Prompt Engineering Wasn't Enough; Context Engineering Is What Came Next
Expanded context windows enable a shift from prompt engineering to context engineering, i.e., optimizing what AI accesses rather than how we ask.
Join the DZone community and get the full member experience.
Join For FreeOver the last few years, the conversation around AI has slowly shifted from prompt engineering to something more structured and more powerful: context engineering.
When you are working on a chatbot that answers questions around a knowledge base or working on an agentic AI framework that is very complex, the way you architect context depends entirely on the problem you are solving. Simply put, context complexity scales with the task uncertainty. Simple, predictable tasks require minimal context structuring, while complex, multi-step tasks require sophisticated context orchestration.
What Is Context Engineering?
Context engineering is the art of providing all necessary context for tasks to be solved by language models. All of this is to help solve the single most important problem when dealing with language models: How can we make the LLM answer what we are looking for correctly by passing it the right information?
Understanding Context Engineering
Let us pick a couple of use cases and look at context engineering in a deeper fashion, and how it has evolved from prompt engineering.
Use Case 1: Current Event Summary
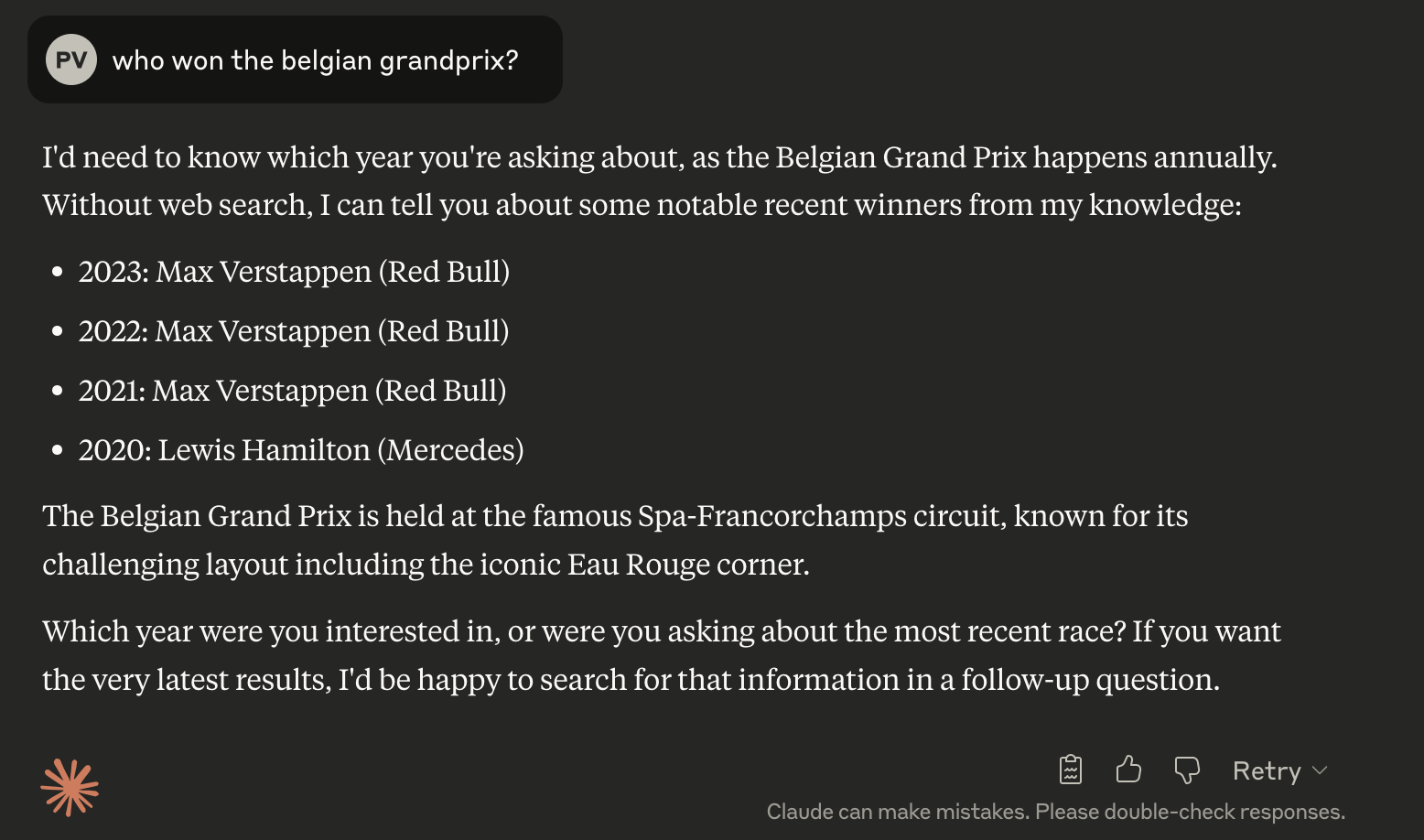
I asked the large language model Claude about the winner of the Belgian Grand Prix, but since it lacks sufficient context, it provided me with the winners from previous years. Now, let us enrich the model with some context and see what happens.
