema change.
Harness Engineering: The Outer Loop
If context engineering is about what the model sees, harness engineering is about what happens when things go wrong, and with agentic systems, things go wrong in novel ways.
Observability
A single agentic task may involve dozens of LLM calls, spread across planning steps, tool invocations, and sub-agent delegations. When something fails or produces a wrong result, the standard question "which call was the problem?" becomes genuinely hard to answer without structured tracing.
The distributed systems answer is familiar: trace every operation, propagate trace context across boundaries, attach structured metadata to every span. Applied to agentic systems, this means each LLM call is a span with attributes for token counts, model version, context size, and the plan step it corresponds to. Tool calls are child spans. Sub-agent invocations carry the parent trace ID. You want to reconstruct the full causal chain from goal to outcome, with cost attribution at every node.
What makes this harder than standard distributed tracing is that the "call graph" is not defined at deploy time; it is generated at runtime by the model's planning. Your observability infrastructure needs to handle dynamic, variable-depth call trees, not a static service dependency graph.
Token Budgets and Backpressure
Token cost in agentic systems behaves like unbounded queue depth in a distributed system: it is fine until it isn't, and by the time you notice, the damage is done. A task that was scoped as a 10-step plan can silently expand to 40 steps if the model is allowed to keep replanning without constraint.
The right pattern here is borrowed directly from backpressure: define explicit token budgets per task, per plan phase, and per tool call category. When a budget is approached, the harness signals the agent to wrap up: summarize findings, return partial results, or escalate to a human. When a budget is exceeded, the harness terminates the task rather than letting it run to an arbitrary conclusion.
Circuit breaking applies too. If a particular tool is returning errors or unexpectedly large payloads, the harness should stop routing calls to it, the same way a circuit breaker stops routing requests to a degraded downstream service. Letting the agent retry a broken tool indefinitely is the agentic equivalent of a retry storm.
Retry Logic and Idempotency
The retry dilemma in agentic systems is worse than in standard RPC because the operations being retried are not simple reads or writes; they are tool calls with real-world side effects. Retrying a tool call that sends an email, modifies a database record, or submits an API request requires the same idempotency guarantees you would demand of any at-least-once delivery system.
