Engineering Smart Prefetch: Search With Foresight
Smart Prefetching anticipates user queries to prefetch results, reducing perceived latency and improving search responsiveness through adaptive, efficient prediction.
Join the DZone community and get the full member experience.
Join For FreeDo you remember the hype for that final season of Game of Thrones? This was the only time I streamed a new episode within minutes of it being released. Millions of others did the same after waiting months to learn the fate of Westeros. Now imagine how amazing the viewing experience would have been if, the moment you selected the episode, it played instantly in the highest quality.
How, though?
Sure, content delivery networks (CDNs) can optimize server-side streaming, but to offset network delays — which can be significant for high-quality video streaming — something more is needed for that magical experience.
One approach could be a platform that predicts what the user wants, fetches it from the server, and caches it locally. That way, if the user ends up choosing the prefetched item, it can be served in the blink of an eye.
And this, in a nutshell, is the idea behind Smart Prefetching: anticipate, optimize, and act. It's also the first of the three optimizations discussed in Instant Search Results.
Why Even Do It
A search landing page may pull data from a variety of backends, blending results from different sources. For example, on LinkedIn Search these backends can be profiles, posts, companies, and groups; on Reddit, they could be communities, posts, comments, and people.
Even with highly optimized backend systems, fetching results from so many sources can lead to noticeable delays — especially on slower networks.
And this is where Smart Prefetching comes in. By anticipating what a user is likely to search for as they begin typing, the system can fetch results before the user submits the query. This effectively hides search latency and network delays, making the search feel nearly instant. Prefetching doesn’t speed up the backend or improve the network — it simply optimizes when results are fetched.
However, while prefetching can boost perceived speed, it can also waste bandwidth, strain backends, and serve stale results — downsides that can outweigh the benefits if prefetching isn't done and tracked carefully.
When to Prefetch
The first challenge in Smart Prefetching is deciding when it makes sense to act. If we trigger too early, we risk wasting resources on results the user never requests. If we wait too long, we miss the window to reduce perceived latency.
One strong signal of intent is query length. Shorter queries containing only a few characters are often abandoned or are too ambiguous to predict accurately. We observed that the majority of completed search sessions occur when the query length is between 3 and 13 characters. This range becomes the sweet spot for prefetching.
Another useful control is a debounce period. Instead of firing off requests on every keystroke, the system waits for a short pause in typing — around 500 ms. This ensures we only prefetch when there’s a reasonable chance the user has landed on their intended query or is already looking at the typeahead suggestion.
Together, query length and debounce provide a simple but effective mechanism for deciding when to fetch results in advance.
Beyond static signals like query length and debounce time, prefetch timing can also be adaptive. A lightweight ML model can continuously tune prefetch behavior by considering runtime factors such as device type, OS, network speed, locale, and more. For instance, users on high-latency mobile networks may benefit from earlier or more aggressive prefetching, while desktop users on fast connections can rely on a more lenient approach. This adaptive method balances perceived responsiveness with resource efficiency.
What to Prefetch
Once we’ve decided the timing, the next question is what to prefetch. Here, the goal is not to cover every possible outcome but to maximize the likelihood of guessing the user's intended search with minimal overhead.