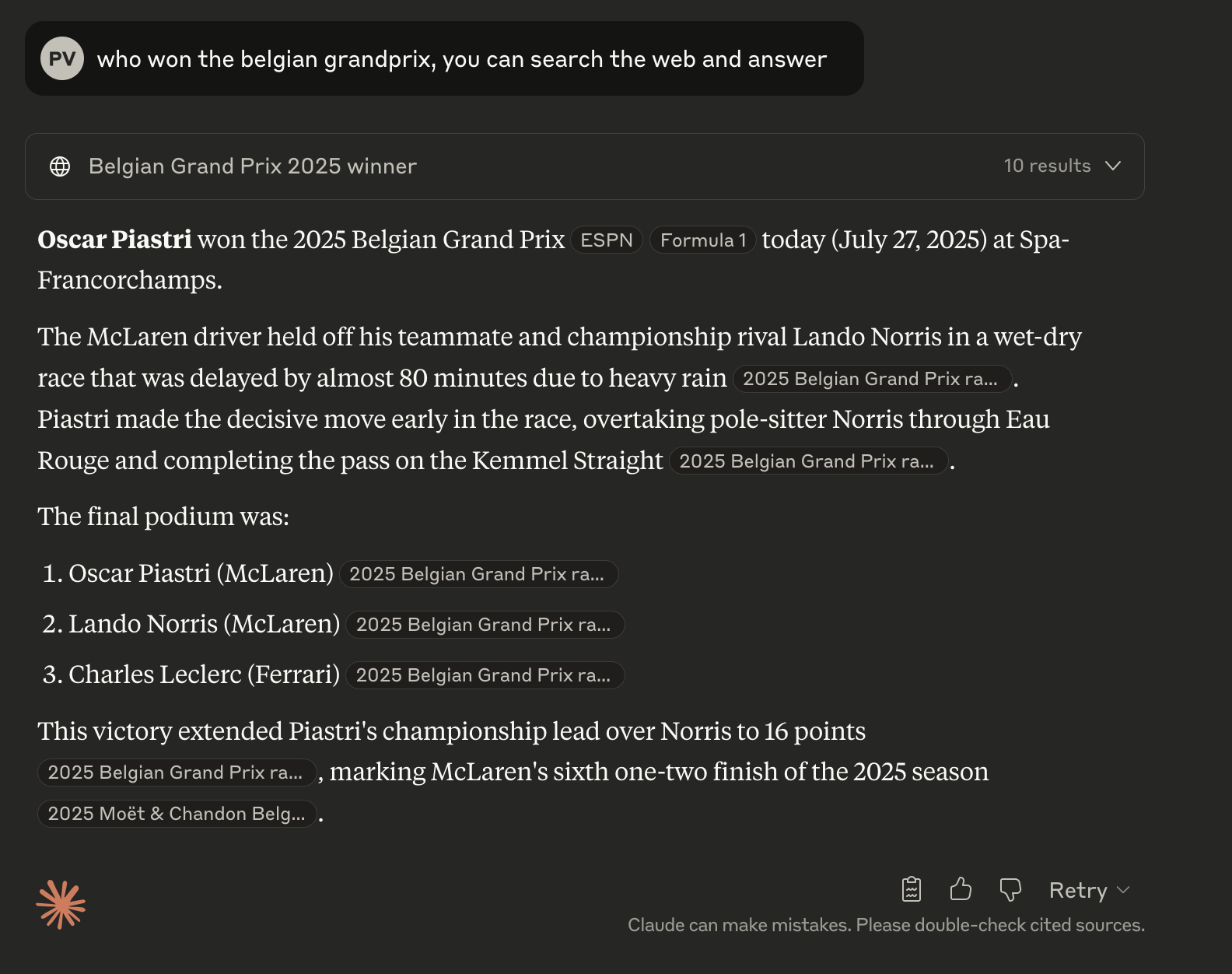
I have now provided the simplest bit of context needed to answer the question, which is to look at the web, and you can now see the answer I expect, which is the result of the Belgian Grand Prix, which happened today (the day of writing this article).
