Protecting PII in LLM Applications: A Complete Guide to Data Anonymization
One of the biggest concerns companies face when implementing Large Language Models (LLMs) is data privacy and protection.
Join the DZone community and get the full member experience.
Join For FreeOrganizations want to leverage the power of LLMs like GPT or PaLM to solve business problems, but they're rightfully hesitant about sending sensitive data—especially Personally Identifiable Information (PII)—over the internet to third-party hosted models.
This article explores a powerful mitigation technique using anonymization and de-anonymization to protect sensitive data while still enabling effective LLM usage in enterprise environments.
The Problem: Balancing Innovation With Privacy
Consider a law enforcement organization that receives numerous complaint documents containing sensitive information like names, addresses, credit card numbers, and social security numbers. When investigators need to quickly analyze these documents using LLMs, they face a critical dilemma:
- On-premise models: Secure but often lack the sophistication of cloud-hosted solutions
- Third-party hosted models: Powerful but require sending sensitive data externally
The solution lies in anonymizing data before sending it to external LLMs, then de-anonymizing the results to maintain data utility.
The Anonymization Solution Architecture
The process follows a three-step approach:
- Anonymize: Replace PII with dummy data before sending to the LLM
- Process: Allow the LLM to analyze the anonymized content
- De-anonymize: Convert the LLM's output back to real data
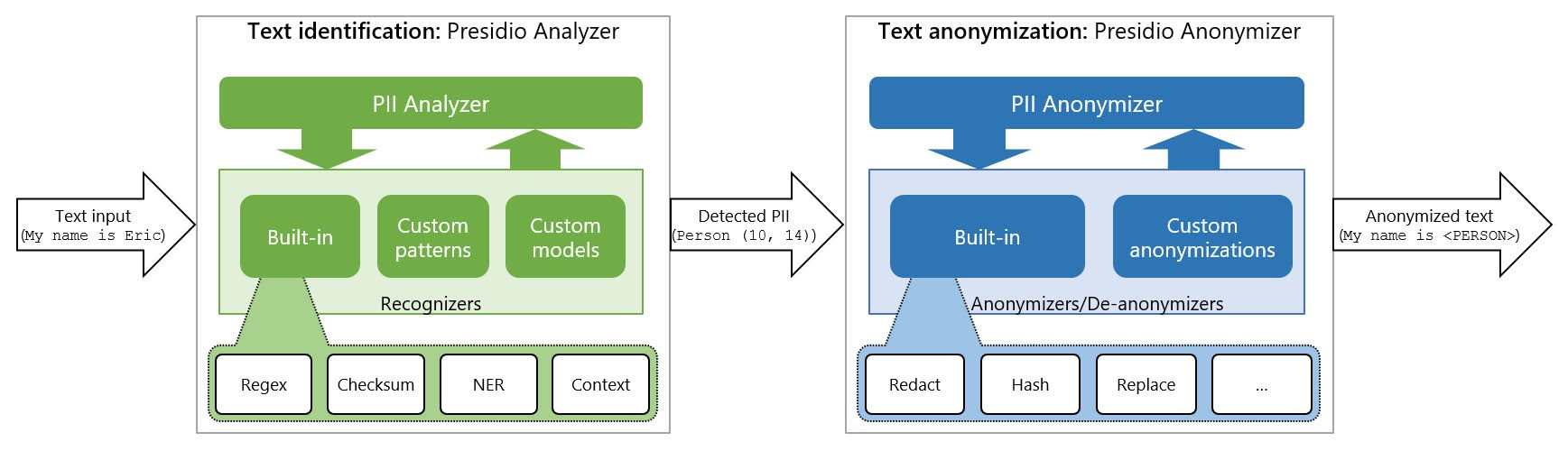
Technical Implementation
There are two types of operators:
- Anonymize (e.g., hash, replace, redact, encrypt, mask)
- Deanonymize (e.g., decrypt)
Required Libraries
# Core librariesimport langchain from langchain_experimental import * import openai import presidio_analyzer import presidio_anonymizer from faker import Faker import faiss
Step 1: Basic PII Detection and Masking
The Microsoft Presidio library serves as the foundation for PII detection:
from presidio_anonymizer import PresidioReversibleAnonymizer
# Initialize the anonymizer
anonymizer = PresidioReversibleAnonymizer(
faker_seed=42 # For reproducible fake data
)
# Anonymize the document
anonymized_doc = anonymizer.anonymize(original_document)
Presidio automatically detects common PII types including:
- Names and persons
- Dates and timestamps
- Locations
- Credit card numbers
- Bank account information
- Driver's license numbers
- Social Security Numbers
- Email addresses
Step 2: Custom PII Pattern Recognition
Organizations often have domain-specific sensitive data that standard tools don't recognize. Here's how to add custom patterns:
from presidio_analyzer import Pattern, PatternRecognizer
# Define custom patterns
polish_id_pattern = Pattern(
name="polish_id_pattern",
regex=r"\b[A-Z]{3}[0-9]{6}\b", # 3 letters + 6 digits
score=0.85
)
time_pattern = Pattern(
name="time_pattern",
regex=r"\b\d{1,2}:\d{2}\s?[AaPp][Mm]\b",
score=0.85
)
# Create recognizers
polish_recognizer = PatternRecognizer(
supported_entity="POLISH_ID",
patterns=[polish_id_pattern]
)
time_recognizer = PatternRecognizer(
supported_entity="TIME",
patterns=[time_pattern]
)
# Add recognizers to the anonymizer
anonymizer.add_recognizer(polish_recognizer)
anonymizer.add_recognizer(time_recognizer)
Step 3: Generating Realistic Fake Data
Instead of simple masking (like <PERSON>), generate realistic fake data for better LLM comprehension:
from faker import Faker
fake = Faker()
# Custom fake data generators
def fake_polish_id():
return f"{fake.random_letters(3).upper()}{fake.random_number(6, True)}"
def fake_time():
hour = fake.random_int(1, 12)
minute = fake.random_int(0, 59)
period = fake.random_element(['AM', 'PM'])
return f"{hour}:{minute:02d} {period}"
# Add operators to anonymizer
anonymizer.add_operators({
"POLISH_ID": fake_polish_id,
"TIME": fake_time
})
Step 4: RAG Implementation With Anonymized Data
Integrate anonymization into your RAG (Retrieval-Augmented Generation) pipeline:
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQA
# Anonymize documents before processing
anonymized_docs = [anonymizer.anonymize(doc) for doc in documents]
# Standard RAG pipeline with anonymized data
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=100
)