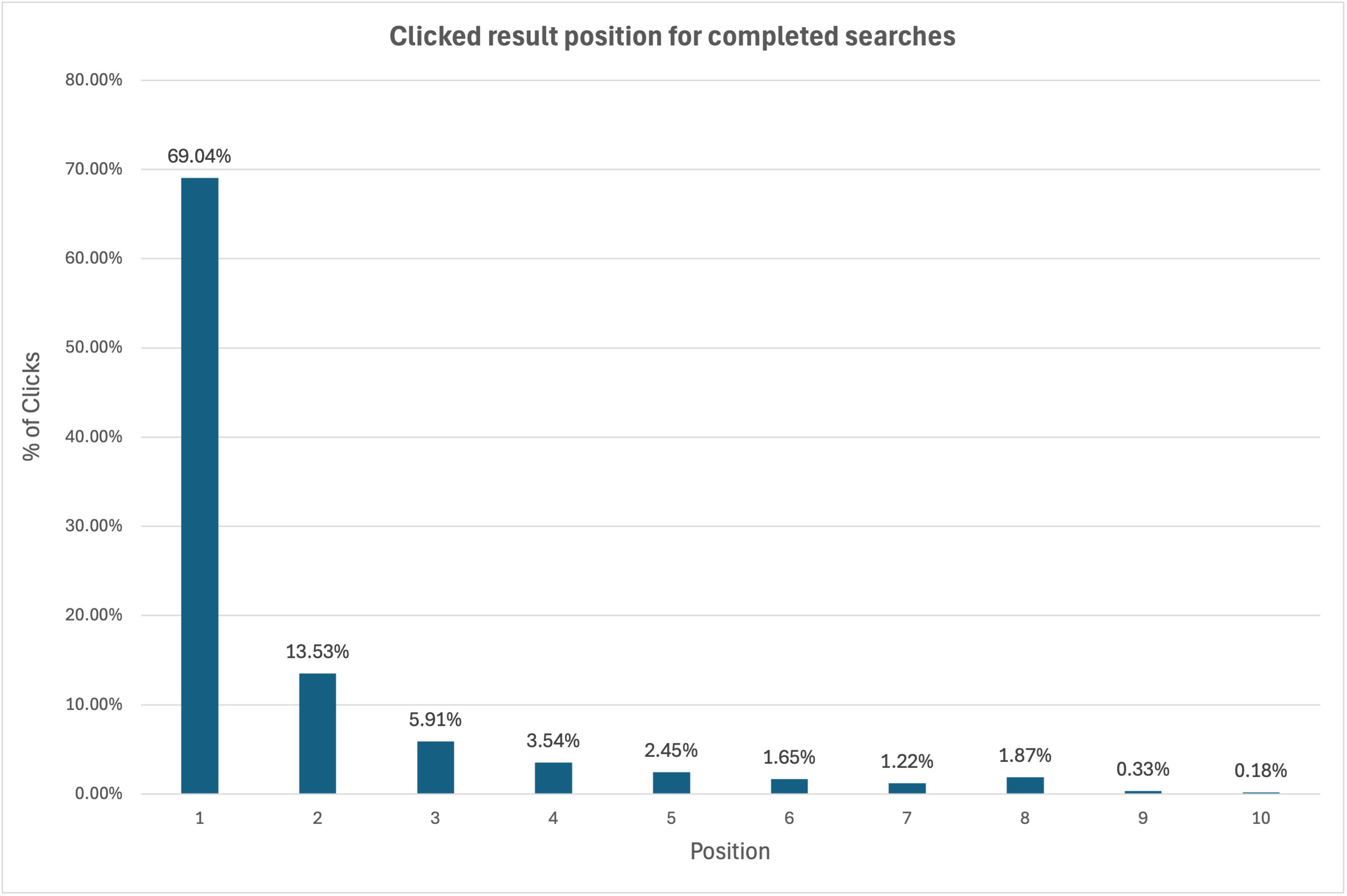
In our experiments, data showed that users are far more likely to click on the first suggestion in the typeahead dropdown than any other entry. This makes it the prime candidate for prefetching. At the same time, a significant share of users bypass suggestions entirely by hitting “Enter” to view full results.
To cover both behaviors, the system prefetches:
- Results for the first suggestion
- Results for the “See All” version of the typed query
This dual strategy ensures that, in most cases, the results the user actually wants are already cached and ready to be displayed instantly.
Finally, there’s the question of freshness. Prefetched results can go stale if the underlying data changes — such as new posts, updated ranking, or content modifications. To handle this, results are cached locally only for a brief period (e.g., 5 minutes) before being discarded.
By being selective about what to prefetch and keeping the cache window short, we balance speed, accuracy, and efficiency.
Takeaway
When a user's search intent is predicted accurately, the system can show cached prefetched results, drastically reducing perceived page load times.
However, doing so may increase QPS to backend services. Although improving prediction accuracy and tuning prefetch parameters can reduce cost-to-serve, prefetching always incurs some amount of wasted calls.
The key to effective prefetching is intensive tracking and data analysis, tailored to the needs and constraints of the search system.
What’s Next
In the next article in the Instant Search Series, we'll do a deep dive into Slow and Fast Call Orchestration, which enables rapidly fetching top results while the full search is still running in the backend.
Opinions expressed by DZone contributors are their own.
Comments