This is a simple way of context engineering to provide the right push to the LLM to enable it to answer the question accurately.
About a year ago, this would have been a copy-paste of context from the Formula 1 web page to let the LLM know who has won the Belgian Grand Prix.
Use Case 2: Access to Databases via an MCP Server
Now, let us look at a complex use case and how we are providing the context in this case. Let's say we have employee, customer, and sales data in a BigQuery database, and we have built an MCP server and integrated the server with Claude. We will now look at how the LLM will answer a more complex question without and with the context in mind.
Without the MCP Server Access

With the MCP Server Access
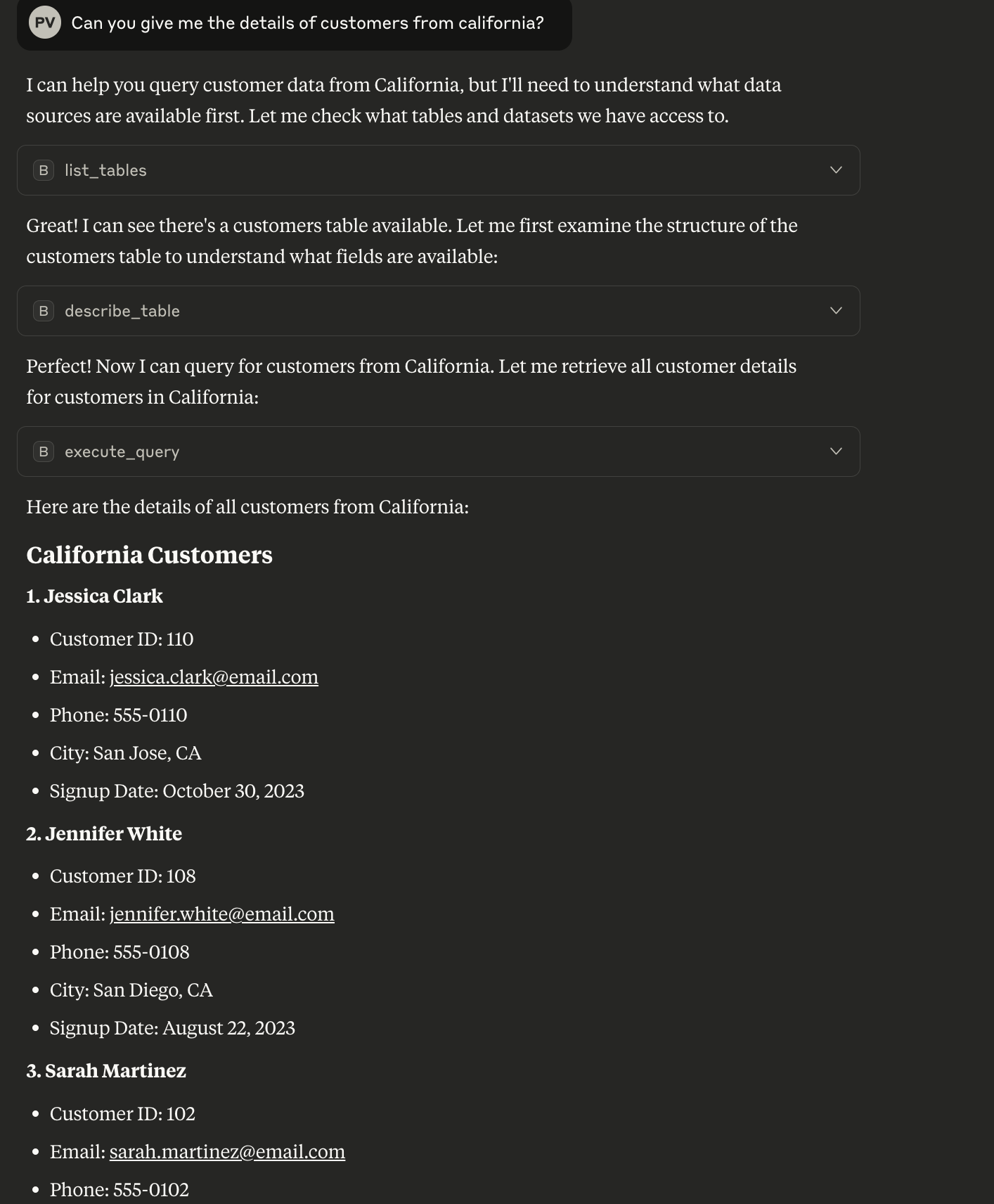
As you can see, the moment you give the LLM the context, it now has access to the BigQuery MCP server and has access to the customer data, and through that, it has now answered the question accurately. This is a more complex way of providing the context to the LLM, which involves writing a BigQuery MCP server and integrating that with the LLM.