The harness needs to classify tool calls by their side effect profile before deciding on retry behavior. Read-only retrieval calls can be retried freely. Write operations need idempotency keys. Irreversible operations (anything that sends, submits, or publishes) should require explicit confirmation before execution, and should not be retried on failure without human review.
This sounds obvious, but in practice, most agentic frameworks treat all tool calls uniformly. The result is agents that helpfully retry a failed email send, producing duplicates, or that resubmit a partially completed order due to a planning error.
Securing Agents: Sandboxing, Trust Boundaries, and Prompt Injection
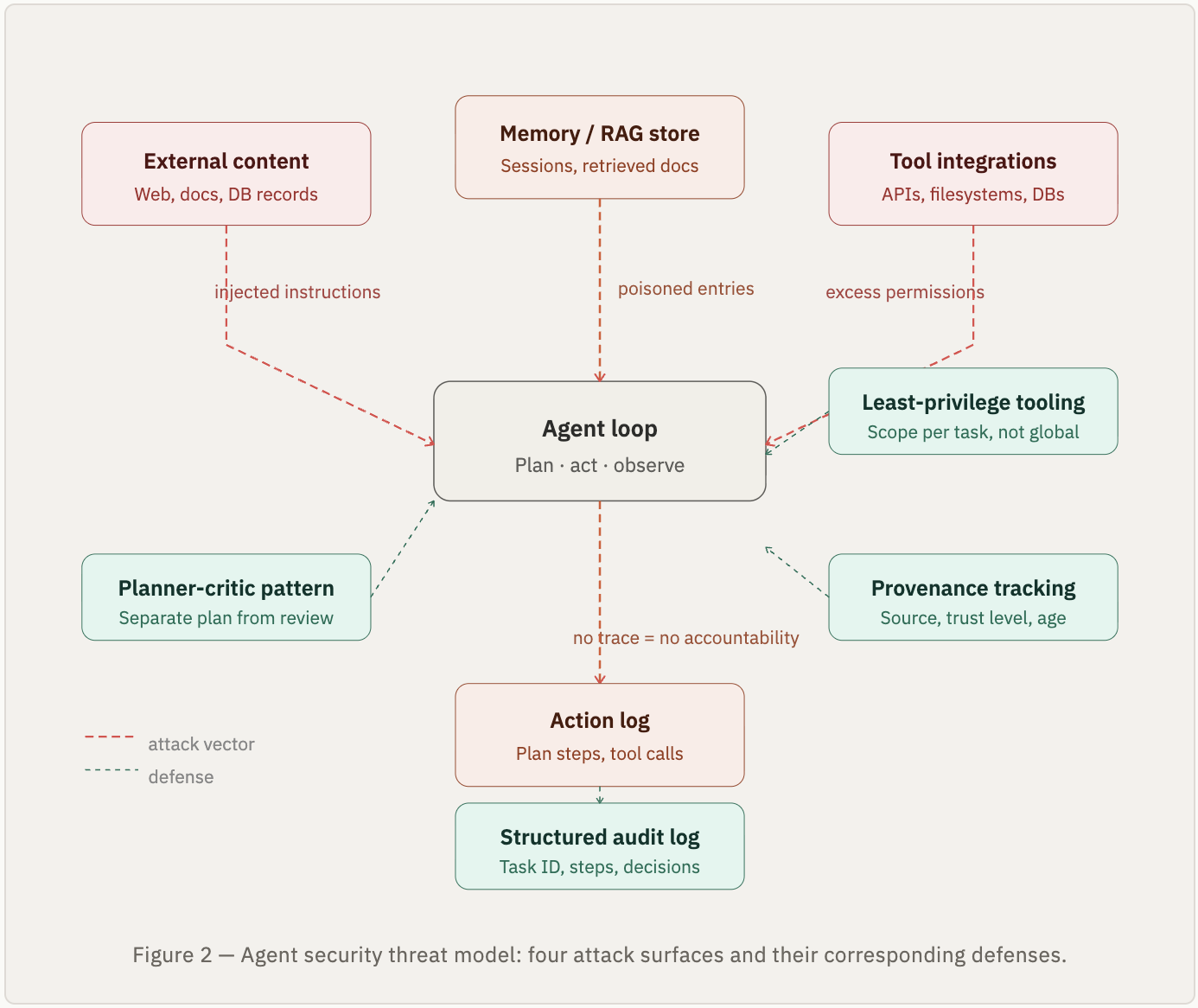
Security in agentic systems is a different problem from security in conventional services, and treating it the same way is how teams get surprised. In a standard API, the threat surface is the request: validate inputs, authenticate the caller, and authorize the operation. In an agentic system, the threat surface includes the model's reasoning itself. An attacker does not need to compromise your infrastructure; they need to get malicious instructions into the agent's context.
Blast radius and least-privilege tooling. The starting point is still familiar: an agent with access to a broad set of tools is an agent with a large blast radius. When the model hallucinates a tool argument, misinterprets a plan step, or simply makes a bad decision, the question is not whether it will cause damage; it is how much. Tool permissions should be scoped to the minimum required for the current task, not the broadest set the agent might ever need. File system access should be sandboxed to a working directory. API calls should route through a proxy that enforces per-operation rate limits and an explicit whitelist of allowed endpoints. Destructive operations (deletes, publishes, financial transactions) should sit behind a confirmation layer that requires either human approval or a verifiable precondition check before execution. Think of it as capability-based security applied to LLM tool use: the agent only gets the keys it needs for this specific task, not a master key to every integration.
Prompt injection. This is the attack class unique to agentic systems and the one most teams underestimate. Prompt injection occurs when malicious instructions are embedded in content the agent retrieves and processes as part of its task: a web page it scrapes, a document it reads, a database record it queries, a tool output it receives. The agent, unable to distinguish between its system instructions and injected instructions in retrieved content, may follow the injected ones. The consequences range from data exfiltration (the agent is instructed to summarize and send sensitive context to an external endpoint) to action hijacking (the agent is redirected to perform a destructive operation it was not asked to do). The 2025 incident, where a Replit coding agent deleted a production database after being given what looked like a cleanup instruction, is a concrete example of what action hijacking looks like in practice.