chunks = text_splitter.split_documents(anonymized_docs)
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(chunks, embeddings)
# Create retrieval chain
retriever = vectorstore.as_retriever()
Step 5: De-anonymization Chain
The critical final step is de-anonymizing the LLM's output:
from langchain.schema.runnable import RunnableLambda
# Create complete chain with de-anonymization
def create_anonymized_chain():
return (
{"question": RunnablePassthrough()}
| retriever
| prompt
| llm
| RunnableLambda(lambda output: anonymizer.deanonymize(output))
)
# Usage
chain = create_anonymized_chain()
result = chain.invoke("Where did the wallet theft occur and at what time?")
Real-World Example
import csv
import pprint
from typing import List, Iterable, Optional
from presidio_analyzer import BatchAnalyzerEngine, DictAnalyzerResult
from presidio_anonymizer import BatchAnonymizerEngine
"""
Example implementing a CSV analyzer
This example shows how to use the Presidio Analyzer and Anonymizer
to detect and anonymize PII in a CSV file.
It uses BatchAnalyzerEngine to analyze the CSV file and
BatchAnonymizerEngine to anonymize the requested columns.
Content of csv file:
id,name,city,comments
1,John,New York,called him yesterday to confirm he requested to call back in 2 days
2,Jill,Los Angeles,accepted the offer license number AC432223
3,Jack,Chicago,need to call him at phone number 212-555-5555
"""
class CSVAnalyzer(BatchAnalyzerEngine):
def analyze_csv(
self,
csv_full_path: str,
language: str,
keys_to_skip: Optional[List[str]] = None,
**kwargs,
) -> Iterable[DictAnalyzerResult]:
with open(csv_full_path, 'r') as csv_file:
csv_list = list(csv.reader(csv_file))
csv_dict = {header: list(map(str, values)) for header, *values in zip(*csv_list)}
analyzer_results = self.analyze_dict(csv_dict, language, keys_to_skip)
return list(analyzer_results)
if __name__ == "__main__":
analyzer = CSVAnalyzer()
analyzer_results = analyzer.analyze_csv(
'./csv_sample_data/sample_data.csv',
language="en"
)
pprint.pprint(analyzer_results)
anonymizer = BatchAnonymizerEngine()
anonymized_results = anonymizer.anonymize_dict(analyzer_results)
pprint.pprint(anonymized_results)
Benefits and Considerations
Advantages
- Privacy Protection: Sensitive data never leaves your organization in its original form
- Regulatory Compliance: Helps meet GDPR, HIPAA, and other privacy requirements
- Improved LLM Performance: Realistic fake data provides better context than simple masking
- Reversible Process: Complete mapping allows perfect reconstruction of original data
Limitations
- Processing Overhead: Additional computational steps increase latency
- Pattern Maintenance: Custom PII patterns require ongoing updates
- Complex Relationships: Some data relationships might be lost in translation
- Storage Requirements: Mapping tables must be securely stored
Best Practices
- Comprehensive Pattern Definition: Regularly audit and update PII detection patterns
- Secure Mapping Storage: Protect anonymization mappings with enterprise-grade security
- Testing and Validation: Thoroughly test custom patterns against real data samples
- Performance Monitoring: Track anonymization/de-anonymization performance impacts
- Compliance Documentation: Maintain detailed records for regulatory audits
Conclusion
Data anonymization provides a robust solution for organizations seeking to leverage powerful cloud-based LLMs without compromising data privacy. By implementing reversible anonymization with tools like Microsoft Presidio and Faker, companies can maintain the benefits of advanced AI capabilities while ensuring sensitive information remains protected.
The technique demonstrated here offers a practical pathway for enterprises to adopt LLM technologies responsibly, balancing innovation with essential privacy protections. As AI adoption continues to accelerate, such privacy-preserving techniques will become increasingly critical for sustainable and compliant AI implementations.
Next Steps
To implement this solution in your organization:
- Audit your data to identify all PII types and custom patterns
- Configure your development environment with the required dependencies and libraries
- Create comprehensive test cases with representative data
- Implement monitoring and logging for the anonymization pipeline
- Establish governance processes for pattern updates and maintenance
Opinions expressed by DZone contributors are their own.
Comments