As you can see with the two examples, prompt engineering, which was the art of providing context and instructions to the LLM, has now upgraded into context engineering. Instead of just providing a prompt, we can now provide the LLM web search capabilities, access to databases, and access to tools.
Please note that the LLM itself cannot access tools or access databases we enable that via applications (chatGPT is one such application... yes it is!), and all we do is provide the context back to the LLM to help answer our question.
We have now seen what context engineering is and how it changes based on the use case. Now, let us categorize the use cases and understand how context engineering varies.
Context Engineering Patterns by Use Case Category
Deterministic Use Cases
These use cases can be identified by the following characteristics:
- Predictable input patterns
- Consistent information requirements
- Measurable success criteria
As an example, let us take a traditional chatbot which perfectly demonstrates the simplest form of context engineering where the input scope is the customer questions within defined product categories, the information sources are a structured knowledge base with consistent formatting, and there is a steady and standard format of processing (Query --> Retrieve --> Format --> Respond). The only metrics we track are Answer accuracy and response time.
These kinds of use cases constrain context requirements. Limited variability means efficient and predictable context engineering.
Semi-Dynamic Use Cases
These use cases can be identified by the following characteristics:
- Multiple decision paths
- Conditional processing logic
- context-dependent outcomes
As an example, let us take a personalized learning platform which demonstrates a semi-dynamic context engineering case where the student's questions vary by skill level, learning style, and subject area, the information sources would be curriculum content, progress tracking, performance data and the processing pattern would look like (Assess --> Personalize --> Adapt --> Deliver). The metrics we track for success would be learning outcomes, engagement, and retention.
As the architecture becomes conditional, context engineering also starts to become dynamic in some cases. The use case here permits prediction but requires adaptation. Context decisions follow logical patterns but vary based on learner state.
Complex Use Cases
These use cases can be identified by the following characteristics:
- Multi-agent coordination
- Real-time context updates
- Cross-domain information synthesis
As an example, let us take autonomous business operations, which require complex context engineering. The use case showcases unpredictability as the business events occur across multiple domains simultaneously, the information is also complex as it comes from various systems, there will also be multi-agent coordination with conflicting priorities, and success will also be measured based on outcomes for various departments.
As you can clearly see, this use case prohibits prediction. Business events are fundamentally unpredictable, which makes the context engineering aspect very complex.
Factors Impacting the Context of Engineering Decisions
We have seen how context engineering changes based on the complexity of the use cases. Now, let us see how that can be applied when working on setting the context.
Context Scope Determination
Deterministic tasks require a narrow, focused context, and uncertain tasks need broader information access; hence, we can say that the information breadth scales with task uncertainty.
Simple decisions need context at a higher level, whereas complex reasoning requires a detailed background. Hence, we can say context depth matches decision complexity.
Scaling Context Engineering
Before you make the architectural decisions, analyze your use case for input predictability, information requirements, processing complexity, metrics, and scaling demands. Once you do this, your use case will fall into the categories we mentioned earlier, and then it is much easier to align context engineering to the use case characteristics. If there is high predictability, we can use static context with efficient retrieval; if there is medium variability, we can use conditional context with adaptive selection; and if there is high complexity, we will have to use orchestrated context with emergent coordination.
Conclusion
Context engineering represents a fundamental shift in AI system design. Success depends on recognizing that your use case determines your architecture. Simple tasks need a simple context. Complex goals demand sophisticated orchestration.
The organizations that master this use case-architecture alignment will build AI systems that truly serve their intended purposes. This is not about building impressive technology; it is about solving real problems with appropriate context engineering approaches.
Context engineering is becoming the new software architecture where your use case determines your path.
Opinions expressed by DZone contributors are their own.
Comments