Defending against prompt injection requires treating all retrieved content as untrusted input, regardless of its source. The agent's system prompt and its task instructions should be structurally separated from retrieved content in the context, not just positionally. Tool outputs should be labeled as external data and processed through a filter layer before the model reasons over them. For high-risk operations, add a planner-critic pattern: one model pass to generate the action, a second pass that independently reviews the proposed action against the original task goal before execution. The critic's job is to catch the cases where the proposed action does not match what the user actually asked for.
Context as an attack surface. Following from the above, everything that enters the agent's context window is a potential injection vector. This includes system prompts (which can be leaked or overridden by sufficiently adversarial inputs), RAG-retrieved documents (which may contain embedded instructions), memory entries persisted from prior sessions (which may have been poisoned in an earlier interaction), and MCP tool responses (which are controlled by third-party servers). Each of these sources needs provenance tracking: where did this content come from, when was it retrieved, and what trust level does that source carry? A document retrieved from an internal, authenticated knowledge base warrants different handling than a web page fetched from an arbitrary URL.
Audit logging for agent actions. In a conventional system, you log requests and responses. In an agentic system, you need to log the full reasoning chain: what the agent was asked to do, what plan it generated, what tool calls it made, what it decided based on each tool's output, and what the final action was. This is not just for debugging; it is for accountability. When an agent takes an unexpected action in production, you need to reconstruct exactly why it did so. Structured audit logs keyed to a task ID, with every planning step and tool call captured, make that reconstruction possible. Without them, you are debugging a non-deterministic system with no trace.
Evals as Continuous Deployment
In a conventional service, you validate correctness with unit tests and integration tests. In an agentic system, correctness is probabilistic and contextual; the same task can succeed 90% of the time and fail 10% in ways that are difficult to anticipate. Static tests are necessary but not sufficient.
The analog here is chaos engineering and canary deploys. You maintain a suite of representative tasks, your eval harness, and you run it against every meaningful change to the system: model version upgrades, prompt changes, context engineering adjustments, and new tool integrations. The eval harness measures not just task success rate but step efficiency (did it complete in a reasonable number of steps?), cost per task, and regression against prior behavior on known-good cases.
This is CI/CD for non-deterministic systems. The bar is not "all tests pass"; it is "the distribution of outcomes is within acceptable bounds." Teams that skip this step discover regressions in production, often in the worst possible scenarios.
What To Build First
For teams moving from prototype to production, the investment priority is roughly:
- Structured tracing first. You cannot debug what you cannot observe. Instrument every LLM call and tool invocation before anything else. Cost attribution is a close second; you will be surprised by where tokens actually go.
- Token budgets and task termination. Define hard limits before you go live. An agent without a termination condition is a liability, not a feature.
- Tool call classification and idempotency. Audit every tool in your catalog for side effect profile. Add idempotency keys to writes before the first production task runs.
- Sandboxing. Scope permissions to the minimum for each task type. This is easier to do before you have a complex integration surface than after.
- Eval harness. Start small (five to ten representative tasks) and grow it with every incident. Treat eval regressions the same way you treat test failures in any other system.
Context compaction strategy can be layered in iteratively as you understand your actual context growth patterns from production traces.
Conclusion
The model is not the hard part. Given the pace of LLM improvement, the inference layer is increasingly a commodity. What will differentiate production-grade agentic systems from fragile demos is the engineering discipline applied above the model: how context is managed, how failures are contained, how behavior is observed and validated over time.
These are not new problems. Distributed systems engineers have been solving variants of them for decades. The vocabulary is different (context collapse instead of cache eviction, token budgets instead of backpressure, eval harness instead of canary deploy), but the underlying failure modes and the engineering responses to them are deeply familiar.
Build the harness like you would build any production-critical infrastructure layer. The model will take care of itself.
Disclaimer
The principles outlined here reflect general patterns for building reliable agentic systems. As with any architectural guidance, evaluate these recommendations against the specific constraints and requirements of your system. There is no universal playbook, only well-reasoned tradeoffs.
Opinions expressed by DZone contributors are their own.
Comments