Create Your Own Custom LLM: Essential Steps and Techniques
A step-by-step journey to create your custom LLM. Learn the science behind AI/ML language models — learning, refining, and alignment.
Join the DZone community and get the full member experience.
Join For FreeWe will start by defining the most fundamental building block of LLMs: Language modeling, which dates back to early statistical NLP methods in the 1980s and 1990s and was later popularized with the advent of neural networks in the early 2010s.
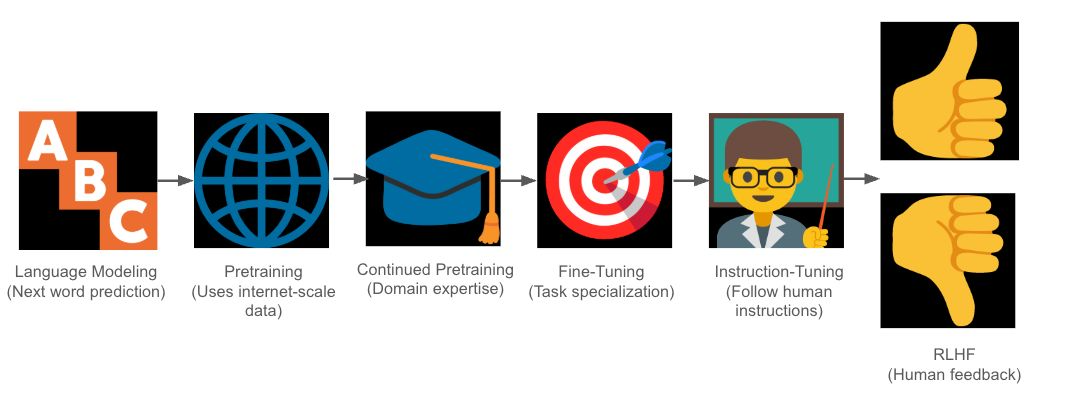
In its simplest form, language modeling is essentially about learning to predict the next word in a sentence. This task, known as next-word prediction, is at the core of how LLMs learn language patterns. The model accomplishes this by estimating the probability distribution over sequences of words, allowing it to predict the likelihood of any given next word based on the context provided by the preceding words.
Example: If you say: "The cat sat on the ___", the model assigns a probability to all words in its vocabulary and then chooses “mat” as it’s statistically the most common word to follow this phrase in its training data.
What Are the Steps Required for Building My Custom LLM?
1. Pretraining
Pretraining is the first big phase in any large-language model (LLM) building process. It uses language modeling (i.e., next word prediction) as its objective function. The model reads tons of billions of text from books, websites, and articles to learn grammar, facts, and basic reasoning without supervision, i.e., without any specific guidance or labels.
Pretraining effectively teaches the model how language works in general. This means that after pretraining, all the model knows is how to predict the next word given a sequence of words. This stage also involves the model learning general world knowledge, including facts, relationships between concepts, and syntax rules. While the model is not yet task-specific, this foundational knowledge is essential for all subsequent tasks. It cannot follow human instructions for any tasks of interest yet.
2. Continued Pretraining (CPT)
After the initial pretraining, sometimes we give the model extra reading material on a specific topic (like legal documents or medical journals). This helps the model become proficient in certain areas. Think of it as sending the model back to school for a subject-specific refresher. This continued pretraining refines the model’s knowledge, focusing it on a particular domain while still using the language modeling objective. Continued Pretraining also allows the model to handle specific jargon and technical language used in industries such as law, medicine, or engineering.
3. Fine-Tuning
Fine-tuning means training the model on a narrower dataset and polishing the model’s skills for a specific task. Unlike pretraining, which involves a broad and general dataset, fine-tuning involves a much more focused set of data relevant to the desired task.
Now the model is trained on examples of what we want it to do, like generating high-quality translations or creating concise summaries from long documents. The primary goal is to modify the weights of the model slightly so it becomes more specialized in a specific area while retaining its broad language understanding. Additionally, fine-tuning can involve multiple iterations of retraining, where the model’s performance is continuously monitored and adjusted to improve accuracy and usability for specific industries or tasks.
4. Instruction Tuning
Instruction tuning is a relatively recent development that was first introduced in 2021. Its main objective is to train models to better follow natural language instructions. In this phase, the model is exposed to a wide variety of tasks described in simple, natural language prompts. These tasks might include commands such as “Write an email”, “Translate this text”, or “Explain this concept to a 5th-grade student.” Instruction tuning teaches the model a general skill of understanding and responding to human requests, making it better at executing complex tasks in a natural and conversational manner. It enables LLMs to become more interactive and adaptable to different user needs.
Key Concepts in Instruction Tuning
- Prompt diversity: During instruction tuning, a wide variety of prompts with diverse phrasing are used. This diversity is essential because it prevents the model from being overfitted to one specific way of phrasing requests and helps it handle different forms of instructions it might encounter in the real world.
- Response generation: Instruction tuning enables the model to generate responses based on the understanding of the task, rather than relying on memorized answers. The model’s outputs are now influenced by the semantics of the task prompt, making it capable of handling complex instructions across different domains.
5. Reinforcement Learning via Human Feedback (RLHF)
Finally, the model undergoes RLHF to align its responses with human preferences and values, making it more helpful, honest, and harmless. This stage goes beyond accuracy — it directly addresses ethical concerns, bias mitigation, and safety risks by incorporating human preferences into the training loop.
During RLHF, the LLM generates several outputs, and human evaluators rank them from best to worst, which the model uses to learn what kinds of responses are preferred. This phase plays a critical role in making the model more socially responsible and ethically sound, as it helps ensure that the LLM produces not only accurate information but also answers that are respectful, fair, and in line with societal norms.
Summary
Each of these steps builds on the previous one in a step-by-step flow. By the end of this journey, the LLM has evolved from predicting basic words to a finely-tuned assistant that can follow instructions and provide answers aligned with human preferences. This layered training process is what enables modern LLMs (like ChatGPT) to be both knowledgeable and user-friendly!
Opinions expressed by DZone contributors are their own.
Comments